HADOOP-17296. ABFS: Force reads to be always of buffer size. #2368
Conversation
Make readahead block size and number of readahead buffers configurable Fixes to RAH
|
Test results from accounts in East US 2 regions: NON-HNS:HNS:2 failures seen in most combination call fs.listStatusIterator() APIs. These APIs are not supported by ABFS FS currently. Need to check if a recent change to test introduced this call. |
...tools/hadoop-azure/src/main/java/org/apache/hadoop/fs/azurebfs/services/AbfsInputStream.java
Outdated
Show resolved
Hide resolved
...tools/hadoop-azure/src/main/java/org/apache/hadoop/fs/azurebfs/services/AbfsInputStream.java
Outdated
Show resolved
Hide resolved
...op-azure/src/main/java/org/apache/hadoop/fs/azurebfs/constants/FileSystemConfigurations.java
Outdated
Show resolved
Hide resolved
| @@ -178,11 +195,15 @@ private int readOneBlock(final byte[] b, final int off, final int len) throws IO | |||
| buffer = new byte[bufferSize]; | |||
| } | |||
|
|
|||
| // Enable readAhead when reading sequentially | |||
| if (-1 == fCursorAfterLastRead || fCursorAfterLastRead == fCursor || b.length >= bufferSize) { | |||
| if (alwaysReadBufferSize) { | |||
| bytesRead = readInternal(fCursor, buffer, 0, bufferSize, false); | |||
There was a problem hiding this comment.
JIRA and PR description says we are trying to read till bufferSize always rather than just the requested length but as per this line we are enabling the buffer manager readahead as well which is bypassed in random read in gen2 as per line 205 below. PS: I have never seen gen1 code though.
There was a problem hiding this comment.
AlwaysReadBufferSize helped the IO pattern to match the Gen1 run. But to be performant readAhead had to be enabled. For the customer scenario explained in the JIRA , for the small row groups for an overall small parquet file size, reading whole buffer size along with readAhead bought good performance.
| long nextOffset = position; | ||
| // First read to queue needs to be of readBufferSize and later |
There was a problem hiding this comment.
Would like to understand the reasoning behind this. Thanks.
There was a problem hiding this comment.
Couple of things here:
- The earlier code allowed bufferSize to be configurable whereas ReadAhead buffer size was fixed. And each time loop is done, read issued was always for bufferSize which can lead to gaps/holes in the readAhead range done.
- There is no validation for 4MB as a fixed size for readAhead is optimal for all sequential reads. Having a higher readAhead range for apps like DFSIO which are guaranteed sequential and doing higher readAhead ranges in background can be performant.
In this PR, the bug in point 1 is fixed and also a provision to configure readAhead buffer size is provided.
There was a problem hiding this comment.
What do you mean by gaps/holes in the readAhead range done here?
Have you done any experiments on this readAheadBlockSize config? If so, please share.
There was a problem hiding this comment.
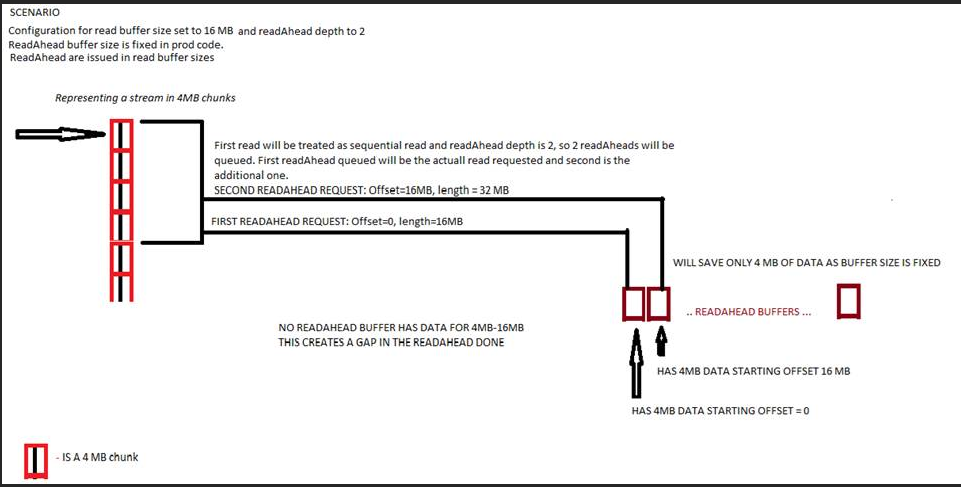
If the buffer gets overwritten by config to 16MB, the readAhead buffer size will still remain to be 4MB as it was a code static. The loop done will start issuing readAheads in 16 MB buffer sizes, the request to readAhead will be:
offset=0, Length=16MB
offset=16MB, Length=32MB
But the readAhead buffer size is stuck at 4 MB. so it will read only:
offset=0 Length=4MB
offset=16MB Length=4MB
Gap being at 4MB to 16MB here.
This bug is getting fixed. Tests for all possible combinations here has been added to the tests of this PR.
There was a problem hiding this comment.
I don't think there is any bug in the current production code as such. As far as I understand the code the change is introduced becuase new config is introduced.
Now my question is why not use readAheadBlockSize for the first call as well? The calls would be like
offset=0 Length=4MB
offset=4MB Length=4MB
Sorry to say this but honestly speaking, introducing so many configs is making the code complex and confusing.
There was a problem hiding this comment.
Read buffer size config being available to be modified, fixed read ahead buffer size and issuing read aheads by buffer size is the current prod behaviour and will function as the picture attached. This will need fixing.
And as for deprecating read buffer size config and only use the new read ahead buffer size config. The config has been available since GA, and hence deprecating it would not be feasible. (Also for clients who are disabling readAheads to use readahead buffer size for reads might be confusing too).
As for the number of different configs present for read, 1 and 2 configs already were present while this PR is introducing 3 and 4. So total of 4 configs.
- fs.azure.read.request.size
- fs.azure.readaheadqueue.depth
- fs.azure.read.alwaysReadBufferSize => For Gen1 migrating customers
- fs.azure.read.readahead.blocksize => Was one that needed fixing long back as there is no validation on 4 MB being the right size for all workloads. Just the way read buffer size can be modified.
All these changes are being added based on various customer issues and experiences that we are dealing with. Instead of spending our time in providing patches that can enable them to test various combinations, having these options over a config for their testing saves our dev time to improve the service. As you can see in the PR, the defaults introduced by these configs will retain the current prod behavior.
There was a problem hiding this comment.
Have synced with @mukund-thakur over mail thread further to clear the understanding.
...ols/hadoop-azure/src/main/java/org/apache/hadoop/fs/azurebfs/services/ReadBufferManager.java
Outdated
Show resolved
Hide resolved
| static { | ||
| BUFFER_MANAGER = new ReadBufferManager(); | ||
| BUFFER_MANAGER.init(); | ||
| static ReadBufferManager getBufferManager() { |
There was a problem hiding this comment.
Why all these changes ? Why not just initilize the blockSize in init() ?
There was a problem hiding this comment.
For singleton classes its a common practice to lock around the new instance creation within the getInstance() method. Also, didnt want to make any changes to init method.
There was a problem hiding this comment.
Retaining the change as current change has no functional issues.
There was a problem hiding this comment.
FWIW, synchronize on the Class object is a standard pattern here, but the lock is fine, just a bit of extra coding
...ols/hadoop-azure/src/main/java/org/apache/hadoop/fs/azurebfs/services/ReadBufferManager.java
Show resolved
Hide resolved
|
Reviewed the production code. Will review the test code as well once I get some time. |
|
Test results from accounts on East US 2 region: NON-HNS:HNS: |
|
@mukund-thakur Thanks for your review. I have updated the PR with suggestions. Kindly request you to review. |
There was a problem hiding this comment.
Production code almost ready apart from one query here #2368 (comment)
Added some minor comments on test code mostly around asserstions. Try if we can use assertJ asserstions which provide rich capabilities and good error messaging.
For example : https://github.com/apache/hadoop/pull/2307/files#diff-58b8ac52c9e03341fd23fdf90d318e6972570d010f6a12fe4a0ebaf72a59251dR249
| assertTrue("Read should be of exact requested size", | ||
| inputStream.read(firstReadBuffer, 0, readRequestSize) == readRequestSize); | ||
| assertTrue("Data mismatch found in RAH1", | ||
| Arrays.equals(firstReadBuffer, |
There was a problem hiding this comment.
AssertJ has rich api's to tackle these kind of assertions. Try that
example : Assertions.assertThat(list)
.hasSameElementsAs(list2)
There was a problem hiding this comment.
Thanks. Have updated except for the content check assert.
|
|
||
| assertTrue("Read should be of exact requested size", | ||
| inputStream.read(secondReadBuffer, 0, readAheadRequestSize) == readAheadRequestSize); | ||
| assertTrue("Data mismatch found in RAH2", |
There was a problem hiding this comment.
Better to use assert equals here inspite of assertTrue no?
There was a problem hiding this comment.
:) Just a force of habit. Will try to use the assertions.
Have modified in the other test code areas of this PR as well.
| } | ||
| } | ||
|
|
||
| private AzureBlobFileSystem createTestFile(Path testFilePath, long testFileSize, |
There was a problem hiding this comment.
See if you can reuse the data generation and new file creation code from ContractTestUtils.dataset() and ContractTestUtils.createFile.
There was a problem hiding this comment.
I need the file created to also have a specific pattern of data ingested and have another method which needs to return the expected data content from offset to range. This is being used to cross check with readahead buffer data. Will retain for these tests. But thanks, hadnt observed the other APIs, will default to them where there isnt a specific needs on the file content.
| testAlwaysReadBufferSizeConfig(true); | ||
| } | ||
|
|
||
| private void assertStatistics(AzureBlobFileSystem fs, |
There was a problem hiding this comment.
Why creating a new method here if we are just doing a passthrough?
There was a problem hiding this comment.
Redundant method removed.
|
this will need to be rebased now that #2369 |
|
@mukund-thakur - Have addressed the review comments. Please have a look. |
|
Re-ran the oAuth tests with the latest changes: |
|
Test failures reported in Yetus are not related to ABFS driver. Have created JIRA for tracking the failures. |
|
Hi @mukund-thakur, Kindly request your review, so that I can freeze on comments from your side. |
|
@mukund-thakur - Will appreciate if you can confirm your review status on this PR. Have provided updates for your comments. |
HNS-OAuth[INFO] Results: HNS-SharedKey[INFO] Results: NonHNS-SharedKey[INFO] Results: NonHNS-OAuth[INFO] Results: Test failures reported in Yetus are not related to ABFS driver. Have created JIRA for tracking the failures. |
I was on a vacation. Will check once I get some time. |
HNS-OAuth[INFO] Results: NonHNS-OAuth[INFO] Results: HNS-SharedKey[INFO] Results: NonHNS-SharedKey[INFO] Results: Rename Test failure is tracked in JIRA: https://issues.apache.org/jira/browse/HADOOP-17396 |
|
🎊 +1 overall
This message was automatically generated. |
|
@mukund-thakur Have synced with latest trunk. Please have a look. |
| @@ -99,12 +115,14 @@ public void testBasicRead() throws Exception { | |||
| public void testRandomRead() throws Exception { | |||
| Assume.assumeFalse("This test does not support namespace enabled account", | |||
| this.getFileSystem().getIsNamespaceEnabled()); | |||
| assumeHugeFileExists(); | |||
| Path testPath = new Path(TEST_FILE_PREFIX + "_testRandomRead"); | |||
There was a problem hiding this comment.
FWIW I use a Junit rule to get the method name, then you can hava a path() method which dynamically creates the unique path, including when you use parameterized tests.
|
ok, merged into trunk. For 3.3.x can you do the backport, retest and put up a new PR for me to merge in there? That branch doesn't have guava under the thirdparty packaging, so a safe cherrypick isn't enough to prove it will compile/run. Don't worry about reordering the import references, just edit out the o.a.h.thirdparty prefixes and leave as is. |
Customers migrating from Gen1 to Gen2 often are observing different read patterns for the same workload. The optimization in Gen2 which reads only requested data size once detected as random read pattern is usually the cause of difference.
In this PR, config option to force Gen2 driver to read always in buffer size even for random is being introduced. With this enabled the read pattern for the job will be similar to Gen1 and be full buffer sizes to backend.
Have also accommodated the request to config control the readahead size to help cases such as small row groups in parquet files, where more data can be captured.
These configs are not determined to be performant on the official parquet recommended row group sizes of 512-1024 MB and hence will not be enabled by default.
Tests are added to verify various combinations of config values. Also modified tests in file ITestAzureBlobFileSystemRandomRead which were using same file and hence test debugging was getting harder.