[SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join #31470
Conversation
|
cc @cloud-fan |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #134867 has finished for PR 31470 at commit
|
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #134879 has finished for PR 31470 at commit
|
| @@ -728,8 +728,6 @@ class PlannerSuite extends SharedSparkSession with AdaptiveSparkPlanHelper { | |||
| case r: Range => r | |||
| } | |||
| assert(ranges.length == 2) | |||
| // Ensure the two Range instances are equal according to their equal method | |||
| assert(ranges.head == ranges.last) | |||
There was a problem hiding this comment.
This's no longer valid as DeduplicateRelations deduplicates them.
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DeduplicateRelations.scala
Show resolved
Hide resolved
|
@cloud-fan @maropu @viirya Could you take a look? Thanks! |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Test build #135022 has finished for PR 31470 at commit
|
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DeduplicateRelations.scala
Show resolved
Hide resolved
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/analysis/AnalysisTest.scala
Show resolved
Hide resolved
|
@Ngone51 This PR has the two parts below?
At least, we need to backport the former part into the previous branches, I think. |
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DeduplicateRelations.scala
Outdated
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DeduplicateRelations.scala
Outdated
Show resolved
Hide resolved
...st/src/test/scala/org/apache/spark/sql/catalyst/optimizer/joinReorder/JoinReorderSuite.scala
Outdated
Show resolved
Hide resolved
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DeduplicateRelations.scala
Show resolved
Hide resolved
But these two parts are actually made by a single rule - |
|
Kubernetes integration test starting |
|
Kubernetes integration test starting |
|
Kubernetes integration test status success |
|
Kubernetes integration test status failure |
|
Test build #135905 has finished for PR 31470 at commit
|
|
Test build #135906 has finished for PR 31470 at commit
|
|
Test build #135971 has finished for PR 31470 at commit
|
d212b95
to
ec525d8
Compare
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
Outdated
Show resolved
Hide resolved
|
Looks fine otherwise |
� Conflicts: � sql/core/src/test/resources/tpcds-plan-stability/approved-plans-v1_4/q32/explain.txt � sql/core/src/test/resources/tpcds-plan-stability/approved-plans-v1_4/q41.sf100/explain.txt � sql/core/src/test/resources/tpcds-plan-stability/approved-plans-v1_4/q41/explain.txt � sql/core/src/test/resources/tpcds-plan-stability/approved-plans-v1_4/q92/explain.txt
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #136557 has finished for PR 31470 at commit
|
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/DeduplicateRelations.scala
Outdated
Show resolved
Hide resolved
|
Test build #136652 has started for PR 31470 at commit |
|
retest this please |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #136741 has finished for PR 31470 at commit
|
|
thanks, merging to master! |
|
It seems it broke PySpark tests ... https://github.com/apache/spark/runs/2240195852 |
|
Is the failure from the latest run? I tested the same failed test locally yesterday and passed, and so I retriggered the GA. |
|
I think the last trigger didn't pass in this PR: |
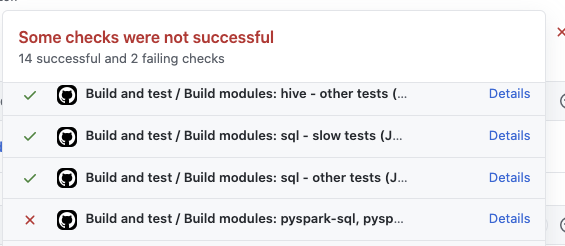
|
Just for a bit of more contexts, ever since Jenkins were upgraded, we didn't install pandas, etc so we don't run the pandas in Jenkins. The pandas related tests only run on GA for now. |
|
I think we should install pandas / pyarrow in jenkins machines: let me file a JIRA and assign to @shaneknapp |
|
Resubmitted #32027 |
What changes were proposed in this pull request?
This PR introduces a new analysis rule
DeduplicateRelations, which deduplicates any duplicate relations in a plan first and then deduplicates conflicting attributes(which resued thededupRightofResolveReferences).Why are the changes needed?
CostBasedJoinReordercould fail when applying on self-join, e.g.,Besides, with the new rule
DeduplicateRelations, we'd be able to enable some optimizations, e.g., LeftSemiAnti pushdown, redundant project removal, as reflects in updated unit tests.Does this PR introduce any user-facing change?
How was this patch tested?
Added and updated unit tests.