KYLIN-4035 Calculate column cardinality by using spark engine #680
Conversation
|
Can one of the admins verify this patch? |
1 similar comment
|
Can one of the admins verify this patch? |
Codecov Report
@@ Coverage Diff @@
## master #680 +/- ##
========================================
Coverage ? 25.7%
Complexity ? 6011
========================================
Files ? 1386
Lines ? 82510
Branches ? 11568
========================================
Hits ? 21207
Misses ? 59258
Partials ? 2045
Continue to review full report at Codecov.
|

| }) | ||
| .sortByKey(true, 1); | ||
|
|
||
| if (resultRdd.count() == 0) { |
There was a problem hiding this comment.
Both count and saveAsNewAPIHadoopFile are action of RDD, I think here resultRdd should be cached to avoid recompute, am I right?
There was a problem hiding this comment.
Yes, It's a good point. I forgot to cache it.
I will add cache, Thank you !
|
In my hadoop cluster(JDK8, hadoop2.6-cdh5.6 with spark-2.3.3-hadoop2.6), I have verfied this patch pass happy path with correct result. By MR
By Spark
Yarn Successful Jobs
|

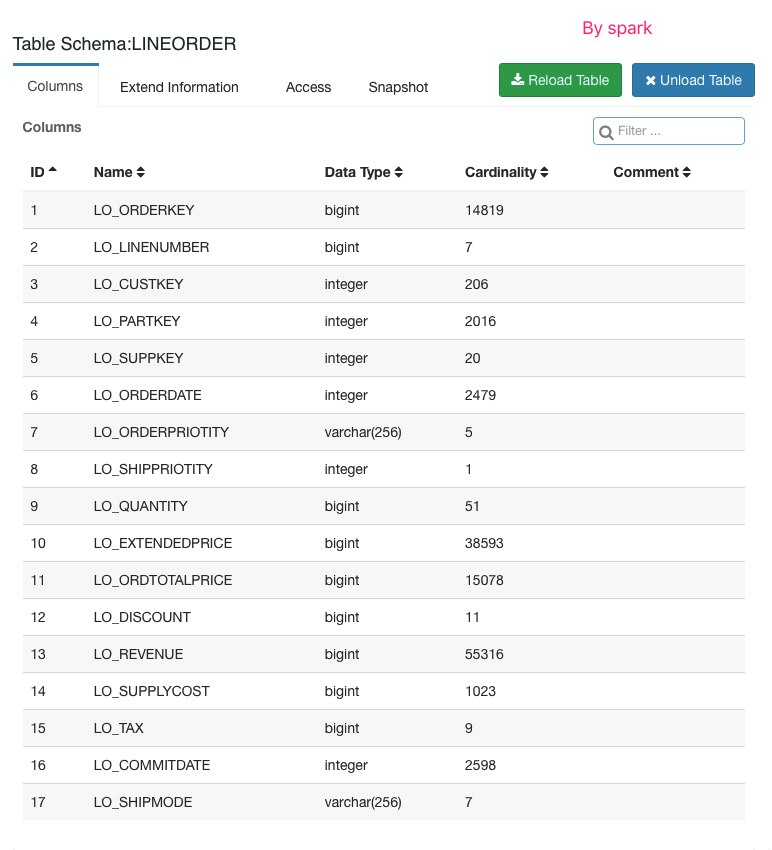

| @@ -1430,6 +1430,10 @@ public boolean isSparkFactDistinctEnable() { | |||
| return Boolean.parseBoolean(getOptional("kylin.engine.spark-fact-distinct", "false")); | |||
| } | |||
|
|
|||
| public boolean isSparkCardinalityEnabled(){ | |||
| return Boolean.parseBoolean(getOptional("kylin.engin.spark-cardinality", "false")); | |||
link to https://issues.apache.org/jira/browse/KYLIN-4035
Support calculating column cardinality by using spark engine