Branch 2.3 #20185
Closed
Branch 2.3 #20185
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
## What changes were proposed in this pull request? stageAttemptId added in TaskContext and corresponding construction modification ## How was this patch tested? Added a new test in TaskContextSuite, two cases are tested: 1. Normal case without failure 2. Exception case with resubmitted stages Link to [SPARK-22897](https://issues.apache.org/jira/browse/SPARK-22897) Author: Xianjin YE <advancedxy@gmail.com> Closes #20082 from advancedxy/SPARK-22897. (cherry picked from commit a6fc300) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request? Assert if code tries to access SQLConf.get on executor. This can lead to hard to detect bugs, where the executor will read fallbackConf, falling back to default config values, ignoring potentially changed non-default configs. If a config is to be passed to executor code, it needs to be read on the driver, and passed explicitly. ## How was this patch tested? Check in existing tests. Author: Juliusz Sompolski <julek@databricks.com> Closes #20136 from juliuszsompolski/SPARK-22938. (cherry picked from commit 247a089) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… TABLE SQL statement
## What changes were proposed in this pull request?
Currently, our CREATE TABLE syntax require the EXACT order of clauses. It is pretty hard to remember the exact order. Thus, this PR is to make optional clauses order insensitive for `CREATE TABLE` SQL statement.
```
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1 col_type1 [COMMENT col_comment1], ...)]
USING datasource
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
```
The proposal is to make the following clauses order insensitive.
```
[OPTIONS (key1=val1, key2=val2, ...)]
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[LOCATION path]
[COMMENT table_comment]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
```
The same idea is also applicable to Create Hive Table.
```
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name1[:] col_type1 [COMMENT col_comment1], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION path]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
[AS select_statement]
```
The proposal is to make the following clauses order insensitive.
```
[COMMENT table_comment]
[PARTITIONED BY (col_name2[:] col_type2 [COMMENT col_comment2], ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION path]
[TBLPROPERTIES (key1=val1, key2=val2, ...)]
```
## How was this patch tested?
Added test cases
Author: gatorsmile <gatorsmile@gmail.com>
Closes #20133 from gatorsmile/createDataSourceTableDDL.
(cherry picked from commit 1a87a16)
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? When overwriting a partitioned table with dynamic partition columns, the behavior is different between data source and hive tables. data source table: delete all partition directories that match the static partition values provided in the insert statement. hive table: only delete partition directories which have data written into it This PR adds a new config to make users be able to choose hive's behavior. ## How was this patch tested? new tests Author: Wenchen Fan <wenchen@databricks.com> Closes #18714 from cloud-fan/overwrite-partition. (cherry picked from commit a66fe36) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Add a `reset` function to ensure the state in `AnalysisContext ` is per-query. ## How was this patch tested? The existing test cases Author: gatorsmile <gatorsmile@gmail.com> Closes #20127 from gatorsmile/refactorAnalysisContext.
## What changes were proposed in this pull request? * String interpolation in ml pipeline example has been corrected as per scala standard. ## How was this patch tested? * manually tested. Author: chetkhatri <ckhatrimanjal@gmail.com> Closes #20070 from chetkhatri/mllib-chetan-contrib. (cherry picked from commit 9a2b65a) Signed-off-by: Sean Owen <sowen@cloudera.com>
## What changes were proposed in this pull request? move `ColumnVector` and related classes to `org.apache.spark.sql.vectorized`, and improve the document. ## How was this patch tested? existing tests. Author: Wenchen Fan <wenchen@databricks.com> Closes #20116 from cloud-fan/column-vector. (cherry picked from commit b297029) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? `FoldablePropagation` is a little tricky as it needs to handle attributes that are miss-derived from children, e.g. outer join outputs. This rule does a kind of stop-able tree transform, to skip to apply this rule when hit a node which may have miss-derived attributes. Logically we should be able to apply this rule above the unsupported nodes, by just treating the unsupported nodes as leaf nodes. This PR improves this rule to not stop the tree transformation, but reduce the foldable expressions that we want to propagate. ## How was this patch tested? existing tests Author: Wenchen Fan <wenchen@databricks.com> Closes #20139 from cloud-fan/foldable. (cherry picked from commit 7d045c5) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…rigger, partitionBy ## What changes were proposed in this pull request? R Structured Streaming API for withWatermark, trigger, partitionBy ## How was this patch tested? manual, unit tests Author: Felix Cheung <felixcheung_m@hotmail.com> Closes #20129 from felixcheung/rwater. (cherry picked from commit df95a90) Signed-off-by: Felix Cheung <felixcheung@apache.org>
## What changes were proposed in this pull request? ChildFirstClassLoader's parent is set to null, so we can't get jars from its parent. This will cause ClassNotFoundException during HiveClient initialization with builtin hive jars, where we may should use spark context loader instead. ## How was this patch tested? add new ut cc cloud-fan gatorsmile Author: Kent Yao <yaooqinn@hotmail.com> Closes #20145 from yaooqinn/SPARK-22950. (cherry picked from commit 9fa703e) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
Currently Scala users can use UDF like
```
val foo = udf((i: Int) => Math.random() + i).asNondeterministic
df.select(foo('a))
```
Python users can also do it with similar APIs. However Java users can't do it, we should add Java UDF APIs in the functions object.
## How was this patch tested?
new tests
Author: Wenchen Fan <wenchen@databricks.com>
Closes #20141 from cloud-fan/udf.
(cherry picked from commit d5861ab)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
```Python
import random
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType, StringType
random_udf = udf(lambda: int(random.random() * 100), IntegerType()).asNondeterministic()
spark.catalog.registerFunction("random_udf", random_udf, StringType())
spark.sql("SELECT random_udf()").collect()
```
We will get the following error.
```
Py4JError: An error occurred while calling o29.__getnewargs__. Trace:
py4j.Py4JException: Method __getnewargs__([]) does not exist
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:318)
at py4j.reflection.ReflectionEngine.getMethod(ReflectionEngine.java:326)
at py4j.Gateway.invoke(Gateway.java:274)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:214)
at java.lang.Thread.run(Thread.java:745)
```
This PR is to support it.
## How was this patch tested?
WIP
Author: gatorsmile <gatorsmile@gmail.com>
Closes #20137 from gatorsmile/registerFunction.
(cherry picked from commit 5aadbc9)
Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…tDataTypes ## What changes were proposed in this pull request? This pr is a follow-up to fix a bug left in #19977. ## How was this patch tested? Added tests in `StringExpressionsSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #20149 from maropu/SPARK-22771-FOLLOWUP. (cherry picked from commit 6f68316) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…ternal shuffle service ## What changes were proposed in this pull request? This PR is the second attempt of #18684 , NIO's Files API doesn't override `skip` method for `InputStream`, so it will bring in performance issue (mentioned in #20119). But using `FileInputStream`/`FileOutputStream` will also bring in memory issue (https://dzone.com/articles/fileinputstream-fileoutputstream-considered-harmful), which is severe for long running external shuffle service. So here in this proposal, only fixing the external shuffle service related code. ## How was this patch tested? Existing tests. Author: jerryshao <sshao@hortonworks.com> Closes #20144 from jerryshao/SPARK-21475-v2. (cherry picked from commit 93f92c0) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
…ueues. The code in LiveListenerBus was queueing events before start in the queues themselves; so in situations like the following: bus.post(someEvent) bus.addToEventLogQueue(listener) bus.start() "someEvent" would not be delivered to "listener" if that was the first listener in the queue, because the queue wouldn't exist when the event was posted. This change buffers the events before starting the bus in the bus itself, so that they can be delivered to all registered queues when the bus is started. Also tweaked the unit tests to cover the behavior above. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20039 from vanzin/SPARK-22850. (cherry picked from commit d2cddc8) Signed-off-by: Imran Rashid <irashid@cloudera.com>
Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20156 from vanzin/SPARK-22948. (cherry picked from commit 95f9659) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
…container is used ## What changes were proposed in this pull request? User-specified secrets are mounted into both the main container and init-container (when it is used) in a Spark driver/executor pod, using the `MountSecretsBootstrap`. Because `MountSecretsBootstrap` always adds new secret volumes for the secrets to the pod, the same secret volumes get added twice, one when mounting the secrets to the main container, and the other when mounting the secrets to the init-container. This PR fixes the issue by separating `MountSecretsBootstrap.mountSecrets` out into two methods: `addSecretVolumes` for adding secret volumes to a pod and `mountSecrets` for mounting secret volumes to a container, respectively. `addSecretVolumes` is only called once for each pod, whereas `mountSecrets` is called individually for the main container and the init-container (if it is used). Ref: apache-spark-on-k8s#594. ## How was this patch tested? Unit tested and manually tested. vanzin This replaces #20148. hex108 foxish kimoonkim Author: Yinan Li <liyinan926@gmail.com> Closes #20159 from liyinan926/master. (cherry picked from commit e288fc8) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
- Make it possible to build images from a git clone. - Make it easy to use minikube to test things. Also fixed what seemed like a bug: the base image wasn't getting the tag provided in the command line. Adding the tag allows users to use multiple Spark builds in the same kubernetes cluster. Tested by deploying images on minikube and running spark-submit from a dev environment; also by building the images with different tags and verifying "docker images" in minikube. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #20154 from vanzin/SPARK-22960. (cherry picked from commit 0428368) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? 32bit Int was used for row rank. That overflowed in a dataframe with more than 2B rows. ## How was this patch tested? Added test, but ignored, as it takes 4 minutes. Author: Juliusz Sompolski <julek@databricks.com> Closes #20152 from juliuszsompolski/SPARK-22957. (cherry picked from commit df7fc3e) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request?
This pr fixed the issue when casting arrays into strings;
```
scala> val df = spark.range(10).select('id.cast("integer")).agg(collect_list('id).as('ids))
scala> df.write.saveAsTable("t")
scala> sql("SELECT cast(ids as String) FROM t").show(false)
+------------------------------------------------------------------+
|ids |
+------------------------------------------------------------------+
|org.apache.spark.sql.catalyst.expressions.UnsafeArrayData8bc285df|
+------------------------------------------------------------------+
```
This pr modified the result into;
```
+------------------------------+
|ids |
+------------------------------+
|[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]|
+------------------------------+
```
## How was this patch tested?
Added tests in `CastSuite` and `SQLQuerySuite`.
Author: Takeshi Yamamuro <yamamuro@apache.org>
Closes #20024 from maropu/SPARK-22825.
(cherry picked from commit 52fc5c1)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… memory tradeoff for TrainValidationSplit ## What changes were proposed in this pull request? Avoid holding all models in memory for `TrainValidationSplit`. ## How was this patch tested? Existing tests. Author: Bago Amirbekian <bago@databricks.com> Closes #20143 from MrBago/trainValidMemoryFix. (cherry picked from commit cf0aa65) Signed-off-by: Joseph K. Bradley <joseph@databricks.com>
## What changes were proposed in this pull request? We missed enabling `spark.files` and `spark.jars` in #19954. The result is that remote dependencies specified through `spark.files` or `spark.jars` are not included in the list of remote dependencies to be downloaded by the init-container. This PR fixes it. ## How was this patch tested? Manual tests. vanzin This replaces #20157. foxish Author: Yinan Li <liyinan926@gmail.com> Closes #20160 from liyinan926/SPARK-22757. (cherry picked from commit 6cff7d1) Signed-off-by: Felix Cheung <felixcheung@apache.org>
…onstraints ## What changes were proposed in this pull request? #19201 introduced the following regression: given something like `df.withColumn("c", lit(2))`, we're no longer picking up `c === 2` as a constraint and infer filters from it when joins are involved, which may lead to noticeable performance degradation. This patch re-enables this optimization by picking up Aliases of Literals in Projection lists as constraints and making sure they're not treated as aliased columns. ## How was this patch tested? Unit test was added. Author: Adrian Ionescu <adrian@databricks.com> Closes #20155 from adrian-ionescu/constant_constraints. (cherry picked from commit 51c33bd) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
… platforms that don't have wget ## What changes were proposed in this pull request? Modified HiveExternalCatalogVersionsSuite.scala to use Utils.doFetchFile to download different versions of Spark binaries rather than launching wget as an external process. On platforms that don't have wget installed, this suite fails with an error. cloud-fan : would you like to check this change? ## How was this patch tested? 1) test-only of HiveExternalCatalogVersionsSuite on several platforms. Tested bad mirror, read timeout, and redirects. 2) ./dev/run-tests Author: Bruce Robbins <bersprockets@gmail.com> Closes #20147 from bersprockets/SPARK-22940-alt. (cherry picked from commit c0b7424) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? Follow-up cleanups for the OneHotEncoderEstimator PR. See some discussion in the original PR: #19527 or read below for what this PR includes: * configedCategorySize: I reverted this to return an Array. I realized the original setup (which I had recommended in the original PR) caused the whole model to be serialized in the UDF. * encoder: I reorganized the logic to show what I meant in the comment in the previous PR. I think it's simpler but am open to suggestions. I also made some small style cleanups based on IntelliJ warnings. ## How was this patch tested? Existing unit tests Author: Joseph K. Bradley <joseph@databricks.com> Closes #20132 from jkbradley/viirya-SPARK-13030. (cherry picked from commit 930b90a) Signed-off-by: Joseph K. Bradley <joseph@databricks.com>
## What changes were proposed in this pull request? Register spark.history.ui.port as a known spark conf to be used in substitution expressions even if it's not set explicitly. ## How was this patch tested? Added unit test to demonstrate the issue Author: Gera Shegalov <gera@apache.org> Author: Gera Shegalov <gshegalov@salesforce.com> Closes #20098 from gerashegalov/gera/register-SHS-port-conf. (cherry picked from commit ea95683) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? This pr modified `elt` to output binary for binary inputs. `elt` in the current master always output data as a string. But, in some databases (e.g., MySQL), if all inputs are binary, `elt` also outputs binary (Also, this might be a small surprise). This pr is related to #19977. ## How was this patch tested? Added tests in `SQLQueryTestSuite` and `TypeCoercionSuite`. Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #20135 from maropu/SPARK-22937. (cherry picked from commit e8af7e8) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? This PR reverts the `ARG base_image` before `FROM` in the images of driver, executor, and init-container, introduced in #20154. The reason is Docker versions before 17.06 do not support this use (`ARG` before `FROM`). ## How was this patch tested? Tested manually. vanzin foxish kimoonkim Author: Yinan Li <liyinan926@gmail.com> Closes #20170 from liyinan926/master. (cherry picked from commit bf65cd3) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
… for non-deterministic cases ## What changes were proposed in this pull request? Add tests for using non deterministic UDFs in aggregate. Update pandas_udf docstring w.r.t to determinism. ## How was this patch tested? test_nondeterministic_udf_in_aggregate Author: Li Jin <ice.xelloss@gmail.com> Closes #20142 from icexelloss/SPARK-22930-pandas-udf-deterministic. (cherry picked from commit f2dd8b9) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
# What changes were proposed in this pull request? 1. Start HiveThriftServer2. 2. Connect to thriftserver through beeline. 3. Close the beeline. 4. repeat step2 and step 3 for many times. we found there are many directories never be dropped under the path `hive.exec.local.scratchdir` and `hive.exec.scratchdir`, as we know the scratchdir has been added to deleteOnExit when it be created. So it means that the cache size of FileSystem `deleteOnExit` will keep increasing until JVM terminated. In addition, we use `jmap -histo:live [PID]` to printout the size of objects in HiveThriftServer2 Process, we can find the object `org.apache.spark.sql.hive.client.HiveClientImpl` and `org.apache.hadoop.hive.ql.session.SessionState` keep increasing even though we closed all the beeline connections, which may caused the leak of Memory. # How was this patch tested? manual tests This PR follw-up the #19989 Author: zuotingbing <zuo.tingbing9@zte.com.cn> Closes #20029 from zuotingbing/SPARK-22793. (cherry picked from commit be9a804) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…rrowColumnVector ## What changes were proposed in this pull request? This PR changes usage of `MapVector` in Spark codebase to use `NullableMapVector`. `MapVector` is an internal Arrow class that is not supposed to be used directly. We should use `NullableMapVector` instead. ## How was this patch tested? Existing test. Author: Li Jin <ice.xelloss@gmail.com> Closes #20239 from icexelloss/arrow-map-vector. (cherry picked from commit 4e6f8fb) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
## What changes were proposed in this pull request? This PR proposes to actually run the doctests in `ml/image.py`. ## How was this patch tested? doctests in `python/pyspark/ml/image.py`. Author: hyukjinkwon <gurwls223@gmail.com> Closes #20294 from HyukjinKwon/trigger-image. (cherry picked from commit 45ad97d) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
## What changes were proposed in this pull request? - Added `InterfaceStability.Evolving` annotations - Improved docs. ## How was this patch tested? Existing tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20286 from tdas/SPARK-23119. (cherry picked from commit bac0d66) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
## What changes were proposed in this pull request? Added documentation for stream-stream joins     ## How was this patch tested? N/a Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20255 from tdas/join-docs. (cherry picked from commit 1002bd6) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
## What changes were proposed in this pull request? Structured streaming is now able to read files with space in file name (previously it would skip the file and output a warning) ## How was this patch tested? Added new unit test. Author: Xiayun Sun <xiayunsun@gmail.com> Closes #19247 from xysun/SPARK-21996. (cherry picked from commit 0219470) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
… and Catalog in PySpark ## What changes were proposed in this pull request? This PR proposes to deprecate `register*` for UDFs in `SQLContext` and `Catalog` in Spark 2.3.0. These are inconsistent with Scala / Java APIs and also these basically do the same things with `spark.udf.register*`. Also, this PR moves the logcis from `[sqlContext|spark.catalog].register*` to `spark.udf.register*` and reuse the docstring. This PR also handles minor doc corrections. It also includes #20158 ## How was this patch tested? Manually tested, manually checked the API documentation and tests added to check if deprecated APIs call the aliases correctly. Author: hyukjinkwon <gurwls223@gmail.com> Closes #20288 from HyukjinKwon/deprecate-udf. (cherry picked from commit 39d244d) Signed-off-by: Takuya UESHIN <ueshin@databricks.com>
## What changes were proposed in this pull request? Migrate ConsoleSink to data source V2 api. Note that this includes a missing piece in DataStreamWriter required to specify a data source V2 writer. Note also that I've removed the "Rerun batch" part of the sink, because as far as I can tell this would never have actually happened. A MicroBatchExecution object will only commit each batch once for its lifetime, and a new MicroBatchExecution object would have a new ConsoleSink object which doesn't know it's retrying a batch. So I think this represents an anti-feature rather than a weakness in the V2 API. ## How was this patch tested? new unit test Author: Jose Torres <jose@databricks.com> Closes #20243 from jose-torres/console-sink. (cherry picked from commit 1c76a91) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
…lanner ## What changes were proposed in this pull request? `DataSourceV2Strategy` is missing in `HiveSessionStateBuilder`'s planner, which will throw exception as described in [SPARK-23140](https://issues.apache.org/jira/browse/SPARK-23140). ## How was this patch tested? Manual test. Author: jerryshao <sshao@hortonworks.com> Closes #20305 from jerryshao/SPARK-23140. (cherry picked from commit 7a22483) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…ften returns NULL ## What changes were proposed in this pull request? When there is an operation between Decimals and the result is a number which is not representable exactly with the result's precision and scale, Spark is returning `NULL`. This was done to reflect Hive's behavior, but it is against SQL ANSI 2011, which states that "If the result cannot be represented exactly in the result type, then whether it is rounded or truncated is implementation-defined". Moreover, Hive now changed its behavior in order to respect the standard, thanks to HIVE-15331. Therefore, the PR propose to: - update the rules to determine the result precision and scale according to the new Hive's ones introduces in HIVE-15331; - round the result of the operations, when it is not representable exactly with the result's precision and scale, instead of returning `NULL` - introduce a new config `spark.sql.decimalOperations.allowPrecisionLoss` which default to `true` (ie. the new behavior) in order to allow users to switch back to the previous one. Hive behavior reflects SQLServer's one. The only difference is that the precision and scale are adjusted for all the arithmetic operations in Hive, while SQL Server is said to do so only for multiplications and divisions in the documentation. This PR follows Hive's behavior. A more detailed explanation is available here: https://mail-archives.apache.org/mod_mbox/spark-dev/201712.mbox/%3CCAEorWNAJ4TxJR9NBcgSFMD_VxTg8qVxusjP%2BAJP-x%2BJV9zH-yA%40mail.gmail.com%3E. ## How was this patch tested? modified and added UTs. Comparisons with results of Hive and SQLServer. Author: Marco Gaido <marcogaido91@gmail.com> Closes #20023 from mgaido91/SPARK-22036. (cherry picked from commit e28eb43) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…for registerJavaFunction. ## What changes were proposed in this pull request? Currently `UDFRegistration.registerJavaFunction` doesn't support data type string as a `returnType` whereas `UDFRegistration.register`, `udf`, or `pandas_udf` does. We can support it for `UDFRegistration.registerJavaFunction` as well. ## How was this patch tested? Added a doctest and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20307 from ueshin/issues/SPARK-23141. (cherry picked from commit 5063b74) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
|
Can one of the admins verify this patch? |
## What changes were proposed in this pull request?
Stage's task page table will throw an exception when there's no complete tasks. Furthermore, because the `dataSize` doesn't take running tasks into account, so sometimes UI cannot show the running tasks. Besides table will only be displayed when first task is finished according to the default sortColumn("index").
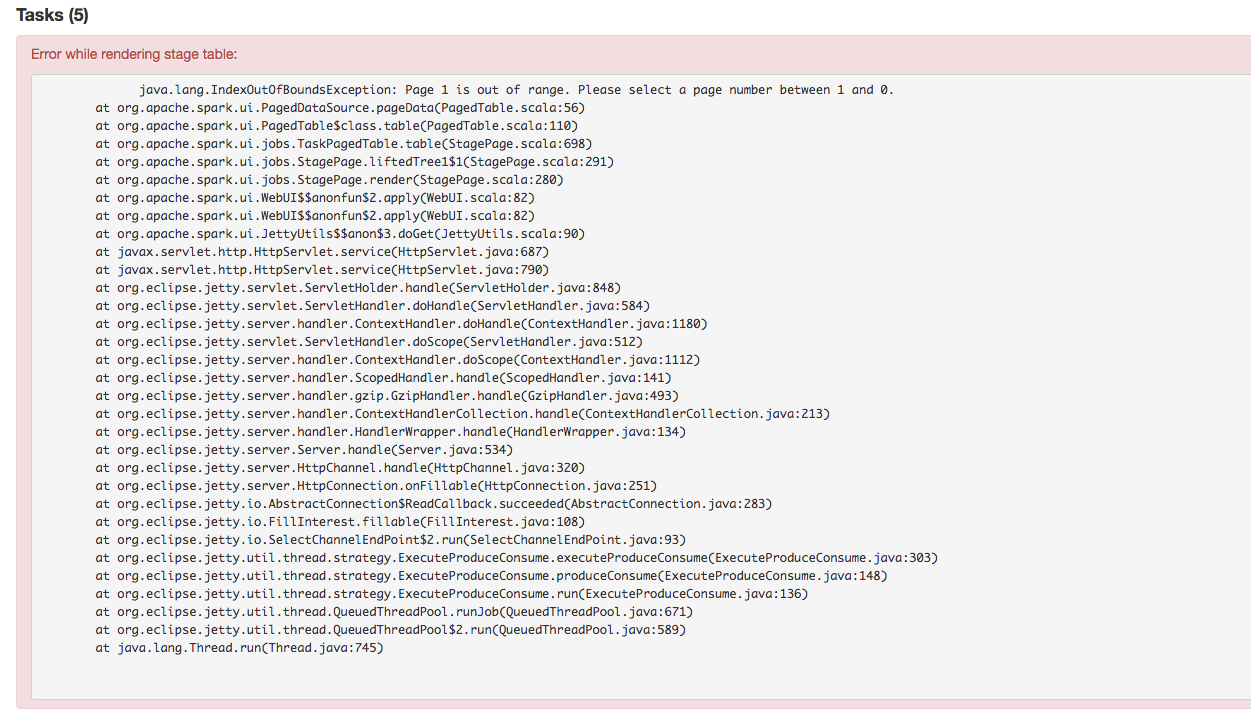
To reproduce this issue, user could try `sc.parallelize(1 to 20, 20).map { i => Thread.sleep(10000); i }.collect()` or `sc.parallelize(1 to 20, 20).map { i => Thread.sleep((20 - i) * 1000); i }.collect` to reproduce the above issue.
Here propose a solution to fix it. Not sure if it is a right fix, please help to review.
## How was this patch tested?
Manual test.
Author: jerryshao <sshao@hortonworks.com>
Closes #20315 from jerryshao/SPARK-23147.
(cherry picked from commit cf7ee17)
Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
{kind=link}
## What changes were proposed in this pull request? This PR completes the docs, specifying the default units assumed in configuration entries of type size. This is crucial since unit-less values are accepted and the user might assume the base unit is bytes, which in most cases it is not, leading to hard-to-debug problems. ## How was this patch tested? This patch updates only documentation only. Author: Fernando Pereira <fernando.pereira@epfl.ch> Closes #20269 from ferdonline/docs_units. (cherry picked from commit 9678941) Signed-off-by: Sean Owen <sowen@cloudera.com>
…gger ## What changes were proposed in this pull request? Self-explanatory. ## How was this patch tested? New python tests. Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20309 from tdas/SPARK-23143. (cherry picked from commit 2d41f04) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
## What changes were proposed in this pull request? Refactored ConsoleWriter into ConsoleMicrobatchWriter and ConsoleContinuousWriter. ## How was this patch tested? new unit test Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20311 from tdas/SPARK-23144. (cherry picked from commit bf34d66) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
Pass through spark java options to the executor in context of docker image. Closes #20296 andrusha: Deployed two version of containers to local k8s, checked that java options were present in the updated image on the running executor. Manual test Author: Andrew Korzhuev <korzhuev@andrusha.me> Closes #20322 from foxish/patch-1. (cherry picked from commit f568e9c) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? There were two related fixes regarding `from_json`, `get_json_object` and `json_tuple` ([Fix #1](c8803c0), [Fix #2](86174ea)), but they weren't comprehensive it seems. I wanted to extend those fixes to all the parsers, and add tests for each case. ## How was this patch tested? Regression tests Author: Burak Yavuz <brkyvz@gmail.com> Closes #20302 from brkyvz/json-invfix. (cherry picked from commit e01919e) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
## What changes were proposed in this pull request? In the Kubernetes mode, fails fast in the submission process if any submission client local dependencies are used as the use case is not supported yet. ## How was this patch tested? Unit tests, integration tests, and manual tests. vanzin foxish Author: Yinan Li <liyinan926@gmail.com> Closes #20320 from liyinan926/master. (cherry picked from commit 5d7c4ba) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
## What changes were proposed in this pull request? Added documentation for continuous processing. Modified two locations. - Modified the overview to have a mention of Continuous Processing. - Added a new section on Continuous Processing at the end.   ## How was this patch tested? N/A Author: Tathagata Das <tathagata.das1565@gmail.com> Closes #20308 from tdas/SPARK-23142. (cherry picked from commit 4cd2ecc) Signed-off-by: Tathagata Das <tathagata.das1565@gmail.com>
{kind=link}
{kind=link}
…integration document ## What changes were proposed in this pull request? In latest structured-streaming-kafka-integration document, Java code example for Kafka integration is using `DataFrame<Row>`, shouldn't it be changed to `DataSet<Row>`? ## How was this patch tested? manual test has been performed to test the updated example Java code in Spark 2.2.1 with Kafka 1.0 Author: brandonJY <brandonJY@users.noreply.github.com> Closes #20312 from brandonJY/patch-2. (cherry picked from commit 6121e91) Signed-off-by: Sean Owen <sowen@cloudera.com>
…g PythonUserDefinedType to String. ## What changes were proposed in this pull request? This is a follow-up of #20246. If a UDT in Python doesn't have its corresponding Scala UDT, cast to string will be the raw string of the internal value, e.g. `"org.apache.spark.sql.catalyst.expressions.UnsafeArrayDataxxxxxxxx"` if the internal type is `ArrayType`. This pr fixes it by using its `sqlType` casting. ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20306 from ueshin/issues/SPARK-23054/fup1. (cherry picked from commit 568055d) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request? This patch fixes a few recently introduced java style check errors in master and release branch. As an aside, given that [java linting currently fails](#10763 ) on machines with a clean maven cache, it'd be great to find another workaround to [re-enable the java style checks](https://github.com/apache/spark/blob/3a07eff5af601511e97a05e6fea0e3d48f74c4f0/dev/run-tests.py#L577) as part of Spark PRB. /cc zsxwing JoshRosen srowen for any suggestions ## How was this patch tested? Manual Check Author: Sameer Agarwal <sameerag@apache.org> Closes #20323 from sameeragarwal/java. (cherry picked from commit 9c4b998) Signed-off-by: Sameer Agarwal <sameerag@apache.org>
…ameter Update user guide entry for `FeatureHasher` to match the Scala / Python doc, to describe the `categoricalCols` parameter. ## How was this patch tested? Doc only Author: Nick Pentreath <nickp@za.ibm.com> Closes #20293 from MLnick/SPARK-23127-catCol-userguide. (cherry picked from commit 60203fc) Signed-off-by: Nick Pentreath <nickp@za.ibm.com>
## What changes were proposed in this pull request? We have `OneHotEncoderEstimator` now and `OneHotEncoder` will be deprecated since 2.3.0. We should add `OneHotEncoderEstimator` into mllib document. We also need to provide corresponding examples for `OneHotEncoderEstimator` which are used in the document too. ## How was this patch tested? Existing tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #20257 from viirya/SPARK-23048. (cherry picked from commit b743664) Signed-off-by: Nick Pentreath <nickp@za.ibm.com>
## What changes were proposed in this pull request? When creating a session directory, Thrift should create the parent directory (i.e. /tmp/base_session_log_dir) if it is not present. It is common that many tools delete empty directories, so the directory may be deleted. This can cause the session log to be disabled. This was fixed in HIVE-12262: this PR brings it in Spark too. ## How was this patch tested? manual tests Author: Marco Gaido <marcogaido91@gmail.com> Closes #20281 from mgaido91/SPARK-23089. (cherry picked from commit e41400c) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…oning ## What changes were proposed in this pull request? After session cloning in `TestHive`, the conf of the singleton SparkContext for derby DB location is changed to a new directory. The new directory is created in `HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false)`. This PR is to keep the conf value of `ConfVars.METASTORECONNECTURLKEY.varname` unchanged during the session clone. ## How was this patch tested? The issue can be reproduced by the command: > build/sbt -Phive "hive/test-only org.apache.spark.sql.hive.HiveSessionStateSuite org.apache.spark.sql.hive.DataSourceWithHiveMetastoreCatalogSuite" Also added a test case. Author: gatorsmile <gatorsmile@gmail.com> Closes #20328 from gatorsmile/fixTestFailure. (cherry picked from commit 6c39654) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request? Several cleanups in `ColumnarBatch` * remove `schema`. The `ColumnVector`s inside `ColumnarBatch` already have the data type information, we don't need this `schema`. * remove `capacity`. `ColumnarBatch` is just a wrapper of `ColumnVector`s, not builders, it doesn't need a capacity property. * remove `DEFAULT_BATCH_SIZE`. As a wrapper, `ColumnarBatch` can't decide the batch size, it should be decided by the reader, e.g. parquet reader, orc reader, cached table reader. The default batch size should also be defined by the reader. ## How was this patch tested? existing tests. Author: Wenchen Fan <wenchen@databricks.com> Closes #20316 from cloud-fan/columnar-batch. (cherry picked from commit d8aaa77) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Docs changes: - Adding a warning that the backend is experimental. - Removing a defunct internal-only option from documentation - Clarifying that node selectors can be used right away, and other minor cosmetic changes ## How was this patch tested? Docs only change Author: foxish <ramanathana@google.com> Closes #20314 from foxish/ambiguous-docs. (cherry picked from commit 73d3b23) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.