HDDS-4557. [DESIGN] S3/Ozone Filesystem inter-op #1411
Conversation
|
Opened as a DRAFT pull request as this is only a proposal. @arp7 and @bharatviswa504 still have concerns about the proposed approach. |
| | `s3` key `/a/b//c` available from `ofs/o3fs` | YES | NO | ||
| | `s3` key `/a/b//c` available from `s3` | AWS S3 incompatibility | YES | ||
|
|
||
| (1): Under implementation |
There was a problem hiding this comment.
I don't think that is true. Paths are normalized already on the S3 interface when writing new keys.
There was a problem hiding this comment.
Here AWS S3 incompatibility means, is it because we are showing normalized keys?
There was a problem hiding this comment.
Here AWS S3 incompatibility means, is it because we are showing normalized keys?
Yes, keys are normalized. Content can be found under different key names.
I started to define the 100% compatibility here:
There was a problem hiding this comment.
I don't think that is true. Paths are normalized already on the S3 interface when writing new keys.
But not for read, if I understood well. But happy to remove this line if it's confusing.
| * Out of the box Ozone should support both S3 and HCFS interfaces without any settings. (It's possible only for the regular path) | ||
| * As 100% compatibility couldn't be achieved on both side we need a configuration to set the expectations in case of incompatible key names | ||
| * Default behavior of `o3fs` and `ofs` should be as close to `s3a` as possible | ||
| This proposal suggest to use a 3rd option where 100% AWS compatiblity is guaranteed in exchange of a limited `ofs/o3fs` view: |
There was a problem hiding this comment.
I completely disagree with this trade-off. The FS limited view is neither here nor there. You can insert keys via the S3 interface that are not visible via the FS view at all. To me this is the same as a corrupted filesystem. Marton, I liked your offline suggestion much better - disable FS access completely when operating in S3-compatible mode.
Taking this one step further, I have a different approach in mind. Let's make this a per-bucket setting. For buckets created via the S3 interface, by default the S3 semantics will be preserved 100% unless the global setting is enabled and FS access will not be allowed at all. For buckets created via FS interface, the FS semantics will always take precedence. If the global setting is enabled, then the value of the setting at the time of bucket creation is sampled and that takes effect for the lifetime of the bucket. Basically you can't change the behavior for a given bucket.
There was a problem hiding this comment.
We also have another way right, an existing bucket can be exposed created via CLI to be exposed to S3, what semantics that bucket will get?
For buckets created via FS interface, the FS semantics will always take precedence
Buckets creation is possible via only OFS, what about O3fs?
If the global setting is enabled, then the value of the setting at the time of bucket creation is sampled and that takes >effect for the lifetime of the bucket.
A bucket created via Shell, when global flag (assuming ozone.om.enable.filesystem.paths=true), they will follow FS semantics and with slight S3 incompatibility.
So, a bucket created via Shell, when global flag (assuming ozone.om.enable.filesystem.paths=false), they will follow S3 semantics and with broken FS semantics or completely disallow.
Written from my understanding, as I have not got the complete context of the proposal.
I might be missing somethings here.
There was a problem hiding this comment.
an existing bucket can be exposed created via CLI to be exposed to S3, what semantics that bucket will get?
If the bucket was created via FS interface, it will support FS semantics.
Buckets creation is possible via only OFS, what about O3fs?
Good point, for buckets created via the Ozone shell, we could accept a command-line flag. The default can be filesystem because S3 buckets are traditionally created via the S3 API. You're right this needs some more discussion.
There was a problem hiding this comment.
Different behavior on bucket level seems to be an interesting idea.
For buckets created via FS interface, the FS semantics will always take precedence.
How would you define the behavior of bucket is created from S3?
I suppose in this case we should support 100% AWS S3 compatibility (without forced normalization).
But how would o3fs/ofs work in case of s3 buckets:
- Partial view from ofs (incompatible keys are hidden)
ofs/o3fsis disabled (exception), no intermediate directories are created.
There was a problem hiding this comment.
Also, one disadvantage: bucket level settings have increased complexity. It's harder to define the expected behavior for a specific path. Cluster level settings is easie, as there is one global behavior for the setup.
|
I have an alternate proposal, idea left in a comment. cc @bharatviswa504 @elek |
|
|
||
| To solve the performance problems of the directory listing / rename, [HDDS-2939](https://issues.apache.org/jira/browse/HDDS-2939) is created, which propose to use a new prefix table to store the "directory" entries (=prefixes). | ||
|
|
||
| [HDDS-4097](https://issues.apache.org/jira/browse/HDDS-4097) is created to normalize the key names based on file-system semantics if `ozone.om.enable.filesystem.paths` is enabled. But please note that `ozone.om.enable.filesystem.paths` should always be turned on if S3 and HCFS are both used which means that S3 and HCFS couldn't be used together with normalization. |
There was a problem hiding this comment.
S3 and HCFS couldn't be used together without normalization??
There was a problem hiding this comment.
Yes, thanks. I also clarified this paragraph a little:
But please note that
ozone.om.enable.filesystem.pathsshould always be turned on if S3 and HCFS are both used. It means that if both S3 and HCFS are used, normalization is forced, and S3 interface is not fully AWS S3 compatible. There is no option to use HCFS and S3 but with full AWS compatibility (and reduced HCFS compatibility).
| |-|-|-| | ||
| | create itermediate dirs | YES | NO | | ||
| | normalize key names from `ofs/o3fs` | YES | NO | ||
| | force to normalize key names of `s3` interface | YES (1) | NO |
There was a problem hiding this comment.
There is no such force flag, if normalize is enable, we normalize from all interfaces.
As We have 4 interfaces.
- CLI
- S3
- HCFS
- Java Native Client.
So, this flag is not some thing special for S3.
There was a problem hiding this comment.
Yes, agree. I tried to explain this behavior with the two lines to show that both are normalized. This is not because we have two flags.
| | ozone.om.intermediate.dir.generation= | true | | ||
| |-|-|-| | ||
| | create itermediate dirs | YES | | ||
| | normalize key names from `ofs/o3fs` | YES | |
There was a problem hiding this comment.
There is no special normalize is needed, as we use Path Object in FS, key names are normalized and sent to OM
There was a problem hiding this comment.
Yes. I just tried to show here this out-of-the-box behavior. But agree.
We have it for free and actually this couldn't be removed: if we use ofs/o3fs, the keys from ofs/o3fs should always be normalized.
|
|
||
| | configuration | behavior | | ||
| |-|-| | ||
| | `ozone.om.enable.filesystem.paths=true` | Enable intermediate dir generation **AND** key name normalization |
There was a problem hiding this comment.
so even if the other setting is false(ozone.om.enable.intermediate.dirs = false), we create intermediate directories?
There was a problem hiding this comment.
And do we need this AND key name normalization as anyway, we have another config to define this behavior, which can be handled from code, instead of giving some additional meaning to the config?
There was a problem hiding this comment.
I am open to reorganize the configuration in any way. In this model the two configuration are independent. Existing config means CREATE_DIR+NORMALIZE, new config is just CREATE_DIR.
They are independent and not matrix.
But we can switch back to the original version.
There was a problem hiding this comment.
bq. Existing config means CREATE_DIR+NORMALIZE, new config is just CREATE_DIR.
Are these the only two cases that are useful? do we need to support other combinations?
There was a problem hiding this comment.
Good question, there are three useful cases IMHO:
- Do nothing (neither normalize, nor create dir) --> Ozone can be used only from S3, ofs/o3fs is inconsistent due to the missing intermediate directories (I suggest to throw exception in this case for ofs/o3fs)
- create dirs, don't normalize --> 100% AWS compatibility, partial view from ofs (invalid keys not visible from ofs. eg
/a/b/c////d) - create dirs, normalize --> reduced AWS s3 compatibility, full ofs view
The last option is: normalize but don't create dirs --> it doesn't make sense, as without creating intermediate dirs, ofs is not usable, therefore we don't need normalization.
|
|
||
| | configuration | behavior | | ||
| |-|-| | ||
| | `ozone.om.enable.filesystem.paths=true` | Enable intermediate dir generation **AND** key name normalization |
There was a problem hiding this comment.
Question: Is this config still OM config?
There was a problem hiding this comment.
I think so, but we can remove om. As it's not required to know from a config where is it used. It's an important Ozone config. But I am open to use any config name.
|
|
||
| This can be done with persisting an extra flag with the implicit directory entries. These entries can be modified if they are explicit created. | ||
|
|
||
| This flag should be added only for the keys which are created by S3. `ofs://` and `of3fs://` create explicit directories all the time. |
There was a problem hiding this comment.
These entries can be modified if they are explicit created.
Can you explain a little more about this statement?
There was a problem hiding this comment.
If any key is created from s3 interface but it already exists but explicit=false flag, the flag should be changed to explicit=true, to make it visible from s3.
There was a problem hiding this comment.
S3 should list only the
/a/b/c/dkeys, (/a,/a/b,/a/b/ckeys, created to help HCFS, won't be visible if the key is created from S3)
what if user create additional files under intermediate dirs such as /a/b/d via FS interface, we still want to show them in this case for interop?
There was a problem hiding this comment.
The compatibility story is only important when somebody uses s3 interface. S3 gateway expected to be compatible with AWS S3.
But there is no rule limtations about showing something for S3G which is created from ofs/o3fs. From this point of view ofs/o3fs are external clients which can do anything, there couldn't be any excepttations in s3g.
- Directories created by ofs/o3fs can be shown from s3 all the time
- During key S3 creation intermediate directories should be created but (by default) hidden to S3
- Unless somebody creates them with ofs interface. In those case they can be visible.
|
|
||
| Proposed behavior: | ||
|
|
||
| * `ozone.om.enable.intermediate.dirs=true`: `/y` is not accessible, `/a/b` directory doesn't contain this entry |
There was a problem hiding this comment.
/y is not accessible from FS, but will be accessible from S3 correct?
| Proposed behavior: | ||
|
|
||
| * `ozone.om.enable.intermediate.dirs=true`: `/y` is not accessible, `/a/b` directory doesn't contain this entry | ||
| * `ozone.om.enable.filesystem.paths=true`: key stored as `/a/b/c` |
There was a problem hiding this comment.
With this, visible from both, but in S3 it will be shown with normalized name?
| Proposed behavior: | ||
|
|
||
| * `ozone.om.enable.intermediate.dirs=true`: `e` and `f` are not visible | ||
| * `ozone.om.enable.filesystem.paths=true`: key stored as `/a/e` and `a/b/f` |
There was a problem hiding this comment.
Can we also add info on visibility and how it will be displayed also?
| It is possible to create directory and key with the same name in AWS: | ||
|
|
||
| ``` | ||
| aws s3api put-object --bucket ozonetest --key a/b/h --body README.md |
There was a problem hiding this comment.
hdfs dfs -mkdir -p o3fs://ozonetest.s3v/a/b/h
Need mkdir above to complete the example
There was a problem hiding this comment.
Why is it required? I think the current example defines the behavior when only s3 part is used.
|
|
||
| Proposed behavior: | ||
|
|
||
| * `ozone.om.enable.intermediate.dirs=true`: should work without error |
There was a problem hiding this comment.
Will not work, as createDirectory is putObject with 0 byte.
Refer link for more info
There was a problem hiding this comment.
I understand that we will have 0 size file with / at the end, but I propose to fix the intermediate directory creation to accept it.
| * `ozone.om.enable.intermediate.dirs=true`: should work without error | ||
| * `ozone.om.enable.filesystem.paths=true`: should work without error. | ||
|
|
||
| This is an `ofs`/`o3fs` question not an S3. The directory created in the first step shouldn't block the creation of the file. This can be a **mandatory** normalization for `mkdir` directory creation. As it's an HCFS operation, s3 is not affected. Entries created from S3 can be visible from s3 without any problem. |
There was a problem hiding this comment.
It will block ofs/o3fs also, as it is not a directory in ozone, it is a file.
There was a problem hiding this comment.
Can we change the type to a directory when it's empty and name ends with / ?
| hdfs dfs -put /tmp/file1 s3a://b12345/d11/d12/file1 | ||
| ``` | ||
|
|
||
| In this case first a `d11/d12/` key is created. The intermediate key creation logic in the second step should use it as a directory instead of throwing an exception. |
There was a problem hiding this comment.
d11/d12 is created without traiiling "/"
There was a problem hiding this comment.
I tested it locally and found the trailing /. Are you sure?
There was a problem hiding this comment.
Yes. Posted my comment in HDDS-4209. Refer for more info
There was a problem hiding this comment.
Thanks to explain it. I tested it with pure AWS S3 and s3a. The trailing / seems to be missing due to a bug in our normalization, and it's not and s3a behavior. I think we should fix the normalization.
There was a problem hiding this comment.
Thank You @elek for the design document.
My understanding from this is the draft is as below. Let me know if I am missing something here.

Correct. But this is not a matrix anymore. You should turn on either first or second of the configs, but not both. |
Not sure what is meant here, because we have 2 configs, now we can have 4 combinations according to proposal 3 are valid, 4th one is not. |
| | force to normalize key names of `s3` interface | YES | NO | ||
| | `s3` key `/a/b/c` available from `ofs/o3fs` | YES | NO | ||
| | `s3` key `/a/b//c` available from `ofs/o3fs` | YES | NO | ||
| | `s3` key `/a/b//c` available from `s3` | AWS S3 incompatibility | YES |
There was a problem hiding this comment.
Any pointer to S3 compatibility requirement? e.g., path handling, normalization, etc.
There was a problem hiding this comment.
In general, AWS S3 can save any key without normalization, and the same content can be retrieved with the same key (and list shows the raw names).
AWS S3 incompatibility: means partial incompatibility. All the s3 tools which depends on the original AWS S3 behavior can be failed. (For example if a S3 Fuse file system creates dirs with keys ending with / AND store real directory metadata on that specific key --> it will be broken).
I started to create robot tests for these cases which can be used to check this side of the compatibility:
|
|
||
| **Without normalization (`ozone.om.enable.intermediate.dirs=true`)**: | ||
|
|
||
| Creating intermediate directories might not be possible if path contains illegal characters or can't be parsed as a file system path. **These keys will be invisible from HCFS** by default. They will be ignored during the normal file list. |
There was a problem hiding this comment.
The illegal char from S3 path can be encoded into FS path except the /.
There was a problem hiding this comment.
.. also can be tricky.
But in general, I agree. We might be more permissive and show some of these elements even in ofs/o3fs. For example a/b/c//d might be possible to show as /a/b/c/d. But even if some of these are visible, we should accept that ofs/o3fs doesn't provide a full view when 100% AWS compatibility is requested.
Agree, but there are two ways to define this 3 options: 1st approach: KEY1=true,KEY2=true --> option1 2nd approach: KEY1=true --> option 1 |
Codecov Report
@@ Coverage Diff @@
## master #1411 +/- ##
============================================
+ Coverage 75.11% 75.19% +0.07%
- Complexity 10488 10497 +9
============================================
Files 990 990
Lines 50885 50885
Branches 4960 4960
============================================
+ Hits 38221 38261 +40
+ Misses 10280 10238 -42
- Partials 2384 2386 +2 Continue to review full report at Codecov.
|

|
We had an offline conversation with @bharatviswa504 @arp7 Got the feedback from Arpit: the 3rd option can be useful (we had disagreement how useful it is), but it was requested to fill the behavior in I uploaded the updated version: @arp7 Would you be so kind to have a look and give me feedback. |
|
All the questions answered here and didn't receive any new objection in the last month. I am planning to merge it if no more objections. This document describes 3 possible compatibility options and we had some debate if the 3rd option (Full s3 compatibility but limited o3fs/ofs view) is important or not. (It was important for me but others said it's not a real use case). As this document describes the expected behavior very well for case 1 and case 2 I prefer to commit it. I added one more paragraph (see #d24322ec68ca3c49181c201d1f41d18dd2b60f7f) which clarifies that the priority / implementation of the 3rd option depends on business need, and not included / and not under implementation on master. (If somebody needs it, we can show that we have a plan, and we can discuss the implementation). I hope it's an acceptable consensus. |
Please don't proceed without a binding +1. For options 1 and 2 - how is this design doc different from the one attached to HDDS-4097? |
This is a design doc, I would prefer to have a consensus not just one +1.
Can you please help me with explaining the difference. As far as I understood we agreed that it's the same. (It was not true with the first version but the handling of properties have been change since then). |
|
If options 1 and 2 are the same, why not just checkin the original design
doc and explain option 3 as a potential alternative?
…On Tue, Nov 3, 2020 at 12:34 AM Elek, Márton ***@***.***> wrote:
Please don't proceed without a binding +1.
This is a design doc, I would prefer to have a consensus not just one +1.
For options 1 and 2 - how is this design doc different from the one
attached to HDDS-4097?
Can you please help me with explaining the difference. As far as I
understood we agreed that it's the same. (It was not true with the first
version but the handling of properties have been change since then).
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
<#1411 (comment)>, or
unsubscribe
<https://github.com/notifications/unsubscribe-auth/AAS5QYP7IRNY4OGVDTI54KDSN66BRANCNFSM4RCFHLBA>
.
|
We can definitely check in the original design doc, too. I am +1 for that PR. This design doc ...
|
|
|
||
| * Out of the box Ozone should support both S3 and HCFS interfaces without any settings. (It's possible only for the regular, fs compatible key names) | ||
| * As 100% compatibility couldn't be achieved on both side we need a configuration to set the expectations for incompatible key names | ||
| * Default behavior of `o3fs` and `ofs` should be as close to `s3a` as possible (when s3 compatibilty is prefered) |
There was a problem hiding this comment.
The tradeoff here is that in this mode the FS integrity can be affected by putting invalid keys via S3. E.g. i could put key names which have elements like . and .., or key names which try to escape the root of the filesystem. I think the tradeoffs should be called out else this doc is not representing the options correctly.
There was a problem hiding this comment.
Thanks the suggestion. I added a few more sentences to make it more clear. See: bd7792f commit (or the rendered view).
|
I see multiple comments on the doc. Are all the discussion threads resolved? |
In which doc? As far as I know all the questions are answered. Please let me know If I missed something. |
|
@arp7 @bharatviswa504 Do you have any more comments? Can we merge it? |
|
@arp7 @bharatviswa504 Do you have any more comments? Can we merge it? @arp7 suggested offline merging this doc with other docs under HDDS-4097. I am not sure if it's required. All the docs under HDDS-4097 talks about the implementation details of one of the options described here (filesystem path enabled). @bharatviswa504 Let me know if you have different opinion. |
|
@bharatviswa504 Are you fine with merging this PR? I think it's good to have a global picture even if the 3rd option is not a priority right now. |
|
The doc is updated based on the agreements. It describes the three options, but the proposed new option is mentioned only as an option which can be implemented in case of real business demand:
@arp7 / @sidseth please let me know what do you think (This approach is already discussed with @mukul1987 and will be discussed with Bharat, soon). |
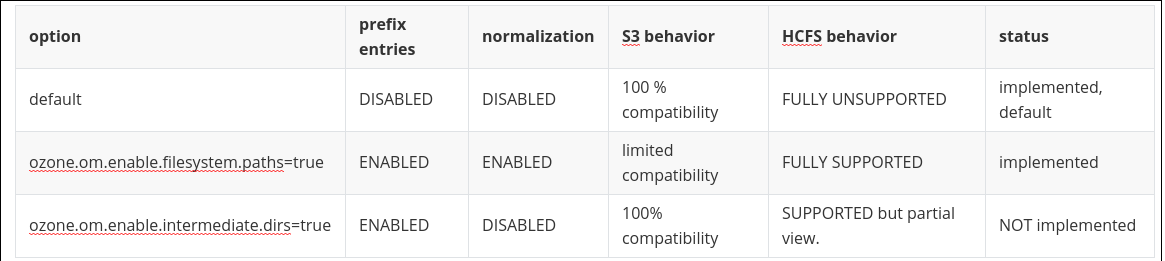
|
Ping @arp7 @bharatviswa504 @mukul1987 @swagle |
|
@elek Because V1 representation is 100% FS as it will always create intermediate dir irrespective of the normalization flag. @rakeshadr for any comments. |
This is a pull requests to the master. I think we don't need to hold off, we can commit it as it represents the state of the master. But it's a good idea to modify it with HDDS-2939 and update in case of any changes on master (HDDS-2939 merge) |
|
Closing this one due to lack of support. I am tired to ping people for answers again and again and somewhat disappointed that design conversations are so hard.... :-( Still I am strongly believe that the S3 / HCFS interoperability guarantees should be very well-defined and specified as part of the documentation (ASAP). |
What changes were proposed in this pull request?
A new design doc is included about S3/HCFS interoperability. Earlier it was discussed under https://issues.apache.org/jira/browse/HDDS-4097.
But I created this PR as: