ARROW-8504: [C++] Add BitRunReader and use it in parquet #7143
Conversation
|
A fair chunk of RLE-related code came out of Impala originally, it might not be a bad idea to peek at what's in apache/impala to see if it has gotten worked on perf-wise since the beginning of 2016. In any case, we wouldn't want to take on a change that causes a perf regression in cases with many short null/non-null runs |
|
Agreed. I'm think I'll have to add a special case for this. The code can also be simplified a bit further for cases with runs |
|
@wesm interesting data point, I updated performance benchmarks to generate random values/nullability (and kept deterministic one). It seems like the bad regression is really only deterministically alternating nullability. Randomly generated nullability (at 50%) shows improvements. I still have some cleanup to do but I'd be curious on peoples thoughts on the need to try to detect/special case deterministic patterns in nullability (its possible the maybe I just chose a bad seed?): Also, https://github.com/apache/impala/blob/19a4d8fe794c9b17e69d6c65473f9a68084916bb/be/src/kudu/util/rle-encoding.h is the file I found int impala? Maybe we did all the additions for GetBatchSpaced etc? Was there another source you were thinking of? |

|
OK, any code cleanup I've tried to do seems to make performance worse. So I think the one remaining question is if I should try to special case alternating null/non-null values because the regression is bad. I think the run calculation is still more expense in some cases, but looks very bad when nulls follow a pattern the CPU branch predictor can get correct all the time. So the only way of special casing this is try to estimate when alternating values is happening and revert back to the old one at a time code path. I'm -0 on make such a special case because it isn't really clear to me how much this occurs in "real" data. I think another way of framing this is, if we had pseudo-random benchmark data to begin with would anybody notice the particularly bad performance? Would we try to special case this under that scenario? |
|
I agree that we shouldn't be basing the decision on the performance of random / worst-case scenario data. If the perf is better on "realistic" datasets (> 80/90% non-null data with consistent consecutive runs) then it doesn't seem like a bad idea to me. Bending over backwards for the special / "unrealistic" case also doesn't seem worthwhile |
|
@wesm OK, I did a little bit more in depth sampling. And it looks like this new algorithm is a win for 0-5% nulls, then a regression until someplace between 45-50% nulls then a likely a win with a larger percentage of nulls. I'll add a special case to estimate which algorithm to use (this one or 1 by 1 based on percentage of nulls and sampling the first N elements of the bitmap vector).
|

|
OK, I was actually able to make this faster with a little bit of refactoring. The only major regression is now the exact alternating case (~50% worse). I'll wait till #7175 is merged to publish new benchmarks, but I no longer think special casing is necessary. |
95873c1
to
64731c4
Compare
|
OK I think this is ready for review CC @pitrou @wesm Benchmarks show mostly 20% improvement for any random null values across the board. The worse case scenario shows 40-60% regression. This seems to occur when we have deterministically alternating null/not-null. I believe this to be because modern branch predictors can detect this pattern so there is minimal branch cost relative to the extra work that is happening inside of BitRunReader |
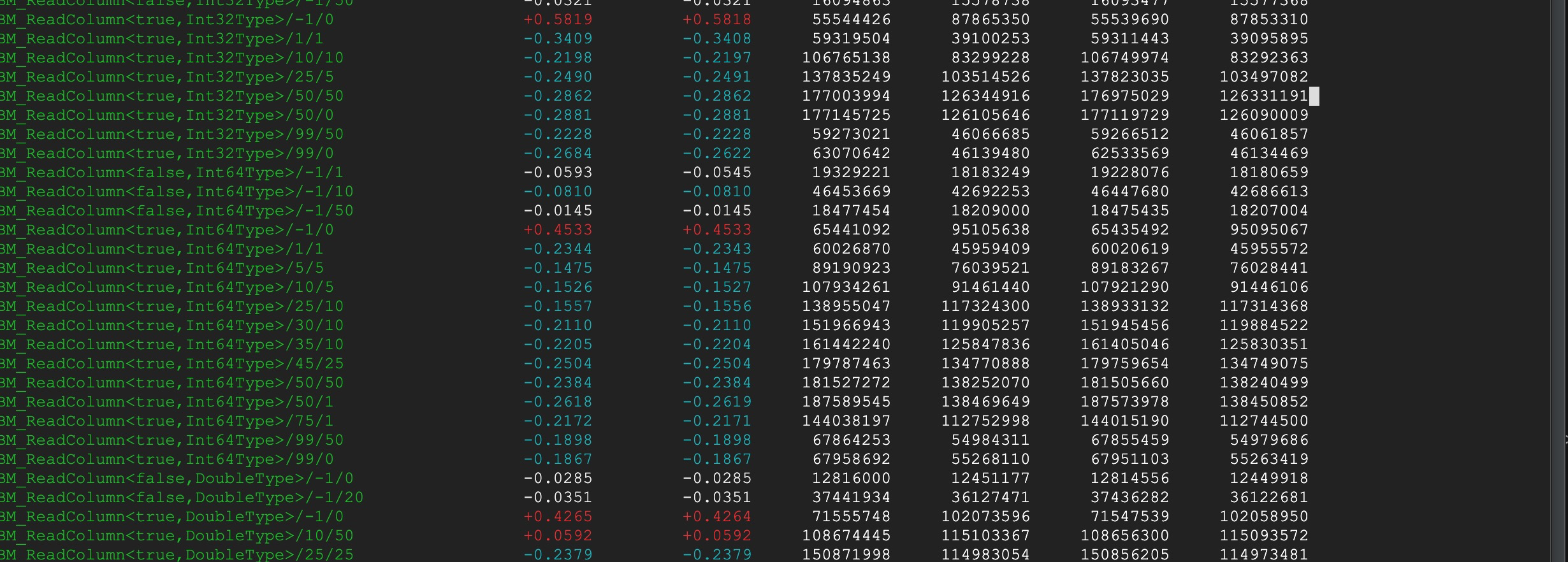
|
Cool, I will try to look at this tomorrow and kick the tires a bit with benchmarks |
|
Will fix CI issues tomorrow |
|
Need to look into the windows failures some more. |
|
I will review and do some perf tire-kicking in the meantime |
|
If this is not urgent, you can wait for next week and I'll review as well. As you prefer, of course :-) |
|
@pitrou yes, I can wait for you to code review, I will have a brief look and I'm mostly interested in trying it out on some datasets (such as the ones from https://ursalabs.org/blog/2019-10-columnar-perf/) |
|
I fan on the "Fannie Mae 2016 Q4" dataset from that blog post before after So there seems to be a perf improvement in single-threaded decoding but it seems that it's effectively bottlenecked on other issues in multithreaded decoding |
|
@emkornfield if it's OK I'm going to let @pitrou review this when he is back from vacation next week since he's better with these code paths |
|
No rush on review. The failures on windows are little concerning to me (i.e. there still might be a bug in the code). @wesm not sure if is is noise, but it looks like variance is reduced with the new code. Can you share the encodings/schema for the parquet file that you are running? Would it pay to check-in the file (or a sampled version) and write a c++ benchmark against it? |
|
Ah, I will try to look next week on my machine with AVX512 |
|
It should be a performance win on SSE4 or AVX as long as the data isn't nested. |
|
BitRunReader benchmark here (with gcc 7.5): |
There was a problem hiding this comment.
Ok, I find the implementation quite convoluted. I would like to see the following changes:
- Make all critical functions inline
- Load a single byte at a time (it probably doesn't bring much to process an entire 64-bit word at a time, and it adds complication)
- Try to simplify mask handling
cpp/src/arrow/util/bit_util.cc
Outdated
|
|
||
| void BitRunReader::LoadWord() { | ||
| word_ = 0; | ||
| // On the initial load if there is an offset we need to account for this when |
There was a problem hiding this comment.
Ok, why don't you have a separate function for the initial load? You're paying the price for this on every subsequent load (especially as the function may not be inlined at all).
There was a problem hiding this comment.
Changing to have a separate function. This is intentionally not inlined as part of the main loop (it was a performance improvement to move AdvanceTillChange out-of-line.
cpp/src/arrow/util/bit_util.h
Outdated
| int64_t new_bits = BitUtil::CountTrailingZeros(word_) - (start_position % 64); | ||
| position_ += new_bits; | ||
|
|
||
| if (ARROW_PREDICT_FALSE(position_ % 64 == 0) && |
There was a problem hiding this comment.
Be aware that signed modulo is slightly slower than unsigned modulo (the compiler doesn't know that position_ is positive).
There was a problem hiding this comment.
You could instead maintain a bit offset and/or a word mask. Could also perhaps help deconvolute InvertRemainingBits...
There was a problem hiding this comment.
Thanks for the tip. changing to position_ & 63. Antoine, I'm not sure what you are thinking for maintaining a bitmask could you provide some more details?
cpp/src/arrow/util/bit_util.h
Outdated
| ARROW_PREDICT_TRUE(position_ < length_)) { | ||
| // Continue extending position while we can advance an entire word. | ||
| // (updates position_ accordingly). | ||
| AdvanceTillChange(); |
There was a problem hiding this comment.
If you folded AdvanceTillChange() here, the code would probably be more readable (less duplicated conditions).
There was a problem hiding this comment.
By folded do you mean inline? This make a significant performance hit on parquet benchmarks. I added a comment.
cpp/src/arrow/util/bit_util.h
Outdated
| private: | ||
| void AdvanceTillChange(); | ||
| void InvertRemainingBits() { | ||
| // Mask applied everying above the lowest bit. |
There was a problem hiding this comment.
tried to clarify.
|
@pitrou thank you for the review. Comments inline.
If this is AdvanceTillWord, this hurts performance. LoadInitialWord in the constructor can be done but I don't think it will have a large impact on performance.
I'm not sure I understand what direction you would like me to take here. I would expect word level handling to be much faster for cases this is intended for (when there are actual runs). In practice, once integrated into a system you are likely correct though. But I'm not sure exactly what algorithm you are thinking of for byte level handling. If you provide more description I can try to implement it and compare.
Is this mostly InvertRemainingBits? could you provide some more feedback on the algorithm structure you were thinking of? |
@wesm I think if you can take a look and potentially revise the benchmarks at to make sure we are aligned on what we are trying to improve, I can update the this PR accordingly. I think there are really two options:
The way to go really depends on what percentage of values we expect to be null. My intuition is that very high rates and very low rates are likely, but I think you probably have a better intuition as to the exact definition of high or low. |
|
@emkornfield I can take a look at this once #7356 is merged which adds a single-word function to |
|
@emkornfield I'm sorry that I've been neglecting this PR. I will try to rebase this and investigate the perf questions a little bit |
|
I rebased. I'm going to look at the benchmarks locally and then probably merge this so further performance work (including comparing with BitBlockCounter) can be pursued as follow up |
|
Here's what I see with gcc-8: I agree that the alternating NA/not-NA is pretty pathological so IMHO this performance regression doesn't seem like a big deal to me. |
|
Here's with clang, even less of an issue there it seems |
|
I'm not sure what the MSVC failure is about but I'll debug locally |
|
I'm able to reproduce the error in VS and set breakpoints, I got this far to see that GetBatchWithDictSpaced has decoded more values than it was asked to
|
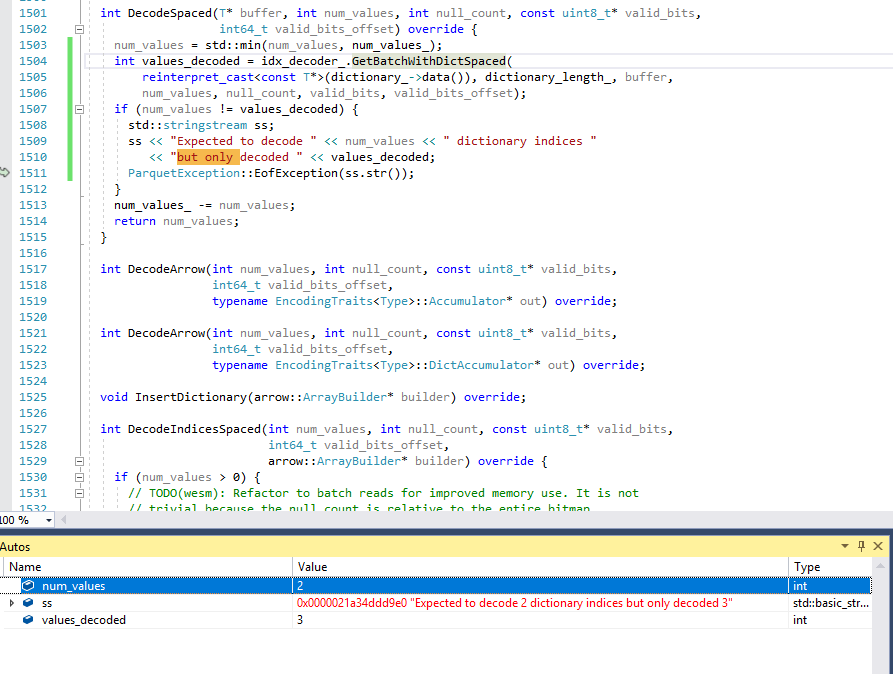
|
there seems to be a situation where the bit run has more values then are needed to fulfill the call to
|
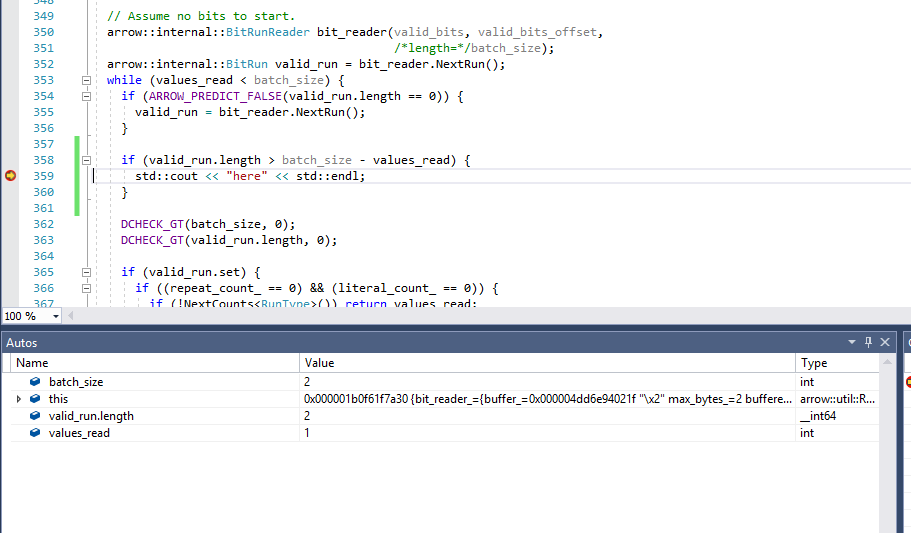
|
@emkornfield I'm sort of at a dead end here, hopefully the above gives you some clues about where there might be a problem |
|
The bug seems to be in the BitRunReader
|

|
Thanks, I'll take a look tonight. Hopefully this should be enough of a clue. |
and number of bits in a row. Adds benchmarks comparing the two implementations under different distributions. - Makes use of Adds the BitRunReader for use in Parquet Writing - Refactors GetBatchedSpaced and GetBatchedSpacedWithDict: Use a single templated method that adds a template parameter that the code can share. Does all checking for out of bounds indices in one go instead of on each pass through th literal (this is a slight behavior change as the index returned will be different). Makes use of the BitRunReader. With exactly alternating bits this shows a big performance drop, but is generally positive across any random and/or skewered nullability. fix type cast to make appveyor happy add predict false one more cast for windows remove redundant using try to fix builds address some comments inline all methods remove InvertRemainingBits and use LeastSignificantBitMask (renamed from PartialWordMask) remove LoadInitialWord, fix compile error fix lint Pre-rebase work iwyu Fix MSVC warning
|
I fixed the bug and some other issues. I also incorporated BitBlockCounter in rle_encoder.h. Latest benchmarks.
|

|
This is with SSE4_2 |
|
Travis CI seems flaky. My branch: https://travis-ci.org/github/emkornfield/arrow/builds/701926099 |
|
FWIW gcc benchmarks (sse4.2) on my machine (ubuntu 18.04 on i9-9960X) Here's clang-11 |
|
+1, thanks for fixing this @emkornfield! |
Adds two implementations of a BitRunReader, which returns set/not-set
and number of bits in a row.
- Adds benchmarks comparing the two implementations under different
distributions.
- Adds the reader for use ParquetWriter (there is a second
location on Nullable terminal node that I left unchanged because
it showed a performance drop of 30%, I think this is due the issue
described in the next bullet point, or because BitVisitor is getting
vectorized to something more efficient).
- Refactors GetBatchedSpaced and GetBatchedSpacedWithDict:
1. Use a single templated method that adds a template parameter
that the code can share.
2. Does all checking for out of bounds indices in one go instead
of on each pass through th literal (this is a slight behavior
change as the index returned will be different).
3. Makes use of the BitRunReader.
Based on bechmarks BM_ColumnRead this seems to make performance worse by
50-80%. This was surprising to me and my current working theory is
that the nullable benchmarks present the worse case scenario every
other element is null and therefore the overhead of invoking the call
relative to the existing code is high (using perf calls to NextRun()
jump to top after this change). Before making a decision on reverting
the use of BitRunReader here I'd like to implement a more comprehensive
set of benchmarks to test this hypothesis.
Other TODOs
- [x] Need to revert change to testing submodule hash
- [x] Add attribution to wikipedia for InvertRemainingBits
- [x] Fix some unintelligible comments.
- [x] Resolve performance issues.
Closes apache#7143 from emkornfield/ARROW-8504
Authored-by: Micah Kornfield <emkornfield@gmail.com>
Signed-off-by: Wes McKinney <wesm@apache.org>
Adds two implementations of a BitRunReader, which returns set/not-set
and number of bits in a row.
Adds benchmarks comparing the two implementations under different
distributions.
Adds the reader for use ParquetWriter (there is a second
location on Nullable terminal node that I left unchanged because
it showed a performance drop of 30%, I think this is due the issue
described in the next bullet point, or because BitVisitor is getting
vectorized to something more efficient).
Refactors GetBatchedSpaced and GetBatchedSpacedWithDict:
that the code can share.
of on each pass through th literal (this is a slight behavior
change as the index returned will be different).
Based on bechmarks BM_ColumnRead this seems to make performance worse by
50-80%. This was surprising to me and my current working theory is
that the nullable benchmarks present the worse case scenario every
other element is null and therefore the overhead of invoking the call
relative to the existing code is high (using perf calls to NextRun()
jump to top after this change). Before making a decision on reverting
the use of BitRunReader here I'd like to implement a more comprehensive
set of benchmarks to test this hypothesis.
Other TODOs