[BEAM-9434] Improve Spark runner reshuffle translation to maximize parallelism #11037
Conversation
|
Awesome work, it looks good to me |
|
R: @lukecwik do you mind having a look and giving me feedback on this PR? Thanks I look forward to hearing from you |
|
Adding a filesystem API that all filesystems need to implement is going to raise some questions in the Apache Beam community. Asked some follow-ups on BEAM-9434 to see if the issue is localized to Spark. |
@lukecwik Ok I see. Technically speaking, it is not mandatory to implement in every filesystem, but effectively in order to properly support the hint in every filesystem it is. I considered a few alternatives:
The reality is, I haven't got a mean of testing the last option on anything else than S3, otherwise the last option is the best approach imho. Let me know what are the opinions. Also, looks like to me that the filesystems classes are internal to the framework, not supposed to be used directly by end users. In which case maybe another option is viable, which is renaming appropriately the new hint, and don't make it mandatory by means of the framework to consider the hint. In other words, I'm saying that we can hint to use N partitions, but the runtime can just ignore the hint if that's not supported by the underlying filesystem. Happy to hear back from you guys, and thanks for the feedback. |
|
The expansion for withHintManyFiles uses a reshuffle between the match and the actual reading of the file. The reshuffle allows for the runner to balance the amount of work across as many nodes as it wants. The only thing being reshuffled is file metadata so after that reshuffle the file reading should be distributed to several nodes. In your reference run, when you say that "the entire reading taking place in a single task/node", was it that the match all happened on a single node or was it that the "read" happened all on a single node? |
Both. |
|
This is the fundamental difference between the base and the current PR. Notice, in the base case there's only 2 tasks (the entire job is a join of two independent readings) whereas when using 10 partitions there are 20 tasks for doing the same work (the image is a detail of one of the two independent readings, showing its 10 parallel partitions). This is reflected in the executors being used and in the time to complete (16 minutes with 2 tasks, 2.3 minutes with 20).
|
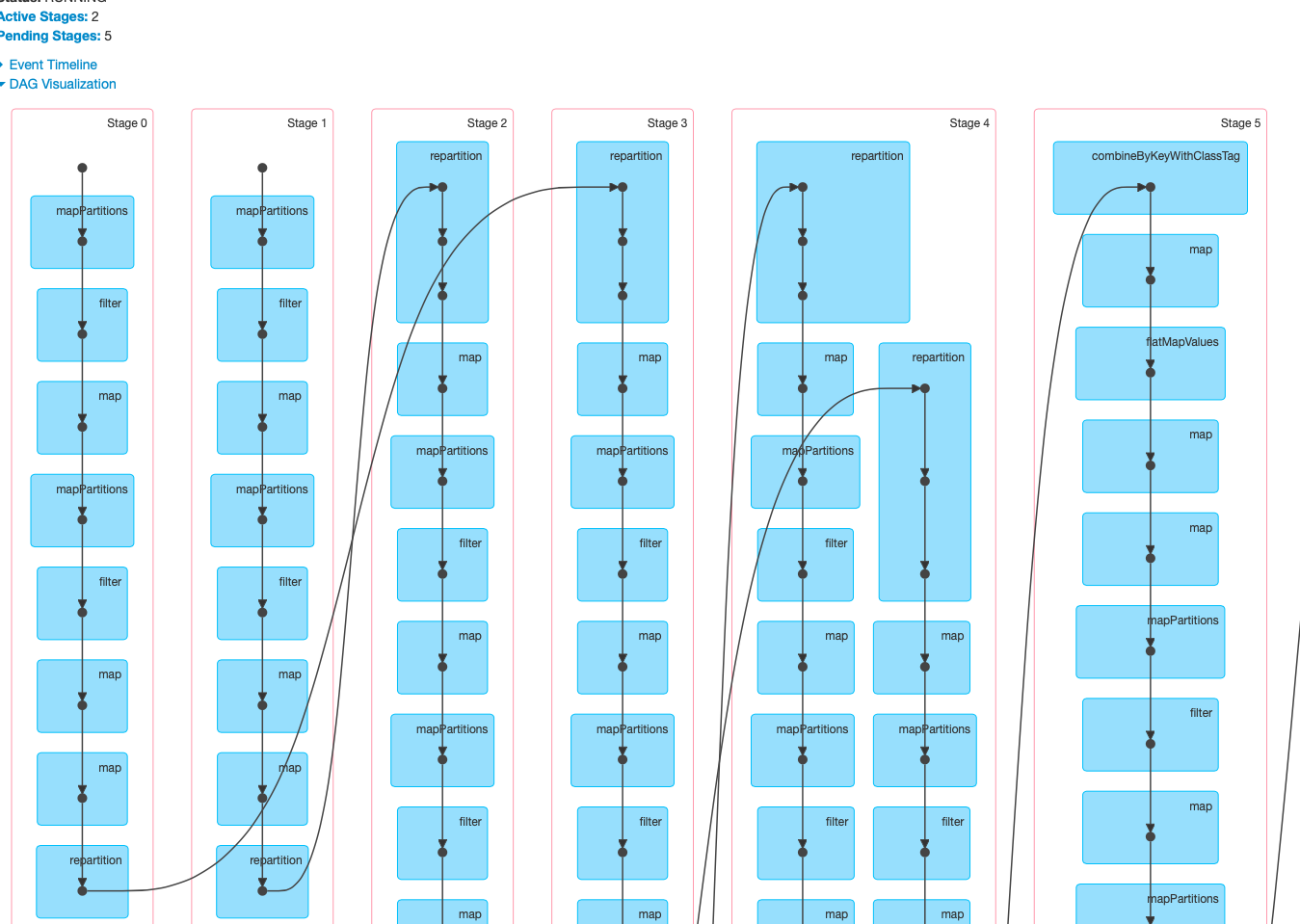
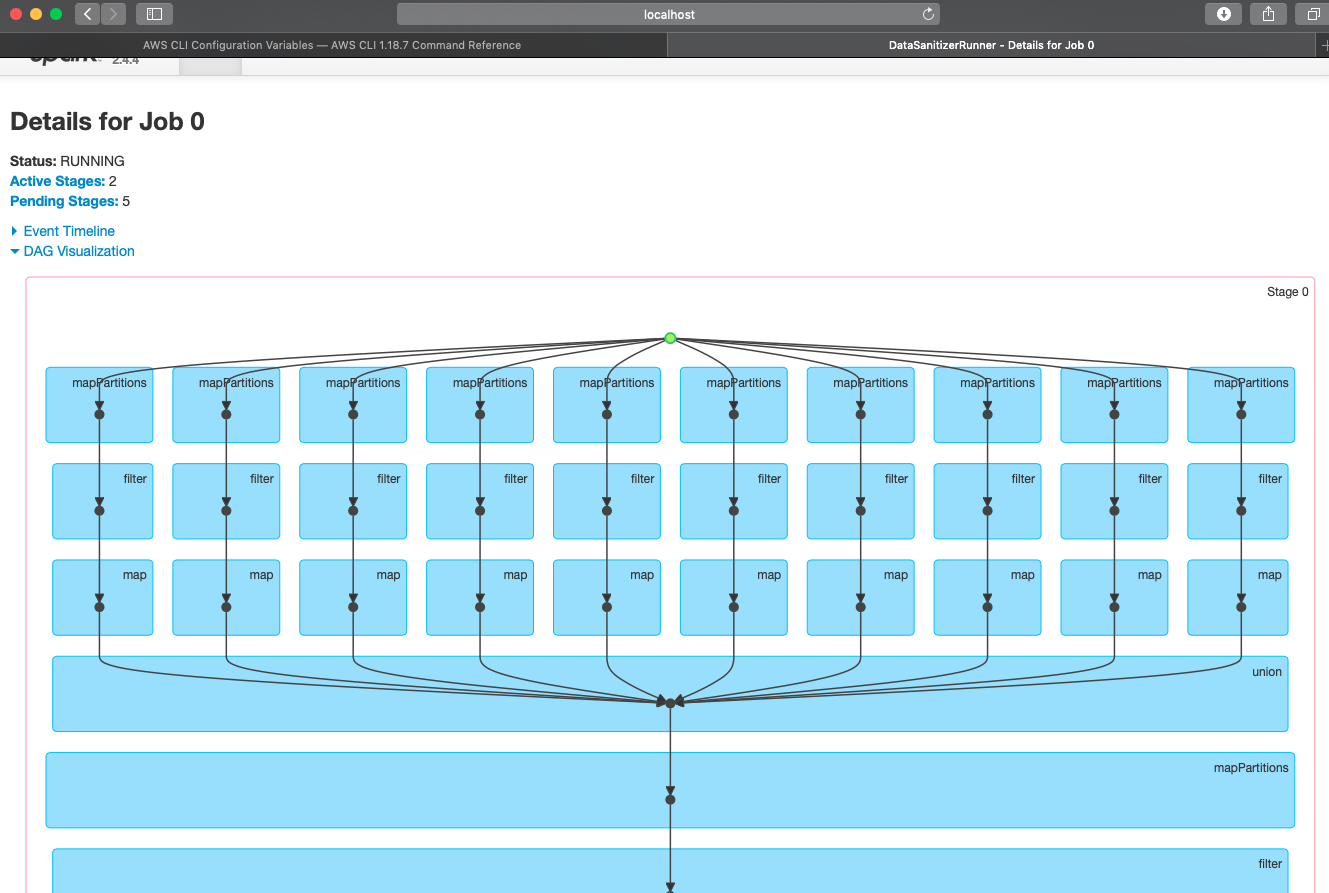

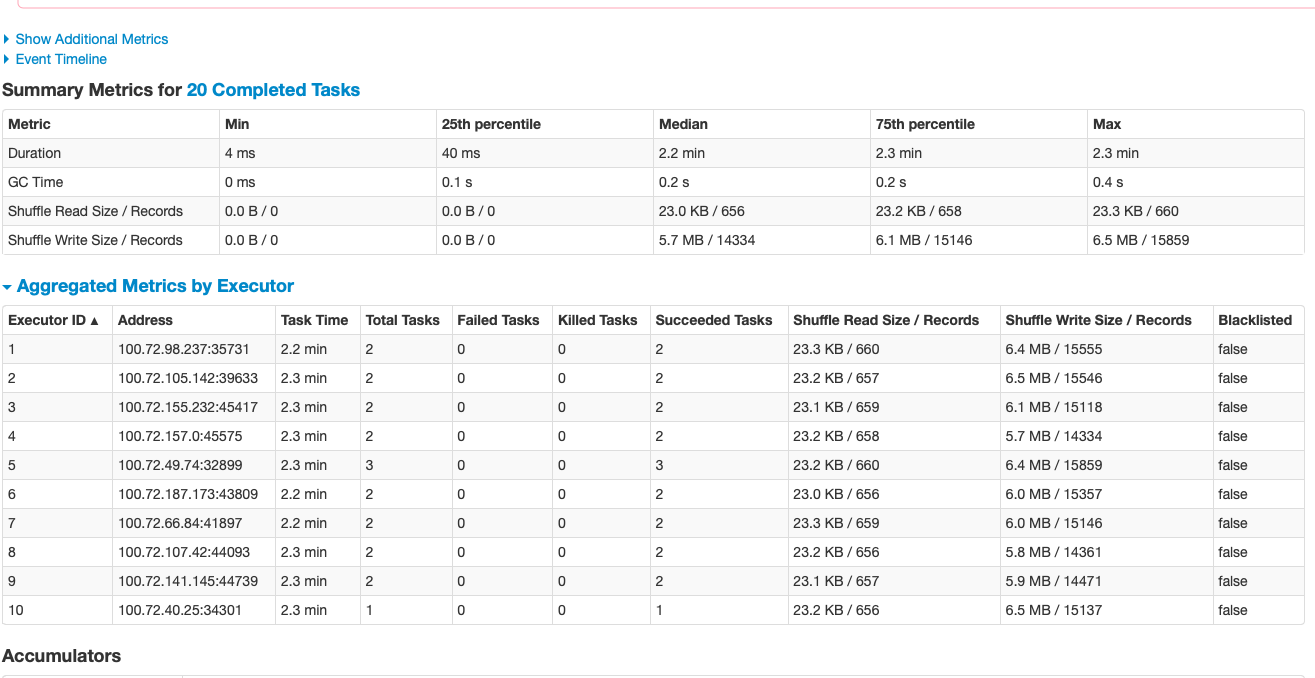
|
I understand what your saying and how your solution resolves the problem. I'm trying to say that the problem shouldn't occur in the first place because AvroIO.read should expand to MatchAll that contains a Reshuffle followed by ReadMatches Reshuffle should ensure that there is a repartition between MatchAll and ReadMatches, is it missing (it is difficult to tell from your screenshots)? If it isn't missing, they why is the following stage only executing on a single machine (since repartition shouldn't be restricting output to only a single machine)? |
|
Unfortunately the problem happens for me, that is why this work started. Let's see if we can understand the root cause for it.
It's clearly not missing as in the base case I'm using withHintMatchesManyFiles(). I had a look at the code of Reshuffle.expand() and Reshuffle.ViaRandomKey, but I have some doubts on what is the expected behaviour in terms of machines / partitions. How many different partitions shall Reshuffle create? Will there be 1 task per partition? and how are the tasks ultimately assigned to the executors? |
|
Sorry about the long delay but Reshuffle should produce as many partitions as the runner thinks is optimal. It is effectively a redistribute operation. It looks like the spark translation is copying the number of partitions from the upstream transform for the reshuffle translation and in your case this is likely 1. Copying partitions: @iemejia Shouldn't we be using a much larger value for partitions, e.g. the number of nodes? |
My time to apology @lukecwik. I was busy on something else as well as trying to settling in this new life of working from home due to the virus
Gotcha. And yes, I can confirm that the value for the partitions is 1, not only in my case. Fact of the matter, the number of partitions is calculated (in a bizarre way) only for the root RDD (Create), containing only the pattern for the s3 files -- a string like
I have changed the PR, reverting the original one and now - after your analysis - I am setting the number of the partitions in the reshuffle transform translator. I have tested this PR with the same configuration as the initial one, and the performance is identical. I can now see all the executors and nodes processing a partition of the read, as one expects. I also did a back-to-back run with the vanilla Beam and I can confirm the problem is still there. I deem this implementation is superior to the first one. Let me have your opinions on it. Also paging in @iemejia I have seen the previous build failing, I think the failing tests were unrelated to the changes; keen to see a new build with these code changes. |
|
Thanks for the follow-up. I also have been adjusting to the new WFH lifestyle. |
| int numPartitions = | ||
| Math.max(context.getSparkContext().defaultParallelism(), inRDD.getNumPartitions()); |
There was a problem hiding this comment.
I believe we should do the same thing in the streaming and batch portable pipeline translators as well.
There was a problem hiding this comment.
Thanks a lot @ecapoccia for the investigation and fix! Can you please do the suggested changes, squash your commits into a single commit with title [BEAM-9434] Improve Spark runner reshuffle translation to maximize parallelism and do a git pull origin master --rebase to rebase against latest master.
I will be glad to merge once ready and tests green.
| @@ -184,11 +184,11 @@ | |||
|
|
|||
| /** An implementation of {@link Reshuffle} for the Spark runner. */ | |||
| public static <T> JavaRDD<WindowedValue<T>> reshuffle( | |||
| JavaRDD<WindowedValue<T>> rdd, WindowedValueCoder<T> wvCoder) { | |||
| JavaRDD<WindowedValue<T>> rdd, WindowedValueCoder<T> wvCoder, int numPartitions) { | |||
There was a problem hiding this comment.
Can you please let this method how it was before and better, and do int numPartitions = Math.max(rdd.context().defaultParallelism(), rdd.getNumPartitions()); inside of it. That way you don't need to replicate the change in the different translators..
There was a problem hiding this comment.
@iemejia @lukecwik ok will do the changes. The only reason why I opted to change only the batch pipeline for Spark is that it is the only one I am in a position to thoroughly test for real. However, analysing the code suggests that changing all pipelines does not harm, so I'll go for the suggested changes.
Will submit the squashed PR soon. In the meantime, thanks for the review.
|
Run Spark ValidatesRunner |
|
Run Spark Runner Nexmark Tests |
|
Run Java Spark PortableValidatesRunner Batch |
|
Run Python Spark ValidatesRunner |
|
Run Go Spark ValidatesRunner |
|
Thanks @ecapoccia nice work! |
Thank you guys @iemejia @lukecwik it was good for me to learn a bit about the internals. |
The implemented solution consists in an extension of the FileSystem classes for S3, that allows filtering of the matched objects. The filter consists in a mod hash function of the filename.
This mechanism is exploited by a parallel partitioned read of the files in the bucket, realised in the AvroIO and FileIO classes by means of the new hint . withHintPartitionInto(int)
The net effect is that a controlled number of tasks is spawn to different executors, each having a different partition number; each executor reads the entire list of files in the bucket, but matches only those files whose modhash matches the partition number.
In this way, all the executors in the cluster read in parallel.
Thank you for your contribution! Follow this checklist to help us incorporate your contribution quickly and easily:
R: @username).[BEAM-XXX] Fixes bug in ApproximateQuantiles, where you replaceBEAM-XXXwith the appropriate JIRA issue, if applicable. This will automatically link the pull request to the issue.CHANGES.mdwith noteworthy changes.See the Contributor Guide for more tips on how to make review process smoother.
Post-Commit Tests Status (on master branch)
Pre-Commit Tests Status (on master branch)
See .test-infra/jenkins/README for trigger phrase, status and link of all Jenkins jobs.