[SPARK-33100][SQL][FOLLOWUP] Find correct bound of bracketed comment in spark-sql #31054
Conversation
|
After this PR, the log in sql/hive-thriftserver/target/unit-tests.log |
cce5932
to
b42d28f
Compare
|
ok to test |
|
also cc: @bogdanghit |
This causes the flakiness? Why can the test pass sometimes? |
|
Test build #133738 has finished for PR 31054 at commit
|
|
Kubernetes integration test starting |
|
according to the log you attached(https://github.com/apache/spark/pull/31045/checks?check_run_id=1652972350), Is it possible that, for the CliSuite, we launch a process for test and write all queries into the outputstream of this process, So one result loss and can not be matched, so the UT failed at last. Is it better to change it to? |
|
Kubernetes integration test status success |
|
Test build #133744 has finished for PR 31054 at commit
|
...e-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
Show resolved
Hide resolved
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/CliSuite.scala
Show resolved
Hide resolved
...e-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
Outdated
Show resolved
Hide resolved
...e-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
Show resolved
Hide resolved
...e-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
Outdated
Show resolved
Hide resolved
If we flushed it for each query, did we could notice this issue right away? If yes, I think it is worth doing so. The change could make the test running time of `CliSuite longer? Could you check it in a separate PR after this issue fixed? |
I think it would not cost much time, will try it later. |
|
Here is a test case(query contains '\n') which can not be covered by runCliWithin: log: It seems that it is not better to transfer multiple queries one time, but there is some UT like this: |
|
Test build #133766 has finished for PR 31054 at commit
|
|
Kubernetes integration test starting |
...e-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
Show resolved
Hide resolved
...e-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
Outdated
Show resolved
Hide resolved
Thanks for investigating it , @turboFei . Could you file another jira and make a PR for it? |
|
Kubernetes integration test status success |
Sure. |
|
Test build #133777 has finished for PR 31054 at commit
|
|
Kubernetes integration test starting |
@turboFei Could you do this? |
|
Kubernetes integration test status success |
ok, I will trigger GA test 3 times again. |
|
@turboFei You need to push two more empty commits for invoking GA tests concurrently. It seems that only one test job is running now. |
|
Thanks for it! Let's wait for the test results... |
|
Kubernetes integration test starting |
|
Test build #133783 has finished for PR 31054 at commit
|
|
Kubernetes integration test status failure |
|
For the first time GA test: |
Yea, that's the known issue. |
|
the second and third succeed. |
|
okay, thanks for the quick fix! I'll merge this to fix the flakiness. FYI: @HyukjinKwon @dongjoon-hyun If you have any further comments, feel free to leave comments here. |
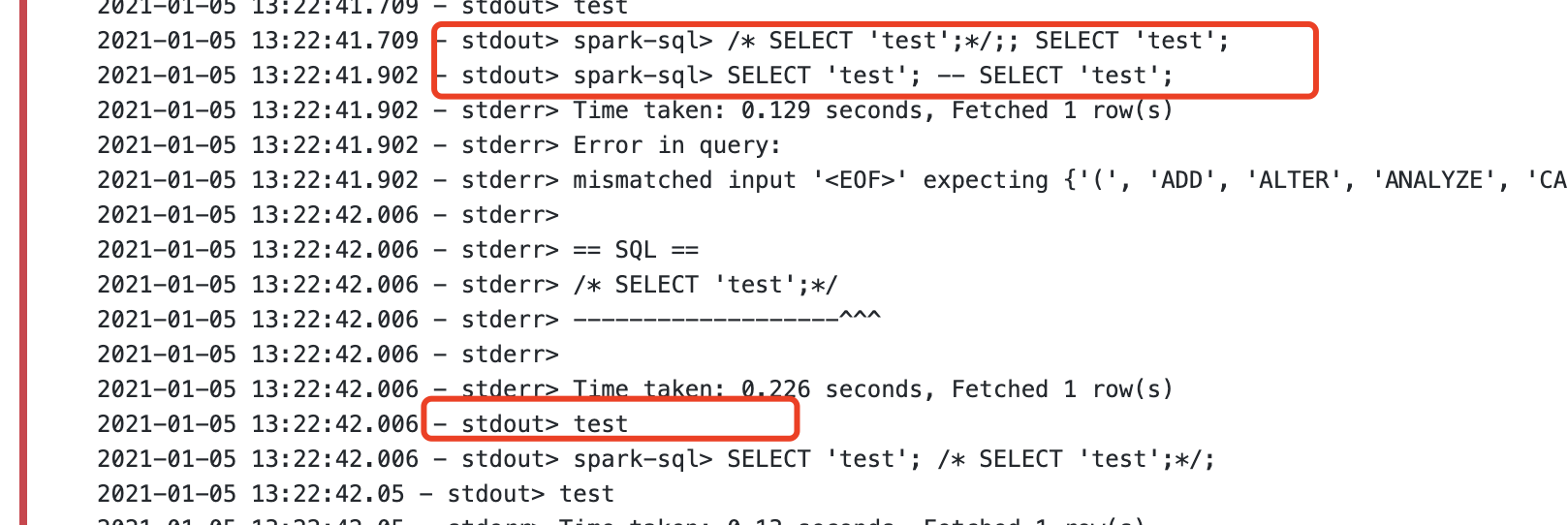
…in spark-sql ### What changes were proposed in this pull request? This PR help find correct bound of bracketed comment in spark-sql. Here is the log for UT of SPARK-33100 in CliSuite before: ``` 2021-01-05 13:22:34.768 - stdout> spark-sql> /* SELECT 'test';*/ SELECT 'test'; 2021-01-05 13:22:41.523 - stderr> Time taken: 6.716 seconds, Fetched 1 row(s) 2021-01-05 13:22:41.599 - stdout> test 2021-01-05 13:22:41.6 - stdout> spark-sql> ;;/* SELECT 'test';*/ SELECT 'test'; 2021-01-05 13:22:41.709 - stdout> test 2021-01-05 13:22:41.709 - stdout> spark-sql> /* SELECT 'test';*/;; SELECT 'test'; 2021-01-05 13:22:41.902 - stdout> spark-sql> SELECT 'test'; -- SELECT 'test'; 2021-01-05 13:22:41.902 - stderr> Time taken: 0.129 seconds, Fetched 1 row(s) 2021-01-05 13:22:41.902 - stderr> Error in query: 2021-01-05 13:22:41.902 - stderr> mismatched input '<EOF>' expecting {'(', 'ADD', 'ALTER', 'ANALYZE', 'CACHE', 'CLEAR', 'COMMENT', 'COMMIT', 'CREATE', 'DELETE', 'DESC', 'DESCRIBE', 'DFS', 'DROP', 'EXPLAIN', 'EXPORT', 'FROM', 'GRANT', 'IMPORT', 'INSERT', 'LIST', 'LOAD', 'LOCK', 'MAP', 'MERGE', 'MSCK', 'REDUCE', 'REFRESH', 'REPLACE', 'RESET', 'REVOKE', 'ROLLBACK', 'SELECT', 'SET', 'SHOW', 'START', 'TABLE', 'TRUNCATE', 'UNCACHE', 'UNLOCK', 'UPDATE', 'USE', 'VALUES', 'WITH'}(line 1, pos 19) 2021-01-05 13:22:42.006 - stderr> 2021-01-05 13:22:42.006 - stderr> == SQL == 2021-01-05 13:22:42.006 - stderr> /* SELECT 'test';*/ 2021-01-05 13:22:42.006 - stderr> -------------------^^^ 2021-01-05 13:22:42.006 - stderr> 2021-01-05 13:22:42.006 - stderr> Time taken: 0.226 seconds, Fetched 1 row(s) 2021-01-05 13:22:42.006 - stdout> test ``` The root cause is that the insideBracketedComment is not accurate. For `/* comment */`, the last character `/` is not insideBracketedComment and it would be treat as beginning of statements. In this PR, this issue is fixed. ### Why are the changes needed? To fix the issue described above. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing UT Closes #31054 from turboFei/SPARK-33100-followup. Authored-by: fwang12 <fwang12@ebay.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org> (cherry picked from commit 7b06acc) Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
|
Merged to master/branch-3.1. |
…in spark-sql
### What changes were proposed in this pull request?
This PR help find correct bound of bracketed comment in spark-sql.
Here is the log for UT of SPARK-33100 in CliSuite before:
```
2021-01-05 13:22:34.768 - stdout> spark-sql> /* SELECT 'test';*/ SELECT 'test';
2021-01-05 13:22:41.523 - stderr> Time taken: 6.716 seconds, Fetched 1 row(s)
2021-01-05 13:22:41.599 - stdout> test
2021-01-05 13:22:41.6 - stdout> spark-sql> ;;/* SELECT 'test';*/ SELECT 'test';
2021-01-05 13:22:41.709 - stdout> test
2021-01-05 13:22:41.709 - stdout> spark-sql> /* SELECT 'test';*/;; SELECT 'test';
2021-01-05 13:22:41.902 - stdout> spark-sql> SELECT 'test'; -- SELECT 'test';
2021-01-05 13:22:41.902 - stderr> Time taken: 0.129 seconds, Fetched 1 row(s)
2021-01-05 13:22:41.902 - stderr> Error in query:
2021-01-05 13:22:41.902 - stderr> mismatched input '<EOF>' expecting {'(', 'ADD', 'ALTER', 'ANALYZE', 'CACHE', 'CLEAR', 'COMMENT', 'COMMIT', 'CREATE', 'DELETE', 'DESC', 'DESCRIBE', 'DFS', 'DROP', 'EXPLAIN', 'EXPORT', 'FROM', 'GRANT', 'IMPORT', 'INSERT', 'LIST', 'LOAD', 'LOCK', 'MAP', 'MERGE', 'MSCK', 'REDUCE', 'REFRESH', 'REPLACE', 'RESET', 'REVOKE', 'ROLLBACK', 'SELECT', 'SET', 'SHOW', 'START', 'TABLE', 'TRUNCATE', 'UNCACHE', 'UNLOCK', 'UPDATE', 'USE', 'VALUES', 'WITH'}(line 1, pos 19)
2021-01-05 13:22:42.006 - stderr>
2021-01-05 13:22:42.006 - stderr> == SQL ==
2021-01-05 13:22:42.006 - stderr> /* SELECT 'test';*/
2021-01-05 13:22:42.006 - stderr> -------------------^^^
2021-01-05 13:22:42.006 - stderr>
2021-01-05 13:22:42.006 - stderr> Time taken: 0.226 seconds, Fetched 1 row(s)
2021-01-05 13:22:42.006 - stdout> test
```
The root cause is that the insideBracketedComment is not accurate.
For `/* comment */`, the last character `/` is not insideBracketedComment and it would be treat as beginning of statements.
In this PR, this issue is fixed.
### Why are the changes needed?
To fix the issue described above.
### Does this PR introduce _any_ user-facing change?
No
### How was this patch tested?
Existing UT
Closes apache#31054 from turboFei/SPARK-33100-followup.
Authored-by: fwang12 <fwang12@ebay.com>
Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
What changes were proposed in this pull request?
This PR help find correct bound of bracketed comment in spark-sql.
Here is the log for UT of SPARK-33100 in CliSuite before:
The root cause is that the insideBracketedComment is not accurate.
For
/* comment */, the last character/is not insideBracketedComment and it would be treat as beginning of statements.In this PR, this issue is fixed.
Why are the changes needed?
To fix the issue described above.
Does this PR introduce any user-facing change?
No
How was this patch tested?
Existing UT