[STORM-2905] Fix KeyNotFoundException when kill a storm and add isRem… #2618
Conversation
…oteBlobExists decide for blobs
| @@ -497,7 +497,6 @@ static DynamicState cleanupCurrentContainer(DynamicState dynamicState, StaticSta | |||
| assert(dynamicState.container.areAllProcessesDead()); | |||
|
|
|||
| dynamicState.container.cleanUp(); | |||
| staticState.localizer.releaseSlotFor(dynamicState.currentAssignment, staticState.port); | |||
There was a problem hiding this comment.
cleanupCurrentConatiner gets used in many different locations, not just during the blob update. We need to release the slot when the container is killed or reference counting will be off.
There was a problem hiding this comment.
yeah, but staticState.localizer.releaseSlotFor only remove topology base blobs[jar/code/conf] which are already taken care of by releaseSlotFor itself.
There was a problem hiding this comment.
That is not true.
The code first removes the base blobs reference counts, but then it decrements a reference count for other blobs too.
| @@ -94,17 +93,17 @@ public void cleanup(ClientBlobStore store) { | |||
| Map.Entry<LocallyCachedBlob, Map<String, ? extends LocallyCachedBlob>> rsrc = i.next(); | |||
| LocallyCachedBlob resource = rsrc.getKey(); | |||
| try { | |||
| resource.getRemoteVersion(store); | |||
| if (!store.isRemoteBlobExists(resource.getKey())) { | |||
There was a problem hiding this comment.
Admittedly the code is cleaner with this, but the change is totally unneeded. It behaves exactly the same as it did before. I think this is a good change, it would just be nice to have it be a separate pull request and a separate JIRA as it is not really a part of the needed fix.
There was a problem hiding this comment.
Ok, i will separate it apart with another JIRA.
|
I am trying to understand the reasons behind this change. Is this jira just to remove an exception that shows up in the logs? Or is that exception actually causing a problem? The reason I ask is a risk vs reward situation. The code in AsyncLocalizer is really very complicated and because it is asynchronous there are lots of races and corner cases. This makes me a bit nervous to start changing fundamental things just because of some extra logs. Additionally this is a distributed system and this particular race is inherent in the system. It is possible for someone to delete a blob at any point in time and the code in the supervisor needs to handle it. |
|
@revans2 I add a RPC api |
|
Part of this were written prior to the more to java8 so
Which is executing outside of a lock, but looks to not be thread safe. Declaring The javadocs clearly states that the next execution only starts a fixed delay after the previous one finished. There will only ever be one copy it running at a time. Additionally everything it does is already asynchronous so would be happening on a separate thread. Making it synchronized would just slow things down. The having a blob disappear at the wrong time is a race that will always be in the system and we cannot fix it with synchronization because it is happening on separate servers. The only thing we can do is to deal with it when it happens. The way the current code deals with it is to try again later. This means that a worker that is trying to come up for the first time will not come up until the blob is fully downloaded, but if we are trying to update the blob and it has disappeared we will simply keep the older version around until we don't need it any more. Yes we may log some exceptions while we do it, but that is the worst thing that will happen. |
|
Just FYI I files STORM-3020 to address the race that I just found. |
|
To me the race condition has none of the business of AsyncLocalize# From my cases the exception is throw from this code segment: private CompletableFuture<Void> downloadOrUpdate(Collection<? extends LocallyCachedBlob> blobs) {
//ignored
synchronized (blob) {
long localVersion = blob.getLocalVersion();
//KeyNotFoundException is thrown here
long remoteVersion = blob.getRemoteVersion(blobStore);
if (localVersion != remoteVersion || !blob.isFullyDownloaded()) {
try {
long newVersion = blob.downloadToTempLocation(blobStore);
blob.informAllOfChangeAndWaitForConsensus();
blob.commitNewVersion(newVersion);
blob.informAllChangeComplete();
} finally {
blob.cleanupOrphanedData();
}
}
}
//ignored
}When AsyncLocalizer start, it will start the two timer task: execService.scheduleWithFixedDelay(this::updateBlobs, 30, 30, TimeUnit.SECONDS);
LOG.debug("Scheduling cleanup every {} millis", cacheCleanupPeriod);
execService.scheduleAtFixedRate(this::cleanup, cacheCleanupPeriod, cacheCleanupPeriod, TimeUnit.MILLISECONDS);Although scheduleAtFixedDelay is event trig model and only one task will exec at a time, we still can not make sure which can exec first for this two timer task because the time cost of these two tasks are different. This bug happens because cleanup did after updateBlobs for killed storms overdue keys, so updateBlobs will still get a KeyNotFoundException. |
|
I just created #2622 to fix the race condition in AsyncLocalizer. It does conflict a lot with this patch, so I wanted to make sure you saw it and had a chance to give feedback on it. I understand where the exception is coming from, but what I am saying is that putting a synchronize on both cleanup and updateBlobs does not fix the issue. Adding in the synchronize only serves to slow down other parts of the processing. Even controlling the order in which they execute is not enough, because cleanup will only happen after the scheduling change has been fully processed. Perhaps some kind of a message sequence chart would better explain the race here.
The issue is not in the order of cleanup and checking for updates. The race is between nimbus deleting the blobs and the supervisor fully processing the topology being killed. Any time after nimbus deletes the blobs in the blob store until the supervisor has killed the workers and released all references to those blobs we can still get this issue.
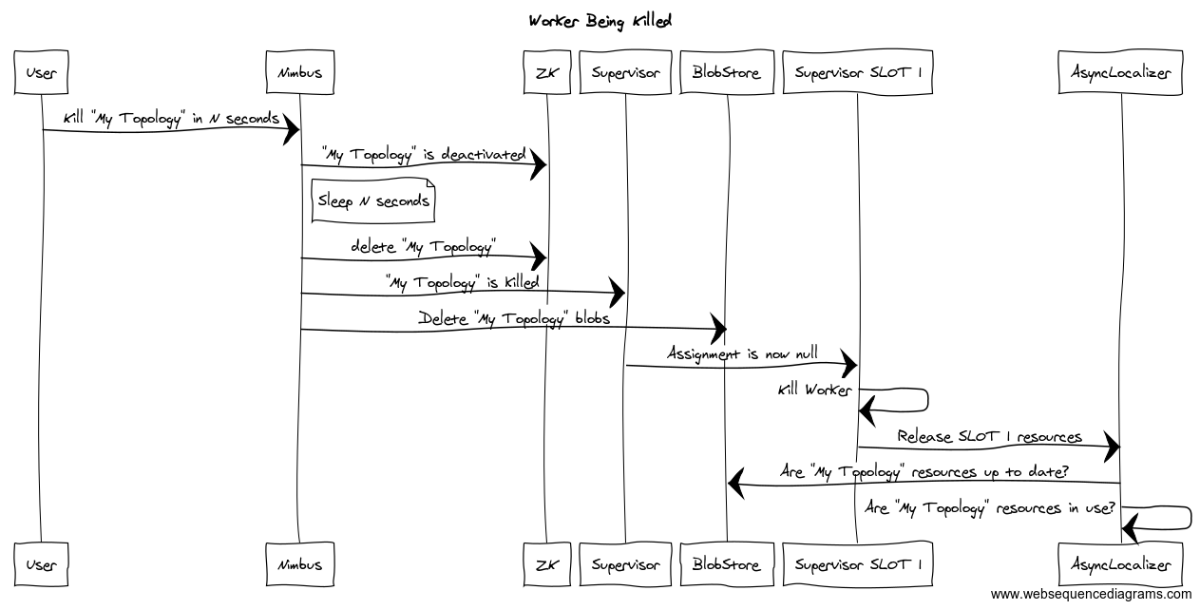
The above sequence is an example of this happening even if we got the ordering right. The only way to "fix" the race is to make it safe to lose the race. The current code will output an exception stack trace when it loses the race. This is not ideal, but it is safe at least as far as I am able to determine. That is why I was asking if the issue is just that we are outputting the stack trace or if there is something else that is happening that is worse than having all of the stack traces? If it is just the stack traces there are things we can do to address them. If it goes beyond that then I still don't understand the issue yet. |

|
@danny0405 But i still think we should handle this race condition reasonably as a normal and expectant case. It's a distribution system, so can the AsyncLocalizer decide based on master blob keys' existence when update local resources? A thrown stack trace it really confusing and non-necessary, especially when the blob-client try as configured max times to fetch a blob already removed from cluster. At lease we should not make a downloading request when we have removed the blobs, and should not decide the blob's existence based on a thrown KeyNotFoundException[ confusing too, because user have already killed/removed them on their own initiative ]. |
|
OK good I do understand the problem. There really are a few ways that I see we can make the stack trace much less likely to come out in the common case. The following are in my preferred order, but I am open to other ideas.
|
|
I am inclined to choose option 3 because:
But another situation is for the user archives and normal blob files, the model is: master make a event and AsyncLocalizer sync it at fixed interval, this model is too simple to handle this. I think there should be sync inform of PRC about add/remove events between blob-server/blob-client. Just make AsyncLocalizer sync it at fixed interval is ok, but we should not decide if blobs are remove based on KeyNotFoundException. |
|
@revans2 |
|
@danny0405 Sorry about the long delay. I also got rather busy with other things. My personal choice would be a combination of 1 and 2. We have run into an issue internally where very rarely where a blob may be uploaded to nimbus as part of submitting a topology and then the blob is deleted before the topology itself can be submitted. We are likely to fix this by using a variant of 1, something where we give ourselves a few mins after we see a blob with no corresponding topology before we decide it is fine to delete it. That should fix the issue in 99% of the cases, and also fix the upload issue. |
|
Just curious what the plan is fo this PR? |
|
Couple of comments back to @revans2 from Apr5.....
2018-06-25 21:49:03.928 o.a.s.d.n.Nimbus pool-37-thread-483 [WARN] get blob meta exception. |
|
@agresch |
When we kill a topology, at the moment of topology blob-files be removed, Supervisor executor may still request blob-files and get an KeyNotFoundException.
I stepped in and found the reason:
topologyBlobswhich is singleton to a supervisor node.topologyBlobsof killed storm only in a timer task: AsyncLocalize#cleanUp, the remove condition is :[no one reference the blobs] AND [ blobs removed by master OR exceeds the max configured size ], the default scheduling interval is 30 seconds. Here we may removetopologyBlobsoverdue keys if condition is matched.releaseSlotForto only remove reference on the blobs [topologyBlobsoverdue keys are still there].cleanupCurrentContainerto invoke AsyncLocalizer #releaseSlotForfor releasing the slot.updateBlobsto update base/user blobs every 30 seconds, which based on the AsyncLocalizer#topologyBlobsbased keys.topologyBlobsoverdue keys are only removed by its AsyncLocalizer#cleanUpwhich is also a timer task.updateBlobsmay update based on a removed jar/code/conf blob-keys and fire a exception[if the AsyncLocalize#`cleanUp not cleaned these keys], then retried until the configured max times to end.Here is how i fixed it:
releaseSlotForwhen there is no reference [no one used] on the blobs, and remove the overdue keys in AsyncLocalizer#topologyBlobsupdateBlobsand AsyncLocalizer #releaseSlotForby the same lock.releaseSlotFor[because we have already deleted them].getBlobMetaand catch a confusingKeyNotFoundException[both on supervisors and master log for every base blobs].This is the JIRA: STORM-2905