[WIP][SPARK-33124][SQL][DOCS] Adds a group tag in all the expressions for built-in functions #30040
Conversation
|
@maropu , I did the first steps, but I need some extra input. It seems, that the The one in SQL reference looks much better (although here is no grouping): |
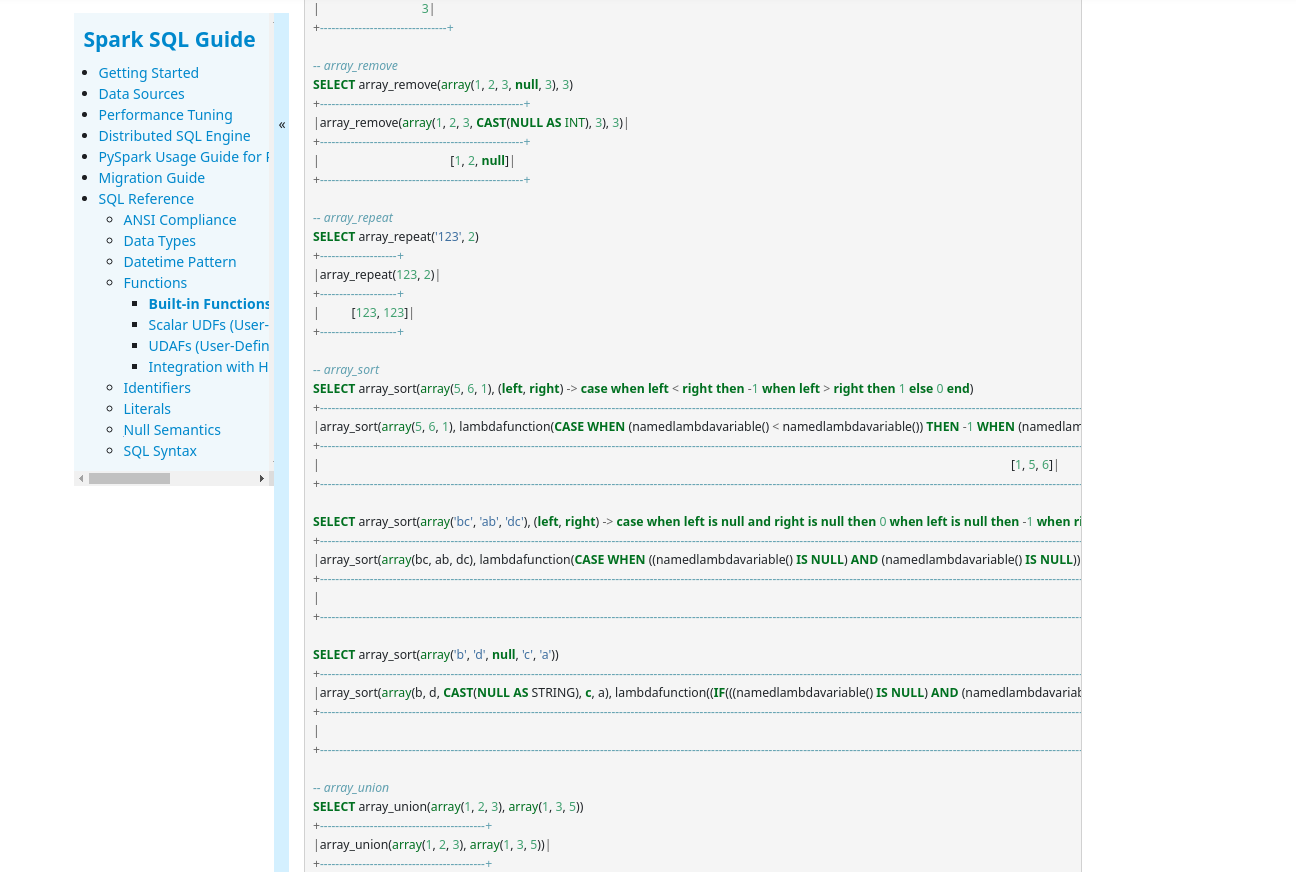

| new HashSet<>(Arrays.asList("agg_funcs", "array_funcs", "binary_funcs", "bitwise_funcs", | ||
| "comparison_funcs", "conditional_funcs", "conversion_funcs", "csv_funcs", | ||
| "datetime_funcs", "generator_funcs", "grouping_funcs", "json_funcs", "logical_funcs", | ||
| "map_funcs", "math_funcs", "misc_funcs", "regex_funcs", "string_funcs", "struct_funcs", | ||
| "window_funcs", "xml_funcs")); |
There was a problem hiding this comment.
I tried to follow the way Presto has classified its functions, but all this is up for a change.
There was a problem hiding this comment.
I was also considering making these values constants:
String GROUP_AGG_FUNCS = "agg_funcs";
String GROUP_ARRAY_FUNCS = "array_funcs";
String GROUP_BINARY_FUNCS = "binary_funcs";
...
Perhaps in the ExpressionDescription interface, but I'm not 100% sure if its better.
There was a problem hiding this comment.
hm, I see. Adding the constraints look okay because they make it easier to track these groups on IDEs, I think.
| since = "1.5.0", | ||
| group = "array_funcs") | ||
| case class Size(child: Expression, legacySizeOfNull: Boolean) | ||
| extends UnaryExpression with ExpectsInputTypes { |
There was a problem hiding this comment.
Size is one of the more problematic ones - should it be an array_func or a map_func or better yet both?
There are more like this
There was a problem hiding this comment.
hm, I see. Another idea: how about making a group for more general cases, e.g., collection_funcs? cc: @HyukjinKwon
There was a problem hiding this comment.
Seems like size is collection_funcs in functions.scala. I think we can just stick to it.
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #129745 has finished for PR 30040 at commit
|
|
Pretty nice, thanks a lot, @tanelk ! cc: @HyukjinKwon
Yea, I think so. How about adding an alias name for these examples? |
|
Yeah .. we need to make that |
|
@tanelk Are you still working on this? |
I haven't work on it for a while, but I'll get back to it this week. |
# Conflicts: # sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/arithmetic.scala # sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala # sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/stringExpressions.scala
|
Test build #131935 has finished for PR 30040 at commit
|
| @@ -145,12 +148,16 @@ def _make_pretty_examples(jspark, infos): | |||
|
|
|||
| pretty_output = "" | |||
| for info in infos: | |||
| if info.name == 'raise_error': | |||
| # TODO: how to handle this | |||
|
@tanelk Is it difficult to keep working on this? If so, I can take this over. |
Yeah, I think it would be best if you would take this over. For the most parts I would have had to consult with you anyways. |
…e group tags for built-in functions ### What changes were proposed in this pull request? This PR proposes to fill missing group tags and re-categorize all the group tags for built-in functions. New groups below are added in this PR: - binary_funcs - bitwise_funcs - collection_funcs - predicate_funcs - conditional_funcs - conversion_funcs - csv_funcs - generator_funcs - hash_funcs - lambda_funcs - math_funcs - misc_funcs - string_funcs - struct_funcs - xml_funcs A basic policy to re-categorize functions is that functions in the same file are categorized into the same group. For example, all the functions in `hash.scala` are categorized into `hash_funcs`. But, there are some exceptional/ambiguous cases when categorizing them. Here are some special notes: - All the aggregate functions are categorized into `agg_funcs`. - `array_funcs` and `map_funcs` are sub-groups of `collection_funcs`. For example, `array_contains` is used only for arrays, so it is assigned to `array_funcs`. On the other hand, `reverse` is used for both arrays and strings, so it is assigned to `collection_funcs`. - Some functions logically belong to multiple groups. In this case, these functions are categorized based on the file that they belong to. For example, `schema_of_csv` can be grouped into both `csv_funcs` and `struct_funcs` in terms of input types, but it is assigned to `csv_funcs` because it belongs to the `csvExpressions.scala` file that holds the other CSV-related functions. - Functions in `nullExpressions.scala`, `complexTypeCreator.scala`, `randomExpressions.scala`, and `regexExpressions.scala` are categorized based on their functionalities. For example: - `isnull` in `nullExpressions` is assigned to `predicate_funcs` because this is a predicate function. - `array` in `complexTypeCreator.scala` is assigned to `array_funcs`based on its output type (The other functions in `array_funcs` are categorized based on their input types though). A category list (after this PR) is as follows (the list below includes the exprs that already have a group tag in the current master): |group|name|class| |-----|----|-----| |agg_funcs|any|org.apache.spark.sql.catalyst.expressions.aggregate.BoolOr| |agg_funcs|approx_count_distinct|org.apache.spark.sql.catalyst.expressions.aggregate.HyperLogLogPlusPlus| |agg_funcs|approx_percentile|org.apache.spark.sql.catalyst.expressions.aggregate.ApproximatePercentile| |agg_funcs|avg|org.apache.spark.sql.catalyst.expressions.aggregate.Average| |agg_funcs|bit_and|org.apache.spark.sql.catalyst.expressions.aggregate.BitAndAgg| |agg_funcs|bit_or|org.apache.spark.sql.catalyst.expressions.aggregate.BitOrAgg| |agg_funcs|bit_xor|org.apache.spark.sql.catalyst.expressions.aggregate.BitXorAgg| |agg_funcs|bool_and|org.apache.spark.sql.catalyst.expressions.aggregate.BoolAnd| |agg_funcs|bool_or|org.apache.spark.sql.catalyst.expressions.aggregate.BoolOr| |agg_funcs|collect_list|org.apache.spark.sql.catalyst.expressions.aggregate.CollectList| |agg_funcs|collect_set|org.apache.spark.sql.catalyst.expressions.aggregate.CollectSet| |agg_funcs|corr|org.apache.spark.sql.catalyst.expressions.aggregate.Corr| |agg_funcs|count_if|org.apache.spark.sql.catalyst.expressions.aggregate.CountIf| |agg_funcs|count_min_sketch|org.apache.spark.sql.catalyst.expressions.aggregate.CountMinSketchAgg| |agg_funcs|count|org.apache.spark.sql.catalyst.expressions.aggregate.Count| |agg_funcs|covar_pop|org.apache.spark.sql.catalyst.expressions.aggregate.CovPopulation| |agg_funcs|covar_samp|org.apache.spark.sql.catalyst.expressions.aggregate.CovSample| |agg_funcs|cube|org.apache.spark.sql.catalyst.expressions.Cube| |agg_funcs|every|org.apache.spark.sql.catalyst.expressions.aggregate.BoolAnd| |agg_funcs|first_value|org.apache.spark.sql.catalyst.expressions.aggregate.First| |agg_funcs|first|org.apache.spark.sql.catalyst.expressions.aggregate.First| |agg_funcs|grouping_id|org.apache.spark.sql.catalyst.expressions.GroupingID| |agg_funcs|grouping|org.apache.spark.sql.catalyst.expressions.Grouping| |agg_funcs|kurtosis|org.apache.spark.sql.catalyst.expressions.aggregate.Kurtosis| |agg_funcs|last_value|org.apache.spark.sql.catalyst.expressions.aggregate.Last| |agg_funcs|last|org.apache.spark.sql.catalyst.expressions.aggregate.Last| |agg_funcs|max_by|org.apache.spark.sql.catalyst.expressions.aggregate.MaxBy| |agg_funcs|max|org.apache.spark.sql.catalyst.expressions.aggregate.Max| |agg_funcs|mean|org.apache.spark.sql.catalyst.expressions.aggregate.Average| |agg_funcs|min_by|org.apache.spark.sql.catalyst.expressions.aggregate.MinBy| |agg_funcs|min|org.apache.spark.sql.catalyst.expressions.aggregate.Min| |agg_funcs|percentile_approx|org.apache.spark.sql.catalyst.expressions.aggregate.ApproximatePercentile| |agg_funcs|percentile|org.apache.spark.sql.catalyst.expressions.aggregate.Percentile| |agg_funcs|rollup|org.apache.spark.sql.catalyst.expressions.Rollup| |agg_funcs|skewness|org.apache.spark.sql.catalyst.expressions.aggregate.Skewness| |agg_funcs|some|org.apache.spark.sql.catalyst.expressions.aggregate.BoolOr| |agg_funcs|stddev_pop|org.apache.spark.sql.catalyst.expressions.aggregate.StddevPop| |agg_funcs|stddev_samp|org.apache.spark.sql.catalyst.expressions.aggregate.StddevSamp| |agg_funcs|stddev|org.apache.spark.sql.catalyst.expressions.aggregate.StddevSamp| |agg_funcs|std|org.apache.spark.sql.catalyst.expressions.aggregate.StddevSamp| |agg_funcs|sum|org.apache.spark.sql.catalyst.expressions.aggregate.Sum| |agg_funcs|var_pop|org.apache.spark.sql.catalyst.expressions.aggregate.VariancePop| |agg_funcs|var_samp|org.apache.spark.sql.catalyst.expressions.aggregate.VarianceSamp| |agg_funcs|variance|org.apache.spark.sql.catalyst.expressions.aggregate.VarianceSamp| |array_funcs|array_contains|org.apache.spark.sql.catalyst.expressions.ArrayContains| |array_funcs|array_distinct|org.apache.spark.sql.catalyst.expressions.ArrayDistinct| |array_funcs|array_except|org.apache.spark.sql.catalyst.expressions.ArrayExcept| |array_funcs|array_intersect|org.apache.spark.sql.catalyst.expressions.ArrayIntersect| |array_funcs|array_join|org.apache.spark.sql.catalyst.expressions.ArrayJoin| |array_funcs|array_max|org.apache.spark.sql.catalyst.expressions.ArrayMax| |array_funcs|array_min|org.apache.spark.sql.catalyst.expressions.ArrayMin| |array_funcs|array_position|org.apache.spark.sql.catalyst.expressions.ArrayPosition| |array_funcs|array_remove|org.apache.spark.sql.catalyst.expressions.ArrayRemove| |array_funcs|array_repeat|org.apache.spark.sql.catalyst.expressions.ArrayRepeat| |array_funcs|array_union|org.apache.spark.sql.catalyst.expressions.ArrayUnion| |array_funcs|arrays_overlap|org.apache.spark.sql.catalyst.expressions.ArraysOverlap| |array_funcs|arrays_zip|org.apache.spark.sql.catalyst.expressions.ArraysZip| |array_funcs|array|org.apache.spark.sql.catalyst.expressions.CreateArray| |array_funcs|flatten|org.apache.spark.sql.catalyst.expressions.Flatten| |array_funcs|sequence|org.apache.spark.sql.catalyst.expressions.Sequence| |array_funcs|shuffle|org.apache.spark.sql.catalyst.expressions.Shuffle| |array_funcs|slice|org.apache.spark.sql.catalyst.expressions.Slice| |array_funcs|sort_array|org.apache.spark.sql.catalyst.expressions.SortArray| |bitwise_funcs|&|org.apache.spark.sql.catalyst.expressions.BitwiseAnd| |bitwise_funcs|^|org.apache.spark.sql.catalyst.expressions.BitwiseXor| |bitwise_funcs|bit_count|org.apache.spark.sql.catalyst.expressions.BitwiseCount| |bitwise_funcs|shiftrightunsigned|org.apache.spark.sql.catalyst.expressions.ShiftRightUnsigned| |bitwise_funcs|shiftright|org.apache.spark.sql.catalyst.expressions.ShiftRight| |bitwise_funcs|~|org.apache.spark.sql.catalyst.expressions.BitwiseNot| |collection_funcs|cardinality|org.apache.spark.sql.catalyst.expressions.Size| |collection_funcs|concat|org.apache.spark.sql.catalyst.expressions.Concat| |collection_funcs|reverse|org.apache.spark.sql.catalyst.expressions.Reverse| |collection_funcs|size|org.apache.spark.sql.catalyst.expressions.Size| |conditional_funcs|coalesce|org.apache.spark.sql.catalyst.expressions.Coalesce| |conditional_funcs|ifnull|org.apache.spark.sql.catalyst.expressions.IfNull| |conditional_funcs|if|org.apache.spark.sql.catalyst.expressions.If| |conditional_funcs|nanvl|org.apache.spark.sql.catalyst.expressions.NaNvl| |conditional_funcs|nullif|org.apache.spark.sql.catalyst.expressions.NullIf| |conditional_funcs|nvl2|org.apache.spark.sql.catalyst.expressions.Nvl2| |conditional_funcs|nvl|org.apache.spark.sql.catalyst.expressions.Nvl| |conditional_funcs|when|org.apache.spark.sql.catalyst.expressions.CaseWhen| |conversion_funcs|bigint|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|binary|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|boolean|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|cast|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|date|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|decimal|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|double|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|float|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|int|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|smallint|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|string|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|timestamp|org.apache.spark.sql.catalyst.expressions.Cast| |conversion_funcs|tinyint|org.apache.spark.sql.catalyst.expressions.Cast| |csv_funcs|from_csv|org.apache.spark.sql.catalyst.expressions.CsvToStructs| |csv_funcs|schema_of_csv|org.apache.spark.sql.catalyst.expressions.SchemaOfCsv| |csv_funcs|to_csv|org.apache.spark.sql.catalyst.expressions.StructsToCsv| |datetime_funcs|add_months|org.apache.spark.sql.catalyst.expressions.AddMonths| |datetime_funcs|current_date|org.apache.spark.sql.catalyst.expressions.CurrentDate| |datetime_funcs|current_timestamp|org.apache.spark.sql.catalyst.expressions.CurrentTimestamp| |datetime_funcs|current_timezone|org.apache.spark.sql.catalyst.expressions.CurrentTimeZone| |datetime_funcs|date_add|org.apache.spark.sql.catalyst.expressions.DateAdd| |datetime_funcs|date_format|org.apache.spark.sql.catalyst.expressions.DateFormatClass| |datetime_funcs|date_from_unix_date|org.apache.spark.sql.catalyst.expressions.DateFromUnixDate| |datetime_funcs|date_part|org.apache.spark.sql.catalyst.expressions.DatePart| |datetime_funcs|date_sub|org.apache.spark.sql.catalyst.expressions.DateSub| |datetime_funcs|date_trunc|org.apache.spark.sql.catalyst.expressions.TruncTimestamp| |datetime_funcs|datediff|org.apache.spark.sql.catalyst.expressions.DateDiff| |datetime_funcs|dayofmonth|org.apache.spark.sql.catalyst.expressions.DayOfMonth| |datetime_funcs|dayofweek|org.apache.spark.sql.catalyst.expressions.DayOfWeek| |datetime_funcs|dayofyear|org.apache.spark.sql.catalyst.expressions.DayOfYear| |datetime_funcs|day|org.apache.spark.sql.catalyst.expressions.DayOfMonth| |datetime_funcs|extract|org.apache.spark.sql.catalyst.expressions.Extract| |datetime_funcs|from_unixtime|org.apache.spark.sql.catalyst.expressions.FromUnixTime| |datetime_funcs|from_utc_timestamp|org.apache.spark.sql.catalyst.expressions.FromUTCTimestamp| |datetime_funcs|hour|org.apache.spark.sql.catalyst.expressions.Hour| |datetime_funcs|last_day|org.apache.spark.sql.catalyst.expressions.LastDay| |datetime_funcs|make_date|org.apache.spark.sql.catalyst.expressions.MakeDate| |datetime_funcs|make_interval|org.apache.spark.sql.catalyst.expressions.MakeInterval| |datetime_funcs|make_timestamp|org.apache.spark.sql.catalyst.expressions.MakeTimestamp| |datetime_funcs|minute|org.apache.spark.sql.catalyst.expressions.Minute| |datetime_funcs|months_between|org.apache.spark.sql.catalyst.expressions.MonthsBetween| |datetime_funcs|month|org.apache.spark.sql.catalyst.expressions.Month| |datetime_funcs|next_day|org.apache.spark.sql.catalyst.expressions.NextDay| |datetime_funcs|now|org.apache.spark.sql.catalyst.expressions.Now| |datetime_funcs|quarter|org.apache.spark.sql.catalyst.expressions.Quarter| |datetime_funcs|second|org.apache.spark.sql.catalyst.expressions.Second| |datetime_funcs|timestamp_micros|org.apache.spark.sql.catalyst.expressions.MicrosToTimestamp| |datetime_funcs|timestamp_millis|org.apache.spark.sql.catalyst.expressions.MillisToTimestamp| |datetime_funcs|timestamp_seconds|org.apache.spark.sql.catalyst.expressions.SecondsToTimestamp| |datetime_funcs|to_date|org.apache.spark.sql.catalyst.expressions.ParseToDate| |datetime_funcs|to_timestamp|org.apache.spark.sql.catalyst.expressions.ParseToTimestamp| |datetime_funcs|to_unix_timestamp|org.apache.spark.sql.catalyst.expressions.ToUnixTimestamp| |datetime_funcs|to_utc_timestamp|org.apache.spark.sql.catalyst.expressions.ToUTCTimestamp| |datetime_funcs|trunc|org.apache.spark.sql.catalyst.expressions.TruncDate| |datetime_funcs|unix_date|org.apache.spark.sql.catalyst.expressions.UnixDate| |datetime_funcs|unix_micros|org.apache.spark.sql.catalyst.expressions.UnixMicros| |datetime_funcs|unix_millis|org.apache.spark.sql.catalyst.expressions.UnixMillis| |datetime_funcs|unix_seconds|org.apache.spark.sql.catalyst.expressions.UnixSeconds| |datetime_funcs|unix_timestamp|org.apache.spark.sql.catalyst.expressions.UnixTimestamp| |datetime_funcs|weekday|org.apache.spark.sql.catalyst.expressions.WeekDay| |datetime_funcs|weekofyear|org.apache.spark.sql.catalyst.expressions.WeekOfYear| |datetime_funcs|year|org.apache.spark.sql.catalyst.expressions.Year| |generator_funcs|explode_outer|org.apache.spark.sql.catalyst.expressions.Explode| |generator_funcs|explode|org.apache.spark.sql.catalyst.expressions.Explode| |generator_funcs|inline_outer|org.apache.spark.sql.catalyst.expressions.Inline| |generator_funcs|inline|org.apache.spark.sql.catalyst.expressions.Inline| |generator_funcs|posexplode_outer|org.apache.spark.sql.catalyst.expressions.PosExplode| |generator_funcs|posexplode|org.apache.spark.sql.catalyst.expressions.PosExplode| |generator_funcs|stack|org.apache.spark.sql.catalyst.expressions.Stack| |hash_funcs|crc32|org.apache.spark.sql.catalyst.expressions.Crc32| |hash_funcs|hash|org.apache.spark.sql.catalyst.expressions.Murmur3Hash| |hash_funcs|md5|org.apache.spark.sql.catalyst.expressions.Md5| |hash_funcs|sha1|org.apache.spark.sql.catalyst.expressions.Sha1| |hash_funcs|sha2|org.apache.spark.sql.catalyst.expressions.Sha2| |hash_funcs|sha|org.apache.spark.sql.catalyst.expressions.Sha1| |hash_funcs|xxhash64|org.apache.spark.sql.catalyst.expressions.XxHash64| |json_funcs|from_json|org.apache.spark.sql.catalyst.expressions.JsonToStructs| |json_funcs|get_json_object|org.apache.spark.sql.catalyst.expressions.GetJsonObject| |json_funcs|json_array_length|org.apache.spark.sql.catalyst.expressions.LengthOfJsonArray| |json_funcs|json_object_keys|org.apache.spark.sql.catalyst.expressions.JsonObjectKeys| |json_funcs|json_tuple|org.apache.spark.sql.catalyst.expressions.JsonTuple| |json_funcs|schema_of_json|org.apache.spark.sql.catalyst.expressions.SchemaOfJson| |json_funcs|to_json|org.apache.spark.sql.catalyst.expressions.StructsToJson| |lambda_funcs|aggregate|org.apache.spark.sql.catalyst.expressions.ArrayAggregate| |lambda_funcs|array_sort|org.apache.spark.sql.catalyst.expressions.ArraySort| |lambda_funcs|exists|org.apache.spark.sql.catalyst.expressions.ArrayExists| |lambda_funcs|filter|org.apache.spark.sql.catalyst.expressions.ArrayFilter| |lambda_funcs|forall|org.apache.spark.sql.catalyst.expressions.ArrayForAll| |lambda_funcs|map_filter|org.apache.spark.sql.catalyst.expressions.MapFilter| |lambda_funcs|map_zip_with|org.apache.spark.sql.catalyst.expressions.MapZipWith| |lambda_funcs|transform_keys|org.apache.spark.sql.catalyst.expressions.TransformKeys| |lambda_funcs|transform_values|org.apache.spark.sql.catalyst.expressions.TransformValues| |lambda_funcs|transform|org.apache.spark.sql.catalyst.expressions.ArrayTransform| |lambda_funcs|zip_with|org.apache.spark.sql.catalyst.expressions.ZipWith| |map_funcs|element_at|org.apache.spark.sql.catalyst.expressions.ElementAt| |map_funcs|map_concat|org.apache.spark.sql.catalyst.expressions.MapConcat| |map_funcs|map_entries|org.apache.spark.sql.catalyst.expressions.MapEntries| |map_funcs|map_from_arrays|org.apache.spark.sql.catalyst.expressions.MapFromArrays| |map_funcs|map_from_entries|org.apache.spark.sql.catalyst.expressions.MapFromEntries| |map_funcs|map_keys|org.apache.spark.sql.catalyst.expressions.MapKeys| |map_funcs|map_values|org.apache.spark.sql.catalyst.expressions.MapValues| |map_funcs|map|org.apache.spark.sql.catalyst.expressions.CreateMap| |map_funcs|str_to_map|org.apache.spark.sql.catalyst.expressions.StringToMap| |math_funcs|%|org.apache.spark.sql.catalyst.expressions.Remainder| |math_funcs|*|org.apache.spark.sql.catalyst.expressions.Multiply| |math_funcs|+|org.apache.spark.sql.catalyst.expressions.Add| |math_funcs|-|org.apache.spark.sql.catalyst.expressions.Subtract| |math_funcs|/|org.apache.spark.sql.catalyst.expressions.Divide| |math_funcs|abs|org.apache.spark.sql.catalyst.expressions.Abs| |math_funcs|acosh|org.apache.spark.sql.catalyst.expressions.Acosh| |math_funcs|acos|org.apache.spark.sql.catalyst.expressions.Acos| |math_funcs|asinh|org.apache.spark.sql.catalyst.expressions.Asinh| |math_funcs|asin|org.apache.spark.sql.catalyst.expressions.Asin| |math_funcs|atan2|org.apache.spark.sql.catalyst.expressions.Atan2| |math_funcs|atanh|org.apache.spark.sql.catalyst.expressions.Atanh| |math_funcs|atan|org.apache.spark.sql.catalyst.expressions.Atan| |math_funcs|bin|org.apache.spark.sql.catalyst.expressions.Bin| |math_funcs|bround|org.apache.spark.sql.catalyst.expressions.BRound| |math_funcs|cbrt|org.apache.spark.sql.catalyst.expressions.Cbrt| |math_funcs|ceiling|org.apache.spark.sql.catalyst.expressions.Ceil| |math_funcs|ceil|org.apache.spark.sql.catalyst.expressions.Ceil| |math_funcs|conv|org.apache.spark.sql.catalyst.expressions.Conv| |math_funcs|cosh|org.apache.spark.sql.catalyst.expressions.Cosh| |math_funcs|cos|org.apache.spark.sql.catalyst.expressions.Cos| |math_funcs|cot|org.apache.spark.sql.catalyst.expressions.Cot| |math_funcs|degrees|org.apache.spark.sql.catalyst.expressions.ToDegrees| |math_funcs|div|org.apache.spark.sql.catalyst.expressions.IntegralDivide| |math_funcs|expm1|org.apache.spark.sql.catalyst.expressions.Expm1| |math_funcs|exp|org.apache.spark.sql.catalyst.expressions.Exp| |math_funcs|e|org.apache.spark.sql.catalyst.expressions.EulerNumber| |math_funcs|factorial|org.apache.spark.sql.catalyst.expressions.Factorial| |math_funcs|floor|org.apache.spark.sql.catalyst.expressions.Floor| |math_funcs|greatest|org.apache.spark.sql.catalyst.expressions.Greatest| |math_funcs|hex|org.apache.spark.sql.catalyst.expressions.Hex| |math_funcs|hypot|org.apache.spark.sql.catalyst.expressions.Hypot| |math_funcs|least|org.apache.spark.sql.catalyst.expressions.Least| |math_funcs|ln|org.apache.spark.sql.catalyst.expressions.Log| |math_funcs|log10|org.apache.spark.sql.catalyst.expressions.Log10| |math_funcs|log1p|org.apache.spark.sql.catalyst.expressions.Log1p| |math_funcs|log2|org.apache.spark.sql.catalyst.expressions.Log2| |math_funcs|log|org.apache.spark.sql.catalyst.expressions.Logarithm| |math_funcs|mod|org.apache.spark.sql.catalyst.expressions.Remainder| |math_funcs|negative|org.apache.spark.sql.catalyst.expressions.UnaryMinus| |math_funcs|pi|org.apache.spark.sql.catalyst.expressions.Pi| |math_funcs|pmod|org.apache.spark.sql.catalyst.expressions.Pmod| |math_funcs|positive|org.apache.spark.sql.catalyst.expressions.UnaryPositive| |math_funcs|power|org.apache.spark.sql.catalyst.expressions.Pow| |math_funcs|pow|org.apache.spark.sql.catalyst.expressions.Pow| |math_funcs|radians|org.apache.spark.sql.catalyst.expressions.ToRadians| |math_funcs|randn|org.apache.spark.sql.catalyst.expressions.Randn| |math_funcs|random|org.apache.spark.sql.catalyst.expressions.Rand| |math_funcs|rand|org.apache.spark.sql.catalyst.expressions.Rand| |math_funcs|rint|org.apache.spark.sql.catalyst.expressions.Rint| |math_funcs|round|org.apache.spark.sql.catalyst.expressions.Round| |math_funcs|shiftleft|org.apache.spark.sql.catalyst.expressions.ShiftLeft| |math_funcs|signum|org.apache.spark.sql.catalyst.expressions.Signum| |math_funcs|sign|org.apache.spark.sql.catalyst.expressions.Signum| |math_funcs|sinh|org.apache.spark.sql.catalyst.expressions.Sinh| |math_funcs|sin|org.apache.spark.sql.catalyst.expressions.Sin| |math_funcs|sqrt|org.apache.spark.sql.catalyst.expressions.Sqrt| |math_funcs|tanh|org.apache.spark.sql.catalyst.expressions.Tanh| |math_funcs|tan|org.apache.spark.sql.catalyst.expressions.Tan| |math_funcs|unhex|org.apache.spark.sql.catalyst.expressions.Unhex| |math_funcs|width_bucket|org.apache.spark.sql.catalyst.expressions.WidthBucket| |misc_funcs|assert_true|org.apache.spark.sql.catalyst.expressions.AssertTrue| |misc_funcs|current_catalog|org.apache.spark.sql.catalyst.expressions.CurrentCatalog| |misc_funcs|current_database|org.apache.spark.sql.catalyst.expressions.CurrentDatabase| |misc_funcs|input_file_block_length|org.apache.spark.sql.catalyst.expressions.InputFileBlockLength| |misc_funcs|input_file_block_start|org.apache.spark.sql.catalyst.expressions.InputFileBlockStart| |misc_funcs|input_file_name|org.apache.spark.sql.catalyst.expressions.InputFileName| |misc_funcs|java_method|org.apache.spark.sql.catalyst.expressions.CallMethodViaReflection| |misc_funcs|monotonically_increasing_id|org.apache.spark.sql.catalyst.expressions.MonotonicallyIncreasingID| |misc_funcs|raise_error|org.apache.spark.sql.catalyst.expressions.RaiseError| |misc_funcs|reflect|org.apache.spark.sql.catalyst.expressions.CallMethodViaReflection| |misc_funcs|spark_partition_id|org.apache.spark.sql.catalyst.expressions.SparkPartitionID| |misc_funcs|typeof|org.apache.spark.sql.catalyst.expressions.TypeOf| |misc_funcs|uuid|org.apache.spark.sql.catalyst.expressions.Uuid| |misc_funcs|version|org.apache.spark.sql.catalyst.expressions.SparkVersion| |predicate_funcs|!|org.apache.spark.sql.catalyst.expressions.Not| |predicate_funcs|<=>|org.apache.spark.sql.catalyst.expressions.EqualNullSafe| |predicate_funcs|<=|org.apache.spark.sql.catalyst.expressions.LessThanOrEqual| |predicate_funcs|<|org.apache.spark.sql.catalyst.expressions.LessThan| |predicate_funcs|==|org.apache.spark.sql.catalyst.expressions.EqualTo| |predicate_funcs|=|org.apache.spark.sql.catalyst.expressions.EqualTo| |predicate_funcs|>=|org.apache.spark.sql.catalyst.expressions.GreaterThanOrEqual| |predicate_funcs|>|org.apache.spark.sql.catalyst.expressions.GreaterThan| |predicate_funcs|and|org.apache.spark.sql.catalyst.expressions.And| |predicate_funcs|in|org.apache.spark.sql.catalyst.expressions.In| |predicate_funcs|isnan|org.apache.spark.sql.catalyst.expressions.IsNaN| |predicate_funcs|isnotnull|org.apache.spark.sql.catalyst.expressions.IsNotNull| |predicate_funcs|isnull|org.apache.spark.sql.catalyst.expressions.IsNull| |predicate_funcs|like|org.apache.spark.sql.catalyst.expressions.Like| |predicate_funcs|not|org.apache.spark.sql.catalyst.expressions.Not| |predicate_funcs|or|org.apache.spark.sql.catalyst.expressions.Or| |predicate_funcs|regexp_like|org.apache.spark.sql.catalyst.expressions.RLike| |predicate_funcs|rlike|org.apache.spark.sql.catalyst.expressions.RLike| |string_funcs|ascii|org.apache.spark.sql.catalyst.expressions.Ascii| |string_funcs|base64|org.apache.spark.sql.catalyst.expressions.Base64| |string_funcs|bit_length|org.apache.spark.sql.catalyst.expressions.BitLength| |string_funcs|char_length|org.apache.spark.sql.catalyst.expressions.Length| |string_funcs|character_length|org.apache.spark.sql.catalyst.expressions.Length| |string_funcs|char|org.apache.spark.sql.catalyst.expressions.Chr| |string_funcs|chr|org.apache.spark.sql.catalyst.expressions.Chr| |string_funcs|concat_ws|org.apache.spark.sql.catalyst.expressions.ConcatWs| |string_funcs|decode|org.apache.spark.sql.catalyst.expressions.Decode| |string_funcs|elt|org.apache.spark.sql.catalyst.expressions.Elt| |string_funcs|encode|org.apache.spark.sql.catalyst.expressions.Encode| |string_funcs|find_in_set|org.apache.spark.sql.catalyst.expressions.FindInSet| |string_funcs|format_number|org.apache.spark.sql.catalyst.expressions.FormatNumber| |string_funcs|format_string|org.apache.spark.sql.catalyst.expressions.FormatString| |string_funcs|initcap|org.apache.spark.sql.catalyst.expressions.InitCap| |string_funcs|instr|org.apache.spark.sql.catalyst.expressions.StringInstr| |string_funcs|lcase|org.apache.spark.sql.catalyst.expressions.Lower| |string_funcs|left|org.apache.spark.sql.catalyst.expressions.Left| |string_funcs|length|org.apache.spark.sql.catalyst.expressions.Length| |string_funcs|levenshtein|org.apache.spark.sql.catalyst.expressions.Levenshtein| |string_funcs|locate|org.apache.spark.sql.catalyst.expressions.StringLocate| |string_funcs|lower|org.apache.spark.sql.catalyst.expressions.Lower| |string_funcs|lpad|org.apache.spark.sql.catalyst.expressions.StringLPad| |string_funcs|ltrim|org.apache.spark.sql.catalyst.expressions.StringTrimLeft| |string_funcs|octet_length|org.apache.spark.sql.catalyst.expressions.OctetLength| |string_funcs|overlay|org.apache.spark.sql.catalyst.expressions.Overlay| |string_funcs|parse_url|org.apache.spark.sql.catalyst.expressions.ParseUrl| |string_funcs|position|org.apache.spark.sql.catalyst.expressions.StringLocate| |string_funcs|printf|org.apache.spark.sql.catalyst.expressions.FormatString| |string_funcs|regexp_extract_all|org.apache.spark.sql.catalyst.expressions.RegExpExtractAll| |string_funcs|regexp_extract|org.apache.spark.sql.catalyst.expressions.RegExpExtract| |string_funcs|regexp_replace|org.apache.spark.sql.catalyst.expressions.RegExpReplace| |string_funcs|repeat|org.apache.spark.sql.catalyst.expressions.StringRepeat| |string_funcs|replace|org.apache.spark.sql.catalyst.expressions.StringReplace| |string_funcs|right|org.apache.spark.sql.catalyst.expressions.Right| |string_funcs|rpad|org.apache.spark.sql.catalyst.expressions.StringRPad| |string_funcs|rtrim|org.apache.spark.sql.catalyst.expressions.StringTrimRight| |string_funcs|sentences|org.apache.spark.sql.catalyst.expressions.Sentences| |string_funcs|soundex|org.apache.spark.sql.catalyst.expressions.SoundEx| |string_funcs|space|org.apache.spark.sql.catalyst.expressions.StringSpace| |string_funcs|split|org.apache.spark.sql.catalyst.expressions.StringSplit| |string_funcs|substring_index|org.apache.spark.sql.catalyst.expressions.SubstringIndex| |string_funcs|substring|org.apache.spark.sql.catalyst.expressions.Substring| |string_funcs|substr|org.apache.spark.sql.catalyst.expressions.Substring| |string_funcs|translate|org.apache.spark.sql.catalyst.expressions.StringTranslate| |string_funcs|trim|org.apache.spark.sql.catalyst.expressions.StringTrim| |string_funcs|ucase|org.apache.spark.sql.catalyst.expressions.Upper| |string_funcs|unbase64|org.apache.spark.sql.catalyst.expressions.UnBase64| |string_funcs|upper|org.apache.spark.sql.catalyst.expressions.Upper| |struct_funcs|named_struct|org.apache.spark.sql.catalyst.expressions.CreateNamedStruct| |struct_funcs|struct|org.apache.spark.sql.catalyst.expressions.CreateNamedStruct| |window_funcs|cume_dist|org.apache.spark.sql.catalyst.expressions.CumeDist| |window_funcs|dense_rank|org.apache.spark.sql.catalyst.expressions.DenseRank| |window_funcs|lag|org.apache.spark.sql.catalyst.expressions.Lag| |window_funcs|lead|org.apache.spark.sql.catalyst.expressions.Lead| |window_funcs|nth_value|org.apache.spark.sql.catalyst.expressions.NthValue| |window_funcs|ntile|org.apache.spark.sql.catalyst.expressions.NTile| |window_funcs|percent_rank|org.apache.spark.sql.catalyst.expressions.PercentRank| |window_funcs|rank|org.apache.spark.sql.catalyst.expressions.Rank| |window_funcs|row_number|org.apache.spark.sql.catalyst.expressions.RowNumber| |xml_funcs|xpath_boolean|org.apache.spark.sql.catalyst.expressions.xml.XPathBoolean| |xml_funcs|xpath_double|org.apache.spark.sql.catalyst.expressions.xml.XPathDouble| |xml_funcs|xpath_float|org.apache.spark.sql.catalyst.expressions.xml.XPathFloat| |xml_funcs|xpath_int|org.apache.spark.sql.catalyst.expressions.xml.XPathInt| |xml_funcs|xpath_long|org.apache.spark.sql.catalyst.expressions.xml.XPathLong| |xml_funcs|xpath_number|org.apache.spark.sql.catalyst.expressions.xml.XPathDouble| |xml_funcs|xpath_short|org.apache.spark.sql.catalyst.expressions.xml.XPathShort| |xml_funcs|xpath_string|org.apache.spark.sql.catalyst.expressions.xml.XPathString| |xml_funcs|xpath|org.apache.spark.sql.catalyst.expressions.xml.XPathList| Closes #30040 NOTE: An original author of this PR is tanelk, so the credit should be given to tanelk. ### Why are the changes needed? For better documents. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Add a test to check if exprs have a group tag in `ExpressionInfoSuite`. Closes #30867 from maropu/pr30040. Lead-authored-by: Takeshi Yamamuro <yamamuro@apache.org> Co-authored-by: tanel.kiis@gmail.com <tanel.kiis@gmail.com> Signed-off-by: Dongjoon Hyun <dhyun@apple.com>
What changes were proposed in this pull request?
Why are the changes needed?
Does this PR introduce any user-facing change?
How was this patch tested?