[SPARK-33609][ML] word2vec reduce broadcast size #30548
Conversation
| var i = 0 | ||
| while (i < numWords) { | ||
| val vec = wordVectors.slice(i * vectorSize, i * vectorSize + vectorSize) |
There was a problem hiding this comment.
avoid this slicing
| @@ -538,9 +538,13 @@ class Word2VecModel private[spark] ( | |||
| @Since("1.1.0") | |||
| def transform(word: String): Vector = { | |||
| wordIndex.get(word) match { | |||
| case Some(ind) => | |||
| val vec = wordVectors.slice(ind * vectorSize, ind * vectorSize + vectorSize) | |||
There was a problem hiding this comment.
avoid this slicing
|
Test build #131984 has finished for PR 30548 at commit
|
| @@ -278,34 +279,45 @@ class Word2VecModel private[ml] ( | |||
| @Since("1.4.0") | |||
| def setOutputCol(value: String): this.type = set(outputCol, value) | |||
|
|
|||
| private var bcModel: Broadcast[Word2VecModel] = _ | |||
There was a problem hiding this comment.
I don't suppose we have a way to clean this up after use - will just have to get GCed?
There was a problem hiding this comment.
yes. I followed the impl of CountVectorizer here.
Since other .ml impls do not use a mutable var for a broadcast variable like this, I will remove this var.
There was a problem hiding this comment.
As to CountVectorizer, should we also remove the var broadcastDict in it? It looks like that other mllib impls do not use mutable broadcasted variable like that.
| val offset = index * size | ||
| val array = Array.ofDim[Double](size) | ||
| var i = 0 | ||
| while (i < size) { array(i) = wordVectors(offset + i); i += 1 } |
There was a problem hiding this comment.
Is this actually more efficient than slice? Likewise above.
There was a problem hiding this comment.
I guess so, I will do a simple test.
| } | ||
|
|
||
| // wordVecNorms: Array of length numWords, each value being the Euclidean norm | ||
| // of the wordVector. | ||
| private val wordVecNorms: Array[Float] = { | ||
| val wordVecNorms = new Array[Float](numWords) | ||
| private lazy val wordVecNorms: Array[Float] = { |
There was a problem hiding this comment.
How much does this save, if it only happens once and has to happen to use the model?
There was a problem hiding this comment.
this var wordVecNorms is only used in method findSynonyms in the .mllib.w2v; however, this findSynonyms is never used in the .ml side. So I think we can make it lazy.
There was a problem hiding this comment.
OK fair enough. There are use cases here that would never need this calculated?
There was a problem hiding this comment.
however, this findSynonyms is never used in the .ml side. So I think we can make it lazy.
I am wrong. this var wordVecNorms is used in methods findSynonyms and findSynonymsArray in the .ml side. Since it is not used in transform, so we can still mark it lazy
| val word2Vec = udf { sentence: Seq[String] => | ||
|
|
||
| if (bcModel == null) { | ||
| bcModel = dataset.sparkSession.sparkContext.broadcast(this) |
There was a problem hiding this comment.
Looks like you only use this.wordVectors below? maybe just broadcast that
There was a problem hiding this comment.
both wordVectors and wordIndex are used.
There was a problem hiding this comment.
yes, there are two wordVectors...
There was a problem hiding this comment.
Oops, right, I think I meant to say that you only use those two. is there any savings from just broadcasting those rather than the whole model? if not that's fine.
|
test performance: result: @srowen it seems that directly adding float values is nearly 2x faster than using |

|
I buy that. If this is in response to the slice comment above, I am looking at a different part of the change where you unrolled the slice. Not a big deal but I guess I'd be surprised if it makes a difference, and if not, then slice is simpler. |
| val emptyVec = Vectors.sparse(d, Array.emptyIntArray, Array.emptyDoubleArray) | ||
| val word2Vec = udf { sentence: Seq[String] => | ||
|
|
||
| val bcModel = dataset.sparkSession.sparkContext.broadcast(this.wordVectors) |
There was a problem hiding this comment.
At first glance this makes more sense. But, we can't call bcModel.destroy() at the end here anyway. So we have this broadcast we can't explicitly close no matter what. And now I guess, this would re-broadcast every time? that could be bad. What do you think? I know this is not consistent in the code either way.
There was a problem hiding this comment.
And now I guess, this would re-broadcast every time? that could be bad. What do you think?
I agree. I perfer not using broadcasting in transform, but this may need more discussion. we can keep current behavior for now.
GBT models are also broadcasted in this way for performance since SPARK-7127.
There was a problem hiding this comment.
Looks good but i'd back out this part of the change
|
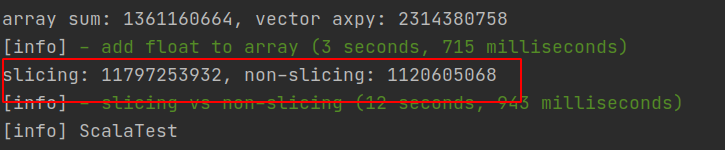
slicing:
@srowen slicing and then mapping to double, is about 10X slower than the new impl. It is somewhat surprising to me. |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #132082 has finished for PR 30548 at commit
|
|
Merged to master, thanks @srowen for reviewing! |
What changes were proposed in this pull request?
1, directly use float vectors instead of converting to double vectors, this is about 2x faster than using vec.axpy;
2, mark
wordListandwordVecNormslazy3, avoid slicing in computation of
wordVecNormsWhy are the changes needed?
halve broadcast size
Does this PR introduce any user-facing change?
No
How was this patch tested?
existing testsuites