[SPARK-26457] Show hadoop configurations in HistoryServer environment tab #23486
Conversation
|
Could you attach a screenshot? to see what the new properties look like. Thanks!! |
| @@ -442,9 +443,13 @@ object SparkEnv extends Logging { | |||
| val addedJarsAndFiles = (addedJars ++ addedFiles).map((_, "Added By User")) | |||
| val classPaths = (addedJarsAndFiles ++ classPathEntries).sorted | |||
|
|
|||
| // Add Hadoop properties, it will ignore configs including in Spark | |||
| val hadoopProperties = hadoopConf.asScala.filter(entry => !conf.contains("spark.hadoop." + entry.getKey)). | |||
There was a problem hiding this comment.
Why do you exclude "spark.hadoop" conf? it could be posible that they are showing in spark properties?
There was a problem hiding this comment.
Yes, these properties have been shown above. So I remove it in hadoop properties.
|
@planga82 Thank you for your reply! Sure! Here it is!
|
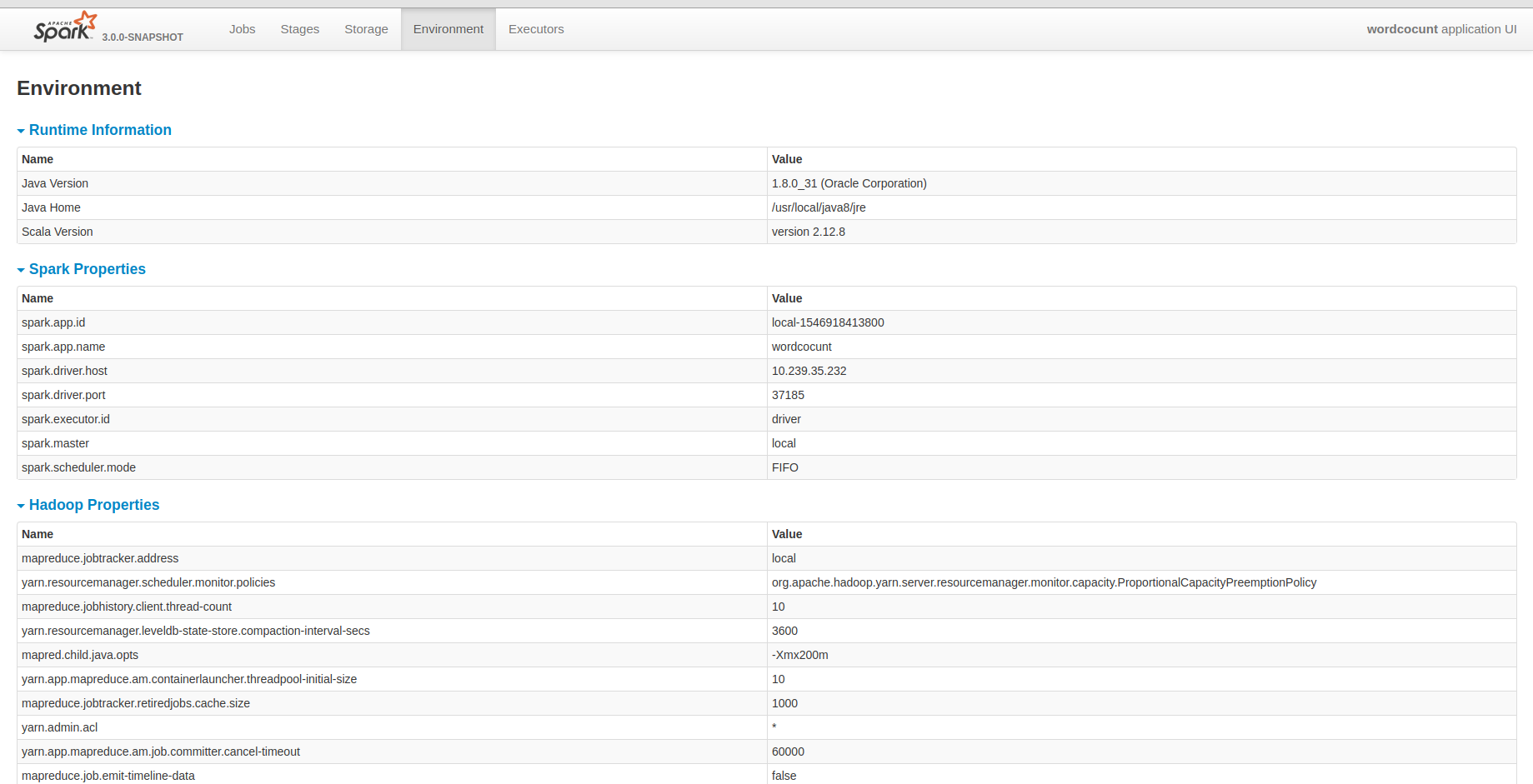
|
what happens if there are not hadoop options? I was thinking about a standalone scenario or Mesos scenario. |
|
@planga82 |
|
@deshanxiao |
| @@ -442,9 +445,13 @@ object SparkEnv extends Logging { | |||
| val addedJarsAndFiles = (addedJars ++ addedFiles).map((_, "Added By User")) | |||
| val classPaths = (addedJarsAndFiles ++ classPathEntries).sorted | |||
|
|
|||
| // Add Hadoop properties, it will ignore configs including in Spark | |||
| val hadoopProperties = hadoopConf.asScala.filter(entry => !conf.contains("spark.hadoop." + entry.getKey)). | |||
There was a problem hiding this comment.
instead of conf.contains, use startsWith?
There was a problem hiding this comment.
I actually don't think we should filter them - if I am trying to debug why the config is not getting picked up it's useful to see everyone listed here
There was a problem hiding this comment.
@felixcheung Yes, I argee with you. I will remove it.
| @@ -352,6 +352,7 @@ class VersionInfo private[spark]( | |||
| class ApplicationEnvironmentInfo private[spark] ( | |||
| val runtime: RuntimeInfo, | |||
| val sparkProperties: Seq[(String, String)], | |||
| val hadoopProperties: Seq[(String, String)], | |||
There was a problem hiding this comment.
I tried running the SHS with previous event logs, it seems that the API change will cause json parse exception.
There was a problem hiding this comment.
Yes, you are right. Thank you! I have repaired it.
|
@srowen @shahidki31 Could you give me some suggestions? |
|
@srowen Thank you! These sections can be collapsed. By default, it's not. Maybe the default style could keep in line with other properties. |
|
ok to test |
|
+1 for Sean's opinion. I think it's okie too but I'm a bit worried if the hadoop configurations looks overwhelming in that page. |
|
Test build #101221 has finished for PR 23486 at commit
|
| @@ -352,6 +352,7 @@ class VersionInfo private[spark]( | |||
| class ApplicationEnvironmentInfo private[spark] ( | |||
| val runtime: RuntimeInfo, | |||
| val sparkProperties: Seq[(String, String)], | |||
| val hadoopProperties: Seq[(String, String)], | |||
There was a problem hiding this comment.
Looks it breaks mima but the constructor is private. Let's exclude it in mima. See the Jenkins test messages.
There was a problem hiding this comment.
Thank you! I will try it.
|
Retest please. |
|
Test build #101226 has finished for PR 23486 at commit
|
|
@deshanxiao I wonder if it's easy enough to make this or even other sections besides Spark properties collapsed by default in the HTML here too |
| @@ -220,6 +220,9 @@ object MimaExcludes { | |||
| // [SPARK-26139] Implement shuffle write metrics in SQL | |||
| ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.ShuffleDependency.this"), | |||
|
|
|||
| // [SPARK-26457] Show hadoop configurations in HistoryServer environment tab | |||
There was a problem hiding this comment.
I wonder if this changes any user-facing API then? if it's something people might use anywhere, I'd keep the constructor
There was a problem hiding this comment.
OK, maybe regarding hadoopConf as an optional parameters will be better.
|
@srowen Yes, it looks like not difficult. I will make other properties collapsed by default. |
|
Test build #101295 has finished for PR 23486 at commit
|
|
Test build #101293 has finished for PR 23486 at commit
|
|
Test build #101294 has finished for PR 23486 at commit
|
|
Test build #101296 has finished for PR 23486 at commit
|
|
I try to make these properties collapsed by default. It looks like:
|

|
Test build #101298 has finished for PR 23486 at commit
|
|
Test build #101299 has finished for PR 23486 at commit
|
There was a problem hiding this comment.
You'll have to resolve the MiMa warning:
[error] * method this(org.apache.spark.status.api.v1.RuntimeInfo,scala.collection.Seq,scala.collection.Seq,scala.collection.Seq)Unit in class org.apache.spark.status.api.v1.ApplicationEnvironmentInfo does not have a correspondent in current version
[error] filter with: ProblemFilters.exclude[DirectMissingMethodProblem]("org.apache.spark.status.api.v1.ApplicationEnvironmentInfo.this")
| <a>System Properties</a> | ||
| </h4> | ||
| </span> | ||
| <div class="aggregated-systemProperties collapsible-table"> | ||
| <div class="aggregated-systemProperties collapsible-table collapsed"> |
There was a problem hiding this comment.
Nice, so only the Spark properties and system info are expanded by default? that sounds good.
There was a problem hiding this comment.
Yes, but collapseTablePageLoad in web.js may remember actions once expanded it.
|
Test build #101339 has finished for PR 23486 at commit
|
|
Retest please. |
|
Test build #101340 has finished for PR 23486 at commit
|
|
Test build #101341 has finished for PR 23486 at commit
|
|
Merged to master |
|
Thank you! @planga82 @gengliangwang @felixcheung @srowen @HyukjinKwon |
… tab ## What changes were proposed in this pull request? I know that yarn provided all hadoop configurations. But I guess it may be fine that the historyserver unify all configuration in it. It will be convenient for us to debug some problems. ## How was this patch tested?  Closes apache#23486 from deshanxiao/spark-26457. Lead-authored-by: xiaodeshan <xiaodeshan@xiaomi.com> Co-authored-by: deshanxiao <42019462+deshanxiao@users.noreply.github.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
What changes were proposed in this pull request?
I know that yarn provided all hadoop configurations. But I guess it may be fine that the historyserver unify all configuration in it. It will be convenient for us to debug some problems.
How was this patch tested?