NIFI-3229 When a queue contains only Penalized FlowFile's the next pr… #3131
Conversation
…ocessor Tasks/Time statistics becomes extremely large
|
@patricker thanks for the PR! I had gone down this path before but I backed out the changes. The changes in this PR will result in obtaining a Write Lock on the queue of every incoming connection for every running processor in the graph. This can become quite expensive for a complex flow that is made up of thousands (or even 10's of thousands) of processors) and result in overall system performance suffering. This is why we are so care in the FlowFile Queue's implementation to ensure that isActiveQueueEmpty() never obtains a lock but instead only references AtomicReference variables. We should be able to do better, though. For example, when we pull a FlowFile from the queue, we check if it's penalized. If so, we throw it back on. Since the queue is ordered, we could do some smart things like looking at the FlowFile expiration date, then keeping track of the fact that we know all FlowFiles are penalized until that time is reached - or until a non-penalized FlowFile is added to the queue. |
|
@markap14 I was worried about the same thing, which is why the All my change does is add one additional check, but only if |
|
@patricker you're right - it may perform just fine. However, the concern is not that we are holding a lock longer but rather that we are obtaining it twice as often now when there's data queued. The acquisition of the lock itself can be expensive. So all I am suggesting is that we don't want to make such a change without knowing how it's going to affect things. We'd want to gather some performance numbers before and after this changeset is applied. Specifically, I'd want to setup a test suite that calculates things like: I'd want to run these tests 10-20 times in a row to ensure that the numbers are steady, and then get these numbers before and after the changeset is applied. |
|
@markap14 Sounds reasonable, I'll work on it. |
Signed-off-by: Peter Wicks <patricker@gmail.com>
|
@markap14 I built unit tests, but I'm having trouble running them at scale. I temporarily checked back in the original method so I could run side-by-side speed comparisons on the same These are checked in right now to run 1 million iterations, but that has not succeeded for me... This is true of the unmodified method if run by itself also (at least on my poor little computer). |
|
Hey @patricker sorry for the delay in getting back to this. I looked into the unit tests, and did some quick profiling. It looks like the reason that it seemed to "go out to lunch" as you say was because of Mockito objects being used. They are super useful but don't provide great performance. I updated the test so that instead of using Mockito it just created simple objects like Funnels or implemented interfaces directly without much of anything happening. That resulted in much better performance. I updated the test about to run in multiple threads, as well, because this is where we are going to see the heavy contention and therefore the performance concerns. When I run with a single thread, we see pretty comparable results between the existing implementation and the new implementation that checks for penalization:
The difference is measurable but not necessarily concerning.
However, when we update the test to use 12 threads, we see some results that are more concerning:
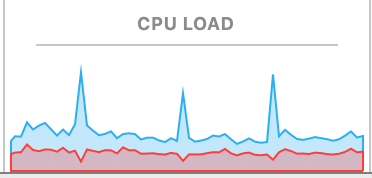
So with 12 threads, each checking 1 million times, the difference in performance/latency goes from 2-3 seconds to 70-90 seconds. We can also see what happens to the CPU utilization as it switches between the version that checks penalization and the one that doesn't: So at one thread, I'm not concerned about the performance difference. But if you start adding several threads to a processor, the performance concern is definitely more significant and I think is concerning. |
…ocessor Tasks/Time statistics becomes extremely large
For all changes:
Is there a JIRA ticket associated with this PR? Is it referenced
in the commit message?
Does your PR title start with NIFI-XXXX where XXXX is the JIRA number you are trying to resolve? Pay particular attention to the hyphen "-" character.
Has your PR been rebased against the latest commit within the target branch (typically master)?
Is your initial contribution a single, squashed commit?
For code changes:
For documentation related changes:
Note:
Please ensure that once the PR is submitted, you check travis-ci for build issues and submit an update to your PR as soon as possible.