STORM-2406 [Storm SQL] Change underlying API to Streams API #2443
Conversation
|
While working with Streams API, I feel the needs for Source (typed Spout) and Sink (typed Sink Bolt) so have been thinking about interfaces/abstract classes, but due to ACK mechanism and various approaches of implementing external sink bolts, hiding concept of I have another wondering case to windowing with timestamp field: Streams API doesn't expose field name, but Streams API still receive field name for timestamp field. It may need to be addressed before STORM-2405 (support windowing aggregation in SQL). |
| .partitionPersist(consumer.getStateFactory(), new Fields(inputFields), consumer.getStateUpdater(), | ||
| new Fields(outputFields)) | ||
| .newValuesStream().name(stageName); | ||
| inputStream.mapToPair(new StreamInsertMapToPairFunction(primaryKeyIndex)).to(consumer); |
There was a problem hiding this comment.
To make logic simple, it assumes that all the tables have one PK (which it should be extended to support composed key), and provides PairStream(KeyedStream) to consumer bolt.
|
|
||
| Preconditions.checkArgument(isInsert(), "Only INSERT statement is supported."); | ||
|
|
||
| List<String> inputFields = this.input.getRowType().getFieldNames(); | ||
| List<String> outputFields = getRowType().getFieldNames(); | ||
| // Calcite ensures that the value is structurized to the table definition |
There was a problem hiding this comment.
To elaborate, if table BAR is defined as ID INTEGER PK, NAME VARCHAR, DEPTID INTEGER and query like INSERT INTO BAR SELECT NAME, ID FROM FOO is executed, Calcite makes the projection ($1 <- ID, $0 <- NAME, null) to the value before INSERT.
e9f7ff6
to
42b6a50
Compare
| @@ -66,10 +66,34 @@ | |||
| <artifactId>calcite-core</artifactId> | |||
| <version>${calcite.version}</version> | |||
| <exclusions> | |||
| <exclusion> | |||
There was a problem hiding this comment.
They're for supporting another parts of Calcite and unneeded dependencies for us. Some dependencies are something already we have, so also good to avoid the version conflict.
There was a problem hiding this comment.
Makes sense if we don't need them.
If you're trying to avoid version conflicts for transitive dependencies I think adding a <dependencyManagement> section to set the versions is better. It lets you set which version of the dependency you want, and then all transitive includes of that dependency will be the specified version. I think we do this with e.g. the Jackson dependencies in the Storm parent pom.
| public interface ParallelTable extends StormTable { | ||
|
|
||
| /** | ||
| * Returns parallelism hint of this table. Returns null if don't know. |
There was a problem hiding this comment.
nit: Returns null if not known.
| @@ -66,10 +66,34 @@ | |||
| <artifactId>calcite-core</artifactId> | |||
There was a problem hiding this comment.
You might want to reduce the allowed checkstyle errors in the poms if you reduced the violations.
There was a problem hiding this comment.
I'll see how the number is changed. It might be remain the same if I fixed checkstyle issue from A and violated from B.
Actually I'm focusing on planning and addressing window aggregation and join, so TBH I'd like to address the checkstyle issue later altogether.
There was a problem hiding this comment.
Sure. I didn't mean to say that you should do any extra work on checkstyle in this, just wanted to make sure reducing the counter wasn't being forgotten by accident.
There was a problem hiding this comment.
Good. Thanks for the reminder. :)
| @@ -117,9 +138,21 @@ public TableBuilderInfo parallelismHint(int parallelismHint) { | |||
| return this; | |||
| } | |||
|
|
|||
| // FIXME: we may want to separate Stream and Table, and let output table be Table instead of Stream | |||
There was a problem hiding this comment.
Can you put this in an issue instead? I think it will be forgotten if left as a TODO in the code.
There was a problem hiding this comment.
OK I'll file an issue and remove the comment.
There was a problem hiding this comment.
| return this; | ||
| } | ||
|
|
||
| private void interpretConstraint(ColumnConstraint constraint, int fieldIdx) { | ||
| if (constraint instanceof ColumnConstraint.PrimaryKey) { | ||
| ColumnConstraint.PrimaryKey pk = (ColumnConstraint.PrimaryKey) constraint; | ||
| Preconditions.checkState(primaryKey == -1, "There are more than one primary key in the table"); |
| ByteBuffer b = SERIALIZER.write(tuple.getValues(), null); | ||
| return b.equals(buf); | ||
| } | ||
| Assert.assertEquals(KafkaBolt.class, consumer.getClass()); |
There was a problem hiding this comment.
Same question as for the HDFS test
| String serField; | ||
| if (props.contains("ser.field")) { | ||
| serField = props.getProperty("ser.field"); | ||
| } else if (props.contains("trident.ser.field")) { |
There was a problem hiding this comment.
Nit: Are there constants somewhere that could be used instead of literals?
There was a problem hiding this comment.
I think I missed it. Nice finding. Will address. Btw it is specific to mongo config, so constants will be put in same class.
| import org.slf4j.LoggerFactory; | ||
|
|
||
| /** | ||
| * The Bolt implementation for Socket. The class is for test purpose and doesn't handle reconnection or so. |
There was a problem hiding this comment.
What is meant by "or so"?
Also if this class is only for tests, can it be moved to test scope? And if not, can it be moved into a package for test classes so it's clear that it's only for tests?
There was a problem hiding this comment.
I think removing "or so" is clearer. What I meant for test is not unit test, just for users to test query before attaching external source. Maybe we can just remove mentioning about test purpose and mention that it doesn't handle reconnection.
| import org.slf4j.Logger; | ||
| import org.slf4j.LoggerFactory; | ||
|
|
||
| /** | ||
| * Trident Spout for Socket data. Only available for Storm SQL, and only use for test purposes. | ||
| * Spout for Socket data. Only available for Storm SQL. This doesn't guarantee at-least-once. |
There was a problem hiding this comment.
Is it now intended for non-test use?
There was a problem hiding this comment.
Same thing for spout. I think I need to add same comment from bolt and also mentioning that it doesn't support replaying so at-most-once semantic.
There was a problem hiding this comment.
I found myself dumb, I already implemented replay of messages.
| } | ||
| } | ||
|
|
||
| public static class MockStateUpdater implements StateUpdater<MockState> { | ||
| public static class MockBolt extends BaseRichBolt { |
There was a problem hiding this comment.
I think it could be helpful to use a JUnit TestRule (e.g. by subclassing http://junit.org/junit4/javadoc/4.12/org/junit/rules/ExternalResource.html) to help remember to clear VALUES after the test. It's easy to forget to clean up, and then the tests leak state.
Same for the other test utils that keep static state.
There was a problem hiding this comment.
Thanks for the information. I'll try to apply on that.
|
@srdo Thanks again for the detailed review. Addressed review comments. |
0f85cf7
to
b31d63e
Compare
c320c49
to
8fe6beb
Compare
|
Rebased to apply dropping standalone mode. |
|
@HeartSaVioR Are you still planning on getting this in? I could probably put some time in to trying this out if no one else is willing to test/use storm-sql, so we can get a +1. |
|
@srdo Applying the change manually again would be easier than rebasing, since there were nice efforts on storm-sql (checkstyle violation reduction, test config). It would take some efforts to apply the change without messing up current effort. I'll mention you when it's ready. Thanks again! |
|
@srdo |
docs/storm-sql-internal.md
Outdated
| @@ -1,59 +0,0 @@ | |||
| --- | |||
There was a problem hiding this comment.
I removed the document since it is documented based on Trident implementation. There're other docs for SQL example or SQL reference.
There was a problem hiding this comment.
I'm wondering if it would be worth updating this rather than removing it, or maybe merging parts of it into one of the other storm-sql docs (e.g. the overview doc). I think the page provides a nice overview of what storm-sql is, and how it works.
There was a problem hiding this comment.
@srdo
Agreed. Regarding updating the doc, I guess most parts of content are correct, but unfortunately I don't have resource for diagram so required to redraw one. I'd rather explain in content to avoid redraw one (like "Now Trident topology in a diagram is replaced to normal Storm topology"). What do you think?
There was a problem hiding this comment.
We could even do some photo editing but not sure it is easy to do since I don't know which font is used for storm-sql-internal-workflow.png.
There was a problem hiding this comment.
It would probably be pretty quick to duplicate with e.g. https://www.draw.io/, since it's just some boxes.
There was a problem hiding this comment.
Yeah right. I didn't think about that. Drawing a new one.
There was a problem hiding this comment.
Just finished it.
There was a problem hiding this comment.
Thanks, looks great. I think the dotted line box is missing the "StormSQL" label. Also maybe we should put the draw.io source file in the docs directory too, so we don't have to remake the diagram again if we need to change it later.
There was a problem hiding this comment.
The second diagram on the page also mentions Trident. I don't know if it makes sense to update, or just remove it.
There was a problem hiding this comment.
Nice finding. Will fix it and also will attach source file of draw.io, but not sure where to add.
I'll draw for second diagram as well.
There was a problem hiding this comment.
Looks pretty good to me. My only concern is the reduction in test coverage because the bolts in e.g. storm-sql-hdfs can't be stubbed, but as mentioned it's up to you whether you think it makes sense to try to preserve the tests or not.
I'll try checking this out and try out an example or two.
docs/storm-sql-internal.md
Outdated
| @@ -1,59 +0,0 @@ | |||
| --- | |||
There was a problem hiding this comment.
I'm wondering if it would be worth updating this rather than removing it, or maybe merging parts of it into one of the other storm-sql docs (e.g. the overview doc). I think the page provides a nice overview of what storm-sql is, and how it works.
| @@ -6,14 +6,14 @@ documentation: true | |||
|
|
|||
| The Storm SQL integration allows users to run SQL queries over streaming data in Storm. Not only the SQL interface allows faster development cycles on streaming analytics, but also opens up the opportunities to unify batch data processing like [Apache Hive](///hive.apache.org) and real-time streaming data analytics. | |||
|
|
|||
| At a very high level StormSQL compiles the SQL queries to [Trident](Trident-API-Overview.html) topologies and executes them in Storm clusters. This document provides information of how to use StormSQL as end users. For people that are interested in more details in the design and the implementation of StormSQL please refer to the [this](storm-sql-internal.html) page. | |||
| At a very high level StormSQL compiles the SQL queries to Storm topologies leveraging Streams API and executes them in Storm clusters. This document provides information of how to use StormSQL as end users. For people that are interested in more details in the design and the implementation of StormSQL please refer to the [this](storm-sql-internal.html) page. | |||
There was a problem hiding this comment.
There's a link to storm-sql-internal in this line
sql/README.md
Outdated
| - Not across batches. | ||
| - Limitation came from `join` feature of Trident. | ||
| - Please refer this doc: `Trident API Overview` for details. | ||
| Please see [here](../../docs/storm-sql.md) for details on how to use it. |
There was a problem hiding this comment.
Isn't this link going down by too many directories?
There was a problem hiding this comment.
Yeah my bad. Will fix.
| } | ||
|
|
||
| @Override | ||
| public Schema.TableType getJdbcTableType() { | ||
| return Schema.TableType.STREAM; | ||
| } | ||
|
|
||
| @Override | ||
| public boolean isRolledUp(String s) { |
There was a problem hiding this comment.
Nit: s doesn't really say much as a variable name, can we replace it with one that says what this string is? Same for the other methods here.
There was a problem hiding this comment.
OK will find origin methods and restore its origin names.
| StreamsScanRule.INSTANCE, | ||
| StreamsFilterRule.INSTANCE, | ||
| StreamsProjectRule.INSTANCE, | ||
| StreamsAggregateRule.INSTANCE, |
There was a problem hiding this comment.
Are we holding on to aggregate and join so they'll be easy to implement later, or why are the aggregate and join rules here?
There was a problem hiding this comment.
This is to have control to warn to the end users when aggregate or join is used in users' query. I didn't test if we don't have our own rule and user query trigger the feature. Yeah it is also good to not forget about missing features.
| tupleList.add(t0); | ||
| tupleList.add(t1); | ||
| return tupleList; | ||
| Assert.assertEquals(HdfsBolt.class, consumer.getClass()); |
There was a problem hiding this comment.
Looking at this again, I think the way to do it would be to use a factory like https://github.com/apache/storm/blob/master/external/storm-kafka-client/src/main/java/org/apache/storm/kafka/spout/internal/ConsumerFactory.java to instantiate the HdfsBolt. You could pass the factory class name in through a property and instantiate it when the data source is created. The default factory would just call new HdfsBolt().
I'm not sure if it's worth it. Up to you.
There was a problem hiding this comment.
Thanks for the information! I'll think about applying it but let me address other comments first.
| serField = props.getProperty(VALUE_SERIALIZED_FIELD); | ||
| } else if (props.contains(TRIDENT_VALUE_SERIALIZED_FIELD)) { | ||
| // backward compatibility | ||
| serField = props.getProperty(TRIDENT_VALUE_SERIALIZED_FIELD); |
There was a problem hiding this comment.
Nit: Since this is targeting 2.0.0, it might be okay not to provide backward compatibility.
There was a problem hiding this comment.
Yeah right, but it has been existing one and easy to support backward compatibility, so doesn't matter if we support it. We didn't deprecate it either.
| * The Bolt implementation for Socket. Only available for Storm SQL. | ||
| * The class doesn't handle reconnection so you may not want to use this for production. | ||
| */ | ||
| public class SocketBolt implements IRichBolt { |
There was a problem hiding this comment.
Nit: Consider extending BaseRichBolt instead, so you don't have to implement the methods you don't want to customize
There was a problem hiding this comment.
Yeah nice finding! Will fix.
|
|
||
| /** | ||
| * The Bolt implementation for Socket. Only available for Storm SQL. | ||
| * The class doesn't handle reconnection so you may not want to use this for production. |
There was a problem hiding this comment.
Does it make sense for us to include code like this if we know it isn't suitable for production use?
There was a problem hiding this comment.
You could do some experiments with your production query via replacing input table and/or output table to socket.
We may also want to have console output table (it can't be input table for sure) but we could address it from follow-up issue.
Please refer others' cases: Spark has couple of input sources and output sinks for testing, whereas Flink doesn't look like providing table sources and table sinks for testing. I'd rather feel better on Spark for this case.
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#input-sources
http://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#output-sinks
https://ci.apache.org/projects/flink/flink-docs-release-1.5/dev/table/sourceSinks.html
There was a problem hiding this comment.
Okay. It's fine to keep it, just wanted to make sure we didn't want to e.g. move it to /test
|
|
||
| @Override | ||
| protected void after() { | ||
| // no-op |
There was a problem hiding this comment.
Nit: I think you can leave out this method entirely
|
Tried out this branch with a storm-sql-kafka example, it seems to work fine. I hit a couple of newbie traps, will make sure to update the docs to help other people avoid them. The only change in behavior I noticed is that certain debug logs (e.g. ) are being printed to console during topology submit, rather than to the worker log. I don't think it's an issue, it was just a little surprising. |
|
@srdo |
|
I don't think we need to change it. I just wanted to make a note of it. When this has been merged, we might want to add a couple of notes about debugging to the docs, we can mention the log line there. |
|
The test failures look unrelated, not sure why it's suddenly failing. If they don't go away by rebasing to master, we might want to raise issues to track them. I don't know if you're looking at #2443 (comment), but we can probably make do without the tests for now. If so, it would be good to raise an issue to reintroduce them, the current tests are very minimal. +1 |
|
Yes test failures look unrelated, one is from server, another one is from cassandra. I'd like to address #2443 (comment) but OK to address it with new issue, since smaller patch would be easier to merge. |
|
Sounds good. |
|
Raised https://issues.apache.org/jira/browse/STORM-3153 for addressing restoring tests. |
|
@srdo storm-sql-internal-example.xml.txt If it works, I'll add these files into image directory or other directory (not sure) as well. |
|
They work fine for me. The example diagram had a typo (Fliter). |
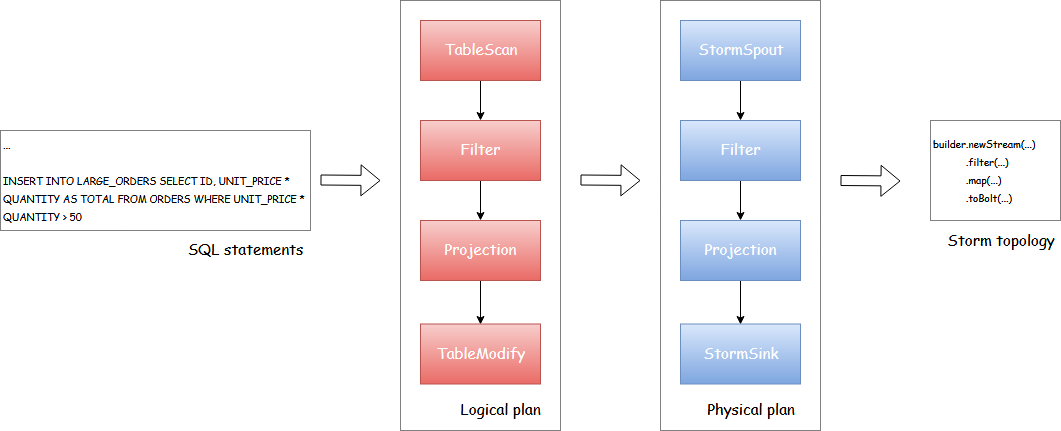
|
@srdo Nice finding. Fixed. Also exported to xml once again. Please check again. Thanks for your patience! |
|
Looks great. |
|
@srdo I'd like to get final review and approval from you to check if I miss anything before merging. Could you please help to do this? Thanks! |
|
I think all my comments were addressed, thanks for your patience. LGTM, +1. |
|
@srdo Thanks for the detailed review and nice suggestions! |
* This will enable us to provide windowed aggregation, join, etc. * Tuple-to-tuple is making more sense than micro-batch in these cases * Tested with several sql cases * Also bump Calcite version to 1.14.0 * Fix checkstyle issues a bit: not doing exhaustively * Update diagrams in storm-sql internal doc * Also add XML type of exported diagrams as well to restore diagram from draw.io
Even the patch looks like huge diff, most of things are rename classes/move packages.
I've also fixed some checkstyle issues.