[SPARK-37490][SQL] Show extra hint if analyzer fails due to ANSI type coercion #34747
Conversation
| try { | ||
| checkAnalysis(nonAnsiPlan) | ||
| "\nTo fix the error, you might need to add explicit type casts.\n" + | ||
| "To bypass the error with lenient type coercion rules, " + |
There was a problem hiding this comment.
If necessary set spark.sql.ansi.enabled to false to bypass this error. to be consistent with other ansi related errors.
There was a problem hiding this comment.
I feel that we need to provide more context here. There are data type mismatch errors in non-Ansi mode as well.
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Test build #145728 has finished for PR 34747 at commit
|
| "" | ||
| } else { | ||
| val nonAnsiPlan = AnalysisContext.withDefaultTypeCoercionAnalysisContext { | ||
| executeSameContext(plan) |
There was a problem hiding this comment.
It might be expensive to run the analyzer again under ANSI mode just for the error message. Maybe we can just add this hint "To fix the error, you might need to add explicit type casts." to the existing error messages.
There was a problem hiding this comment.
It won't be a perf issue. When the code reaches here, the query already fails.
But from user experience, I am thinking about just adding To fix the error, you might need to add explicit type casts. and don't show the hint set spark.sql.ansi.enabled to false
There was a problem hiding this comment.
In some cases, people are not able to edit the query. I think turning off ansi mode is still a necessary workaround.
There was a problem hiding this comment.
@gengliangwang To fix the error, you might need to add explicit type casts. If necessary set spark.sql.ansi.enabled to false to bypass this error.
| } | ||
| try { | ||
| checkAnalysis(nonAnsiPlan) | ||
| "\nTo fix the error, you might need to add explicit type casts.\n" + |
There was a problem hiding this comment.
I'm a bit worried about the accuracy here. Re-running the entire analyzer includes more stuff, not just type coercion. Can we be more surgical and only rerun type coercion rules in CheckAnalysis when we hit input type mismatch error?
There was a problem hiding this comment.
Another point is, the analyzer has "side effects", as it may send RPC requests to the remote catalog. I think it's better to not run the entire analyzer again, even if the query fails.
There was a problem hiding this comment.
Can we be more surgical and only rerun type coercion rules in CheckAnalysis when we hit input type mismatch error?
We need to rerun some of the rules since they were skipped because the children weren't resolved.
If we have to do it, we should split the case match of checkAnalysis into two parts
There was a problem hiding this comment.
IIUC the analysis is bottom-up, and CheckAnalysis should find the bottom-most expression whose children are all resolved and input type mismatches?
There was a problem hiding this comment.
Take ResolveAliases as an example, the order of it is in front of Type Coercion rules, but it won't happen in the first run since the children is not resolved. After apply the Type Coercion rules, we still have to run the other rules again:
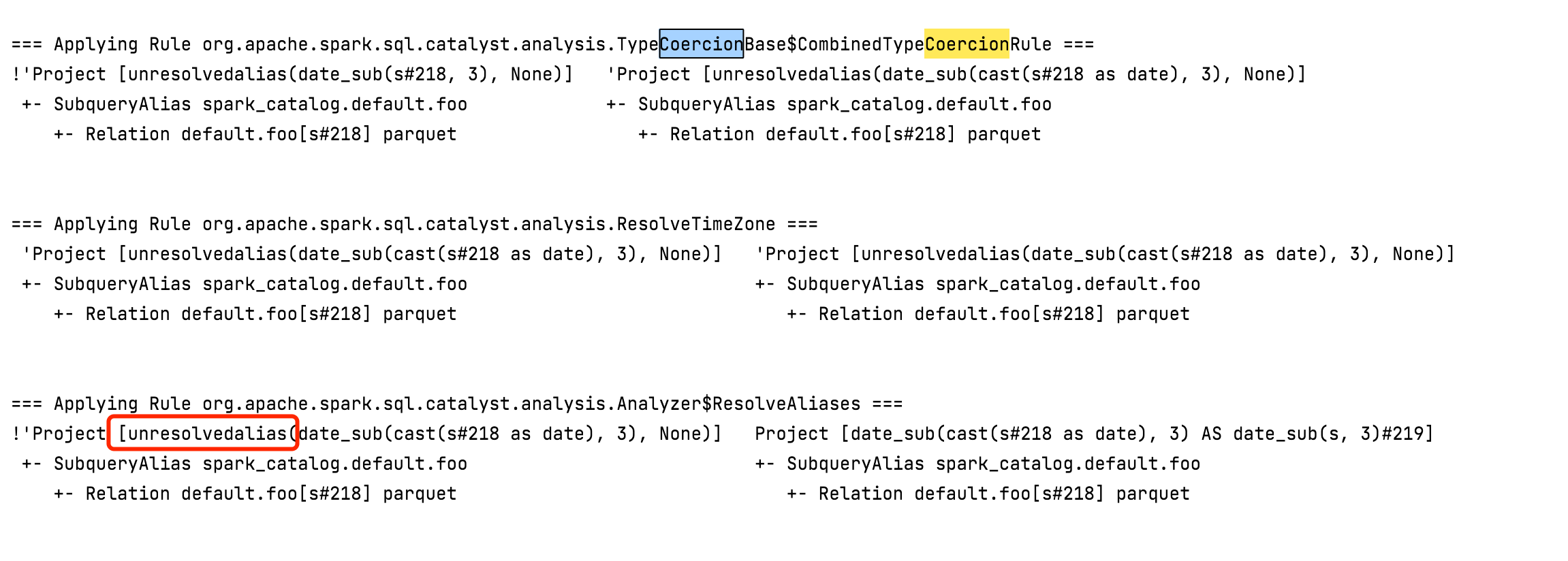
| // Check if the data types match. | ||
| dataTypes(child).zip(ref).zipWithIndex.foreach { case ((dt1, dt2), ci) => | ||
| // SPARK-18058: we shall not care about the nullability of columns | ||
| if (dataTypesAreCompatibleFn(dt1, dt2)) { | ||
| operator.setTagValue(DATA_TYPE_MISMATCH_ERROR, true) |
There was a problem hiding this comment.
do we need to set the tag here? it's always the root node and it's very easy to find it.
|
Kubernetes integration test starting |
|
Kubernetes integration test starting |
|
Kubernetes integration test status failure |
|
Kubernetes integration test status failure |
|
Test build #145763 has finished for PR 34747 at commit
|
|
Test build #145765 has finished for PR 34747 at commit
|
|
Merging to master |
…rrect name ### What changes were proposed in this pull request? #41850 uses `TYPE_CHECK_FAILURE_WITH_HINT`, it should be `DATATYPE_MISMATCH.TYPE_CHECK_FAILURE_WITH_HINT`. The first commit come from #34747. ### Why are the changes needed? Fix a bug. ### Does this PR introduce _any_ user-facing change? 'No'. ### How was this patch tested? N/A Closes #42084 from beliefer/SPARK-44292_followup. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…rrect name ### What changes were proposed in this pull request? #41850 uses `TYPE_CHECK_FAILURE_WITH_HINT`, it should be `DATATYPE_MISMATCH.TYPE_CHECK_FAILURE_WITH_HINT`. The first commit come from #34747. ### Why are the changes needed? Fix a bug. ### Does this PR introduce _any_ user-facing change? 'No'. ### How was this patch tested? N/A Closes #42084 from beliefer/SPARK-44292_followup. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> (cherry picked from commit 325888b) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…rrect name ### What changes were proposed in this pull request? apache#41850 uses `TYPE_CHECK_FAILURE_WITH_HINT`, it should be `DATATYPE_MISMATCH.TYPE_CHECK_FAILURE_WITH_HINT`. The first commit come from apache#34747. ### Why are the changes needed? Fix a bug. ### Does this PR introduce _any_ user-facing change? 'No'. ### How was this patch tested? N/A Closes apache#42084 from beliefer/SPARK-44292_followup. Authored-by: Jiaan Geng <beliefer@163.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
What changes were proposed in this pull request?
Show extra hint in the error message if analysis failed only with ANSI type coercion:
Why are the changes needed?
Improve error message
Does this PR introduce any user-facing change?
Yes, Spark will show extra hint if analyzer fails due to ANSI type coercion
How was this patch tested?
Unit tests