[BEAM-9308] Decorrelate state cleanup timers #10852
Conversation
9c0465c
to
eee2b65
Compare
|
The precommit failures seem unrelated to this, one is |
eee2b65
to
b75b7d6
Compare
|
cc @reuvenlax maybe? |
|
As written, this is incorrect. We currently rely on the state cleanup timer for watermark holds. This PR will cause that hold to be pushed later, which can cause incorrect grouping for any downstream aggregations. This is something we might be able to address by using the new outputTimestamp. This requires some thought though. Delaying the timer will also prevent downstream aggregations from firing. 3 minutes could cause issues if the window itself is much smaller. We want to reuse this timer for OnWindowExpiration, and this will delay all those callbacks as well. I wonder if it would be better to first root cause why the GC timers caused issues for your pipeline. One possibility: I believe that today any timers for a key are always prioritized over any data for that key. Maybe we need a better prioritization strategy so that large #s of timers don't starve out elements? |
|
Yay thanks for looking at this. I'll address your points in reverse order :P
I think that'd be the best overall option, but ideally we'd have variable priority. ie, state cleanup timers should be low priority, while user timers should be the same priority as "normal" elements. In the end though, if we end up with state cleanup timers delayed by N minutes because they are deprioritized, that seems like we'd be in the same spot as explicitly decorrelating them here.
Agreed, I sort of touched on this on my comment about letting the duration be configurable. Ideally it'd be some fraction of the window duration itself. I'm not sure it actually will delay the downstream aggregations from firing however, since the firing time it set to after the window closes (maxTimestamp + allowedLateness + 1ms), so once these begin firing, the watermark has already passed the end of the window. Or am I misunderstanding something here?
I'd actually argue that's preferable, since you'd have the same problem there was well (potentially millions of timers firing at the same time).
Is this true? The state cleanup timer is already set past the end of the window, so by the time the timer fires the window has already closed. |
|
Why is this problem specific to the GC timer? How about the normal end-of-window timer that is used to fire windowed aggregations. For fixed windows there is one per key and those also fire all at the same time. |
heh, we already work around that on our own by using state + timers instead of the built-in combine transform. We already decorrelate our end-of-window triggering (and we're now using the watermark hold feature for timers which simplified things a lot), but can't work around the state GC w/o changing the worker itself. |
|
I'm trying to think of a principled way to do this - maybe we need to explore the prioritization issue a bit more. Is this. a blocker for. you? If so then. maybe we can add a parameter to DataflowPipelineOptions to control this so we don't take the risk of changing the default behavior without more data. |
Agreed, I think ideally the state cleanup timers would have a (much?) lower priority than everything else so they don't starve out more important "user" work.
We run our own fork of the anyways, so it's not particularly a blocker here. I mostly just intended this PR as a conversation starter. I am curious about your comment above though ("We currently rely on the state cleanup timer for watermark holds"). From what I've observed in the code, the state cleanup is set for after the window end, so delaying it slightly more shouldn't cause any correctness issues, correct? |
|
This pull request has been marked as stale due to 60 days of inactivity. It will be closed in 1 week if no further activity occurs. If you think that’s incorrect or this pull request requires a review, please simply write any comment. If closed, you can revive the PR at any time and @mention a reviewer or discuss it on the dev@beam.apache.org list. Thank you for your contributions. |
|
This pull request has been closed due to lack of activity. If you think that is incorrect, or the pull request requires review, you can revive the PR at any time. |
In our larger streaming pipelines, we generally observe a short blip (1-3 minutes) in event processing, as well as an increase in lag following window closing. One reason for this is the state cleanup timers all firing once a window closes.
We've been running this PR in our dev environment for a few days now, and the results are impressive. By decorrelating (jittering) the state cleanup timer, we spread the timer load across a short period of time, with the trade-off of holding state for a slightly longer period of time. In practice though, I've actually noticed our state cleans up QUICKER with this change, because the timers don't all compete with each other.
I'd like to contribute this back (and could modify the core StatefulDoFn runner as well) if we agree this is something useful.
There's a couple points for discussion:
I added a counter which has been useful for debugging (and seeing how many keys are active each window), but could be removed.(I removed this since it broke a bunch of unit tests)Interested to hear thoughts here.
Here's a before and after of our pubsub latency:
before:
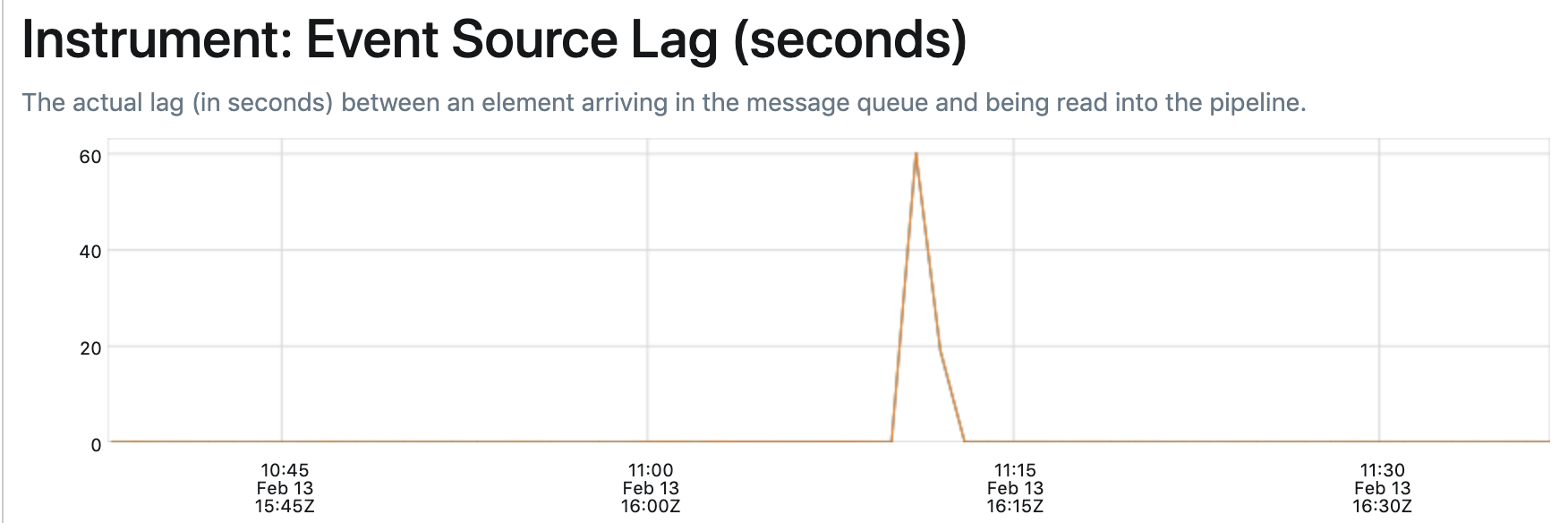
after:

Based on the counter I added, we're firing ~20 million timers, across 50 workers = ~400,000 timers / worker. So rather than having them all fire in one shot, we can spread them over 3 minutes, for only ~2,000 timers / sec, which is much more reasonable.
cc @lukecwik @pabloem
Thank you for your contribution! Follow this checklist to help us incorporate your contribution quickly and easily:
R: @username).[BEAM-XXX] Fixes bug in ApproximateQuantiles, where you replaceBEAM-XXXwith the appropriate JIRA issue, if applicable. This will automatically link the pull request to the issue.CHANGES.mdwith noteworthy changes.See the Contributor Guide for more tips on how to make review process smoother.
Post-Commit Tests Status (on master branch)
Pre-Commit Tests Status (on master branch)
See .test-infra/jenkins/README for trigger phrase, status and link of all Jenkins jobs.