ARROW-9133: [C++] Add utf8_upper and utf8_lower #7449
Conversation
|
Yes, CRTP is certainly fine. We'll need to make utf8proc a proper toolchain library, @pitrou should be able to help you with that. |
I can take care of that! |
|
It's not that slow, it was 40% of Vaex' performance (single threaded), so I think there is a bit more to be gained still. But I have added an optimization that tries ASCII conversion first. This gives it a 7x (compared to Vaex) to 10x speedup (in the benchmarks). Before: After: There is one loose end, the growth of the string can cause a utf8 array to be promoted to a large_utf8. |
| // codepoint. This guaranteed by non-overlap design of the unicode standard. (see | ||
| // section 2.5 of Unicode Standard Core Specification v13.0) | ||
|
|
||
| uint8_t ascii_tolower(uint8_t utf8_code_unit) { |
There was a problem hiding this comment.
I think you will want this to be static inline (not sure all compilers will inline it otherwise)
| @@ -159,11 +282,23 @@ void MakeUnaryStringBatchKernel(std::string name, ArrayKernelExec exec, | |||
| DCHECK_OK(registry->AddFunction(std::move(func))); | |||
| } | |||
|
|
|||
| template <template <typename> typename Transformer> | |||
There was a problem hiding this comment.
I think some compilers demand that "class" be used for the last "typename"
|
I went ahead and asked ufal/unilib#2 |
|
The major difference between |
|
I used valgrind/callgrind to see how where time spent: I wanted to compare that to unilib, but all calls get inlined directly (making that not visible). Using unilib, it's almost 3x faster now compared to utf8proc (disabling the fast ascii path, so it should be compared to the items_per_second =5M/s above): This is about 2x faster compared to Vaex (again, ignoring the fast ascii path). The fact that utf8proc is not inline-able (4 calls per codepoint) will explain part of the overhead already. As an experiment, I make sure the calls to unicode's encode/append are not inlined, and that brings back the performance to: Confirming call overhead plays a role. Also, utf8proc contains information we don't care about (such as which direction text goes), explaining probably why utf8proc is bigger (300kb vs 120kb compiled). |
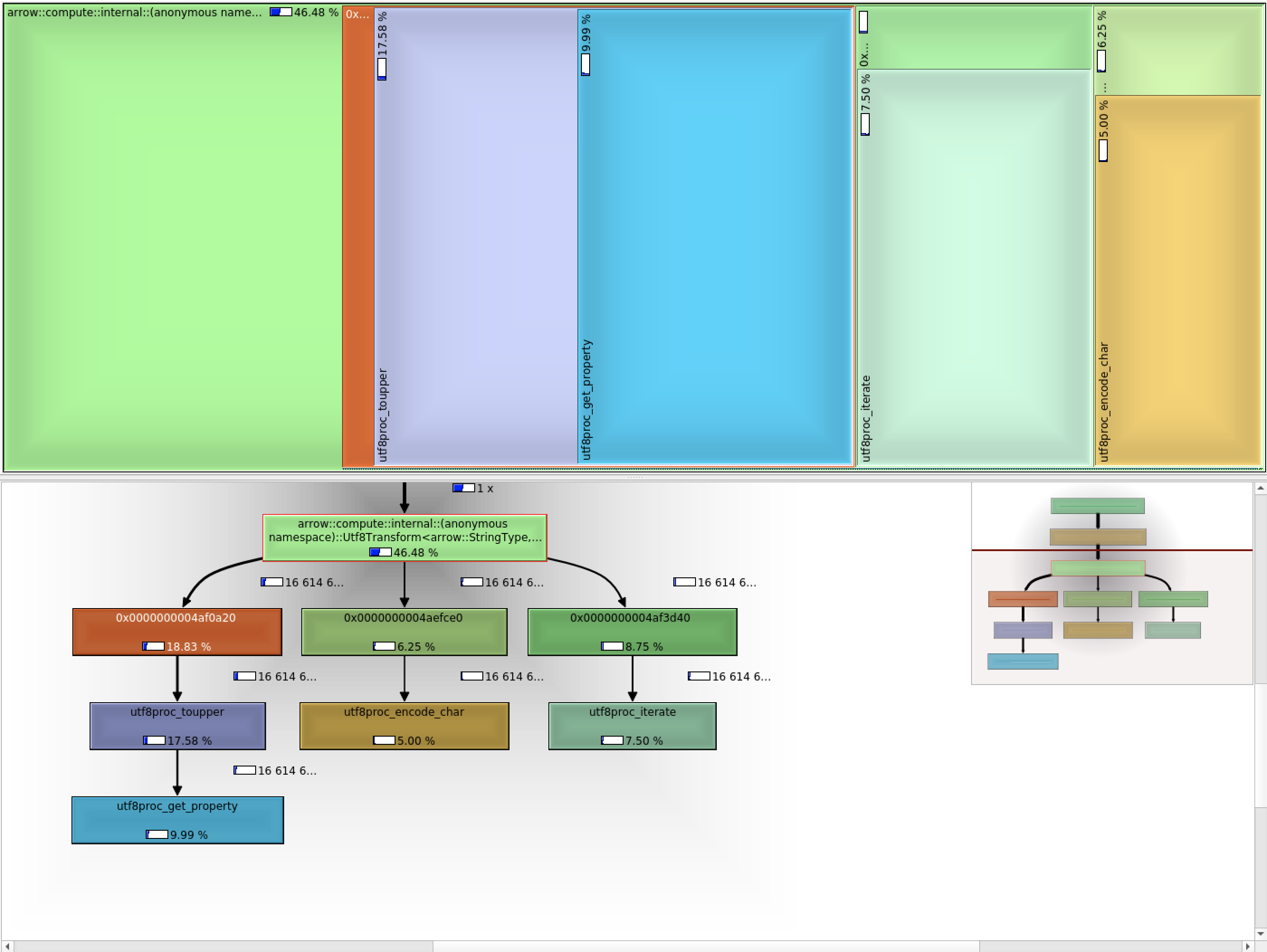
|
I don't know how important it is to get good performance on non-ASCII data. Note that the ASCII fast path could well be applied to subsets of the array. |
|
Also crossreferenced this in JuliaStrings/utf8proc#12 to make the |
|
Since the Unilib developer isn't interested in changing the license I think our effort would be better invested in optimizing utf8proc (if this can be Demonstrated to be worthwhile in realistic workloads, not just benchmarks) |
|
Would a lookup table in the order of 256kb (generated at runtime, not in the binary) per case mapping be acceptable for Arrow? |
|
Let's step back a bit: why do we care about micro-optimizing this? |
|
I want to move Vaex from using its own string functions to using Arrow. If I make all functions at least faster, I'm more than happy to scrap my own code. I don't like to see a regression by moving to using Arrow kernels. I don't call a factor of 3x micro optimizing though :) |
|
I think it would be more acceptable to inline the relevant utf8proc functions. |
I would find that acceptable if the mapping is only generated if needed (thus you will have a one-off payment when using a UTF8-kernel). I would though prefer if |
|
I also agree with inlining the utf8proc functions until utf8proc can be patched to have better performance. I doubt that these optimizations will meaningfully impact the macroperformance of applications |
|
@ursabot build |
|
Added |
884dcc0
to
157114d
Compare
|
I've added my own utf encode/decode for now. With lookup tables I now get: which is faster than the 'ascii' version implemented previously (that got Benchmark results vary a lot between Using utf8proc's encode/decode (inlined), this goes down to |
|
I just merged my changes for the ASCII kernels making those work on sliced arrays |
b5b40ea
to
17a506f
Compare
|
Note that the unitests should fail, the PR isn't done, but the tests seem to run 👍 |
I'd like to treat in-kernel type promotions as an anti-pattern in general. If there is the possibility of overflowing the capacity of a StringArray, then it would be better to do the type promotion (if that is really what is desired) prior to choosing and invoking a kernel (so you would promote to LARGE_STRING and then use the large_utf8 kernel variant). A better and more efficient strategy would be to break the array into pieces with |
There are upsides and downsides to it. The downside is that users of the Arrow library are exposed to the implementation details of how each kernel can grow the resulting array. I see this being quite a burden in vaex, to keep track of which kernel does what, and when to promote. Vaex does something similar, slicing the array's in smaller chunks, but still, it would need to check the sizes, no matter how small the slices are. Maybe it's best to keep this PR simple first (so give an error?), and discuss the behavior of string growth on the mailing list? |
I'm not saying that. I'm proposing instead a layered implementation approach. You will still write "utf8_lower(x)" in Python but the execution layer will decide when it's appropriate to split inputs or do type promotion. So Vaex shouldn't have to deal with these details. |
17a506f
to
e074d14
Compare
|
Main point remaining is whether we raise an error on invalid UTF8 input. I see no reason not to (an Arrow string array has to be valid UTF8 as per the spec, just like a Python unicode string cannot contain characters outside of the unicode code range). |
| KERNEL_RETURN_IF_ERROR( | ||
| ctx, | ||
| output->buffers[2]->CopySlice(0, output_ncodeunits).Value(&output->buffers[2])); | ||
| ctx, values_buffer->Resize(output_ncodeunits, /*shrink_to_fit=*/true)); |
There was a problem hiding this comment.
Nice way to make code more readable.
|
@pitrou your size commit made the benchmark go from
Yes, it would be interesting to see how the two methods deals with a 25/25/25/25% mix of 1-2-3 or 4 byte encoded codepoints, vs say a few % non-ascii. |
|
I pushed a commit that raises an error on invalid UTF8. It does not seem to make the benchmarks slower. |
|
I just concluded the same :) |
|
@xhochy Could you help on the utf8proc issue on RTools 3.5? It seems that |
This means there also needs to be a PKGBUILD submitted to
Just a reminder that nothing in the R bindings touches these new functions, so turning off utf8proc in the C++ build is also an option for now. |
Why? |
The version installed is compiled with gcc 8. RTools 35 uses gcc 4.9. Most of our deps have to be compiled for both, and this is apparently one of those. That's what https://github.com/r-windows/rtools-backports is for. |
What difference does it make? This is plain C. |
|
Indeed, toolchain incompatibilities only affect C++ code |
🤷 then I'll leave it to you to sort out as this is beyond my knowledge. In the past, undefined symbols error + only compiled for rtools-packages (gcc8) = you need to get it built with rtools-backports too. Maybe something's off with the lib that was built, IDK if anyone has verified that it works. |
|
Phew. It worked. RTools 4.0 is still broken, but there doesn't seem to be anything we can do, except perhaps disable that job. I'm gonna merge and leave the R cleanup to someone else. |
|
thanks @maartenbreddels! |
|
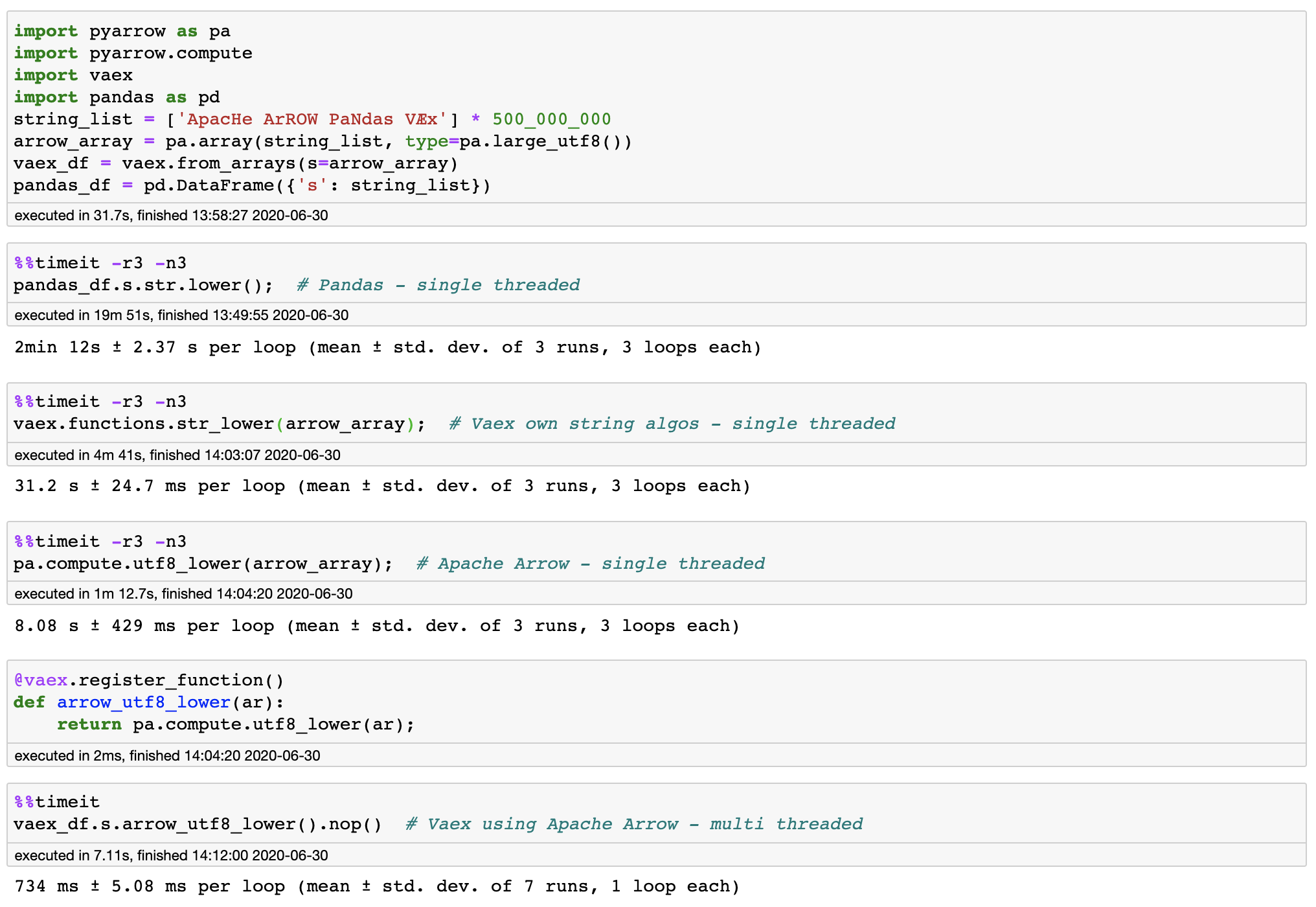
You're welcome. Thanks all for your help. Impressed by the project, setup (CI/CMake), and people, and happy with the results:
|
This is the initial working version, which is *very* slow though (>100x slower than the ascii versions). It also required libutf8proc to be present. Please let me know if the general code style etc is ok. I'm using CRTP here, judging from the metaprogramming seen in the rest of the code base, I guess that's fine. Closes apache#7449 from maartenbreddels/ARROW-9133 Lead-authored-by: Maarten A. Breddels <maartenbreddels@gmail.com> Co-authored-by: Antoine Pitrou <antoine@python.org> Co-authored-by: Uwe L. Korn <uwe.korn@quantco.com> Signed-off-by: Antoine Pitrou <antoine@python.org>
This is the initial working version, which is very slow though (>100x slower than the ascii versions). It also required libutf8proc to be present.
Please let me know if the general code style etc is ok. I'm using CRTP here, judging from the metaprogramming seen in the rest of the code base, I guess that's fine.