
Arachnio client library for Java 11+
First, you'll need to subscribe to an Arachnio product. The Free Forever Plan is just fine for this introduction. Before we head to the next step, you'll need your Base Product URL and one of your Bloblr API Keys.
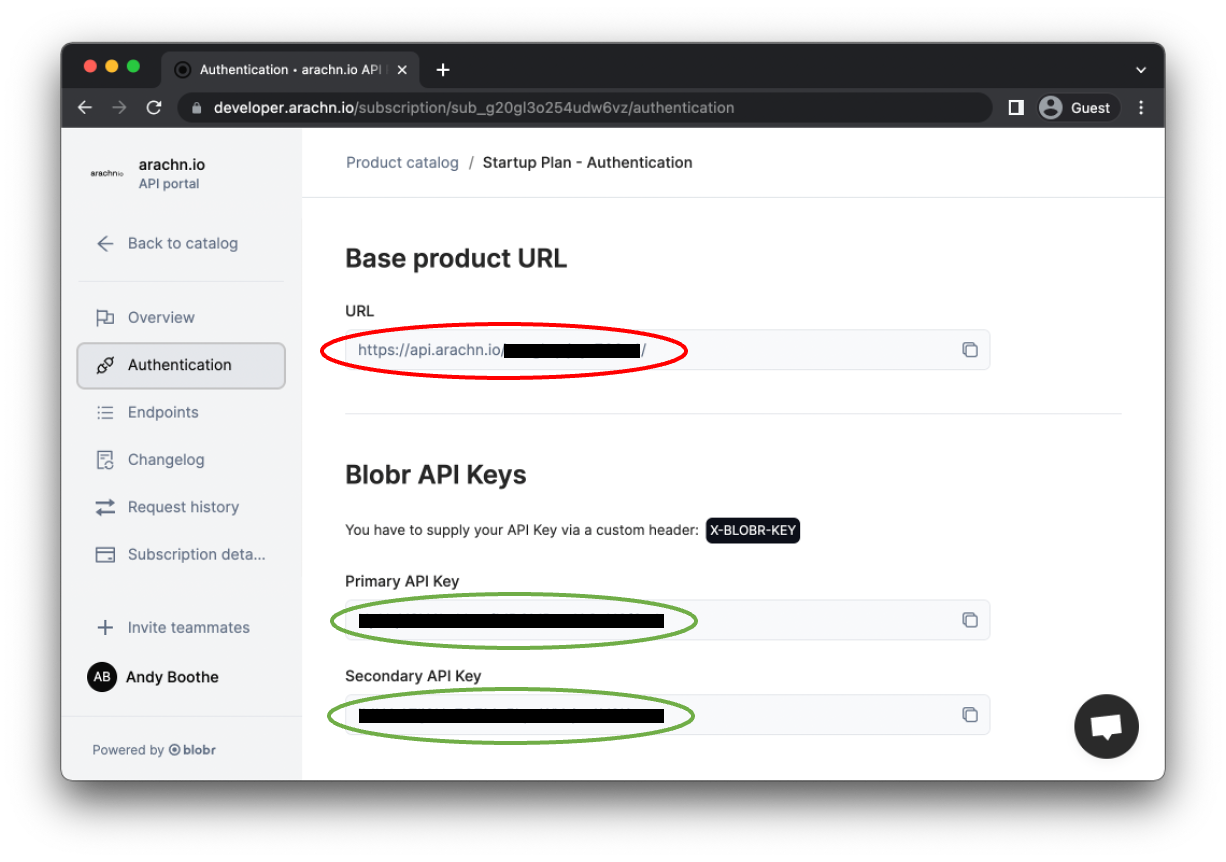
Above is a screenshot of the Subscription Authentication screen, which contains these facts. The Base Product URL is circled in red, and the Blobr API keys in green. Both are redacted for privacy. 🤫
In this introduction, we will extract structured data from a webpage, so the next step is to pick a webpage to extract. In the spirit of web crawling, we have picked an article about spiders for this example. 🕷

Now that we have our base URL, API key, and parameters, we can call the link extract endpoint!
ArachnioClient client=new DefaultArachnioClient(ARACHNIO_BASE_URL, BLOBR_API_KEY);
ExtractedLink response = client.extractLink(
"https://www.nytimes.com/2022/08/25/science/spiders-misinformation-rumors.html");
if(response.getEntity() instanceof ArticleWebpageEntityMetadata article) {
System.out.println(article.getTitle());
// Spiders Are Caught in a Global Web of Misinformation
}