This project contains a serverless implementation of the OpenaAI GPT assistant. This project integrate the OpenAI API to provide real time response from an assistant that you can shape
- Serverless architecture
- Integration with OpenAI API
- Real-time responses
- Node 18
- Serverless Framework 3
- AWS CLI > 1.25.45
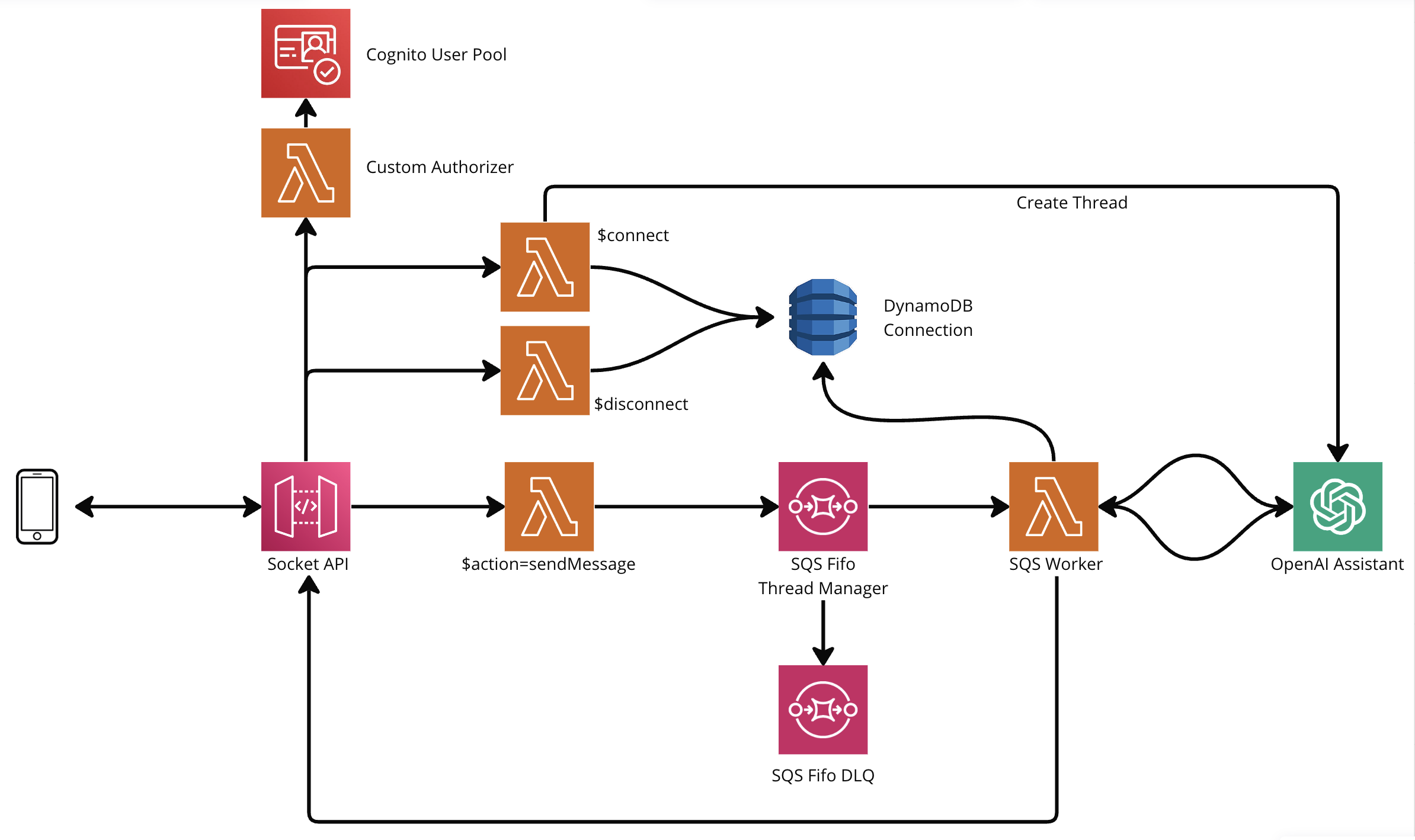
- Websocket API Gateway: used to both receive messages and send real time response
- Cognito User Pool: used to authenticate users and display how authentication & authorization is managed in websocket
- DynamoDB: used to keep track of the connections. uses a simple pk - sk structure to match users with connections.
- SQS FIFO: This queue manage the incoming messages. It is fifo to preserve the order of the messages within the userId MessageGroupId.
- Clone the repository.
- Install dependencies:
yarn
- Set up the AWS Profile and OpenAI API KEY on the env var.
- Create the GPT assistant using the assistant-scripts folder. Once you create the assistant, add the ASSISTANT_ID env var. To create the assistant, first edit the name, description and functions that you want to provide, then:
cd assistant-scriptsts-node createAssistant.ts --stage dev
- Deploy the service
yarn deploy:dev
If you your deploy fails with the error:
Cannot resolve variable at "constructs.threadManager.worker.environment.WEBSOCKET_API_ENDPOINT" Replace the variable with a random string and deploy, then place the original string and deploy again.
Connect to the websocket using any standard client (wscat is good too)
wscat -c wss://your.endpoint.com/dev?Auth={{accessToken}}
Then send messages using this structure:
{ "action": "sendMessage", "message": "Hey, how is it going?" }
This project uses OpenAI Assistant API to create, edit and interact with an assistant.
The Class that you find in src > model > OpenAIAssistant.ts wrap the openAI api and simplify the interaction with it. You can pass to this class all the functions that you have defined for the assistant and define system based parameters.
Since OpenAI Assistant api do not provide a streaming for the response nor any hook system, the class implement an exponential backoff retry system to check when the response is provided.
This project is meant to be a starting point for whatever use case you might have. It's not flawless nor production ready of course. You can start from this project and build features on top of it to meet your business requirements.
Contributions to the Serverless GPT Assistant are welcome.
This project is licensed under the MIT License. Please see the LICENSE file for more details.