[HUDI-4384] fix hive style partition and record key prefix missing in bulk_insert #6085
Conversation
|
Fix #6070 |
|
Manually verified the change by running a job locally. The reproduce code can be found in JIRA ticket: HUDI-4384 Result After fix:
Result before fix:
|
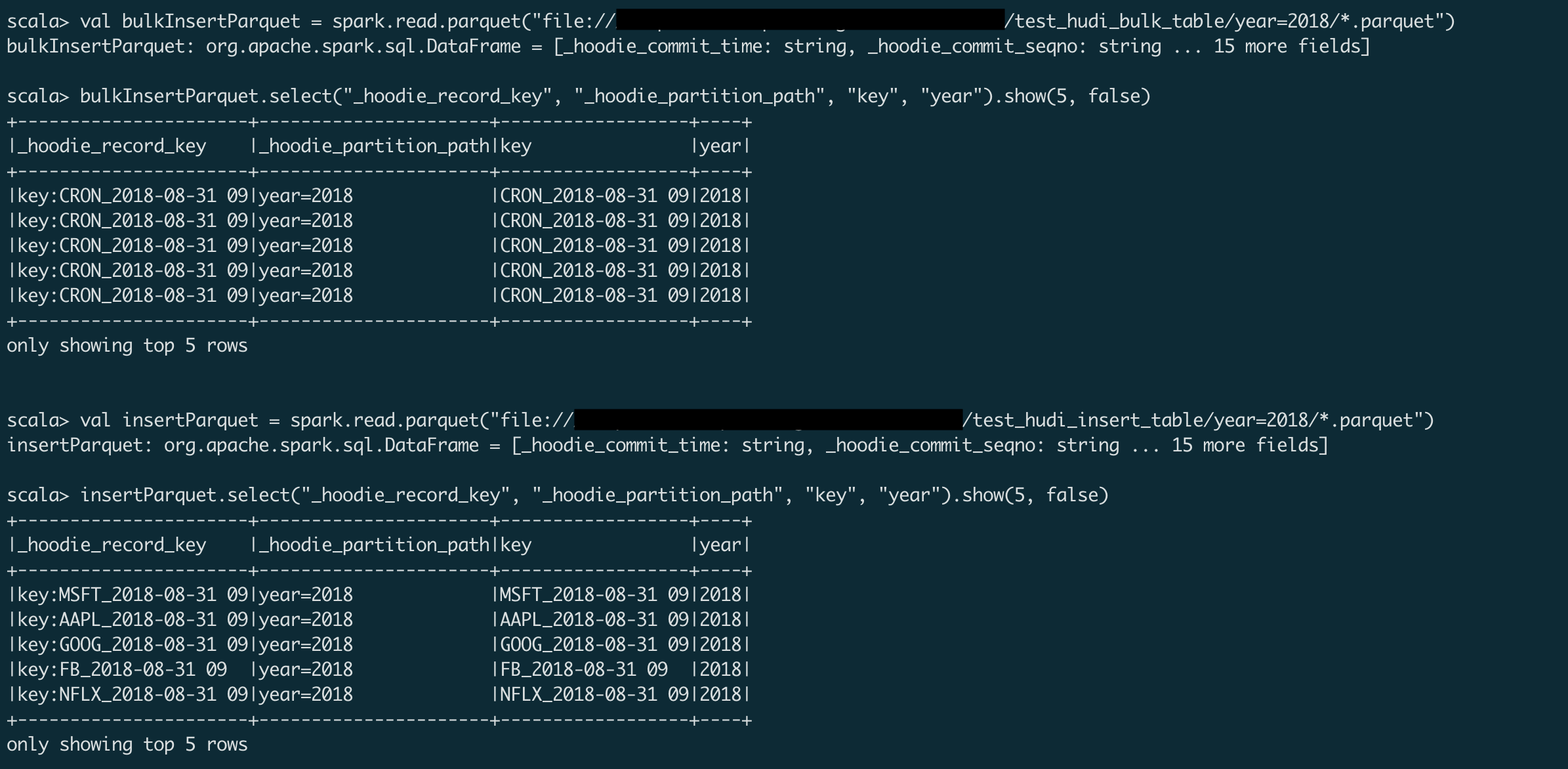
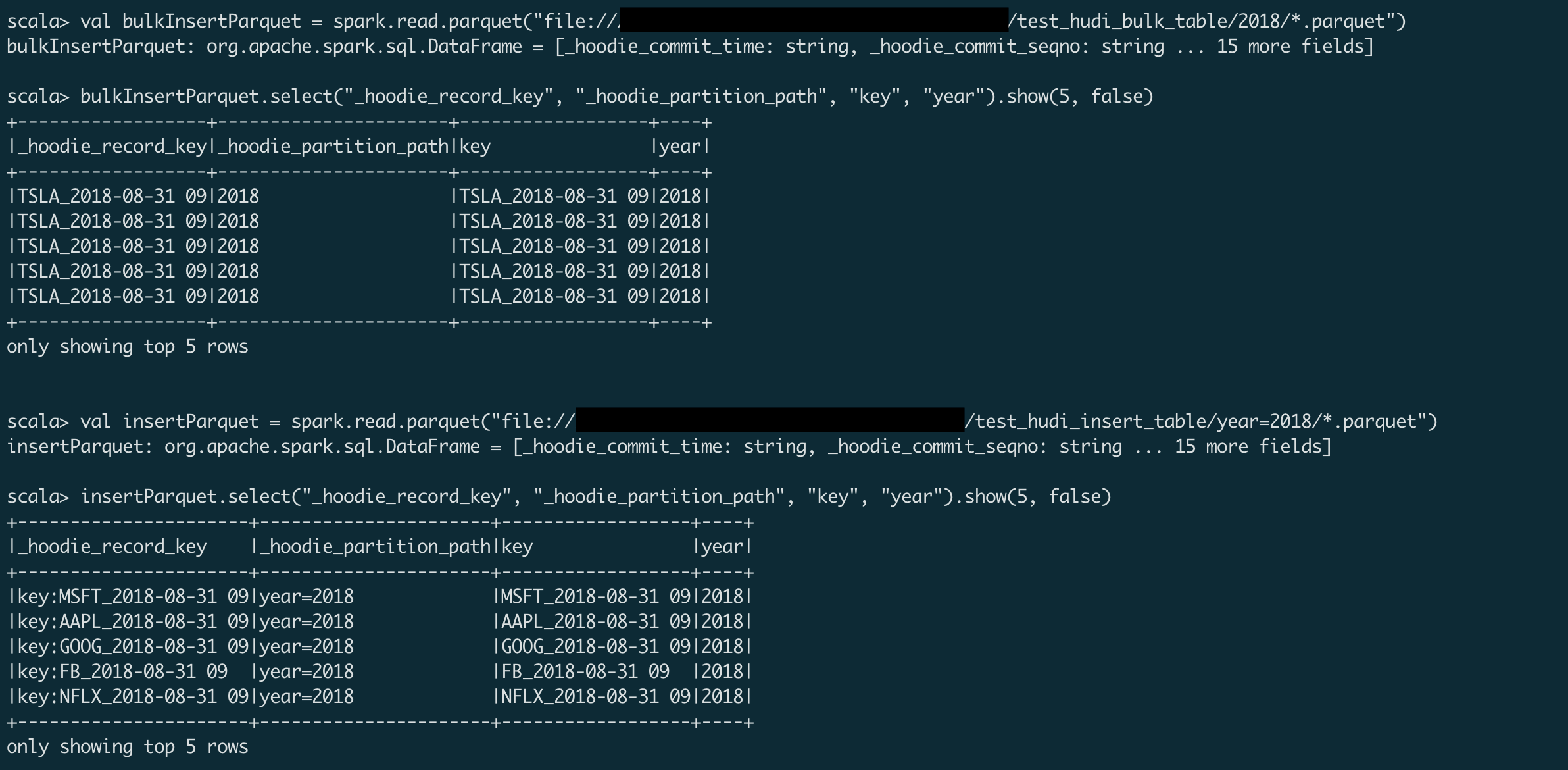
|
@hudi-bot run azure |
1 similar comment
|
@hudi-bot run azure |
|
The test May I know how I can fix it? or should I re-run the test again? |
| @@ -87,18 +86,15 @@ public static Dataset<Row> prepareHoodieDatasetForBulkInsert(SQLContext sqlConte | |||
| BuiltinKeyGenerator keyGenerator = (BuiltinKeyGenerator) ReflectionUtils.loadClass(keyGeneratorClass, properties); | |||
|
|
|||
| Dataset<Row> rowDatasetWithRecordKeysAndPartitionPath; | |||
| if (keyGeneratorClass.equals(NonpartitionedKeyGenerator.class.getName())) { | |||
| if (keyGeneratorClass.equals(NonpartitionedKeyGenerator.class.getName()) | |||
| || (keyGeneratorClass.equals(SimpleKeyGenerator.class.getName()) && !config.isHiveStylePartitioningEnabled())) { | |||
There was a problem hiding this comment.
if hive style partitioning is enabled, we are falling back to using udf flow is it? guess the intent was to do use udf based key gen only for non simple use-cases. Can we honor the same even w/ hive style partitioning enabled please?
There was a problem hiding this comment.
yeah, this PR will fall back to UDF if hive style partition enabled, same logic as 0.10.
think PR #6049 is a better fix which can improve performance by using withColumn
|
since the other is marked as priority blocker, closing this one. |
Tips
What is the purpose of the pull request
Fix [HUDI-4384] hive style partition and record key prefix missing in bulk_insert in Spark
Brief change log
ComplexKeyGeneratorbypass inHoodieDatasetBulkInsertHelper.prepareHoodieDatasetForBulkInserttestBulkInsertWithHiveStylePartitioninTestHoodieDatasetBulkInsertHelperVerify this pull request
This change added tests and can be verified as follows:
testBulkInsertWithHiveStylePartitioninTestHoodieDatasetBulkInsertHelperCommitter checklist
Has a corresponding JIRA in PR title & commit
Commit message is descriptive of the change
CI is green
Necessary doc changes done or have another open PR (no need)
For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. (no need)