Deploying the super-resolution convolution neural network (SRCNN) using Keras
This network was published in the paper, "Image Super-Resolution Using Deep Convolutional Networks" by Chao Dong, et al. in 2014. Referenced Research Paper https://arxiv.org/abs/1501.00092.
uUsing the same images that were used in the original SRCNN paper. We can download these images from http://mmlab.ie.cuhk.edu.hk/projects/SRCNN.html (matlab code - set5 and set14 images into "images folder").
The SRCNN is a deep convolutional neural network that learns end-to-end mapping of low resolution to high resolution images. As a result, we can use it to improve the image quality of low resolution images.
To evaluate the performance of this network,used image quality metrics:
- peak signal to noise ratio (PSNR),
- mean squared error (MSE), and
- structural similarity (SSIM) index.
We will also be using OpenCV to pre and post process our images. Also, there is frequent converting of our images back and forth between the RGB, BGR, and YCrCb color spaces. This is necessary because the SRCNN network was trained on the luminance (Y) channel in the YCrCb color space.
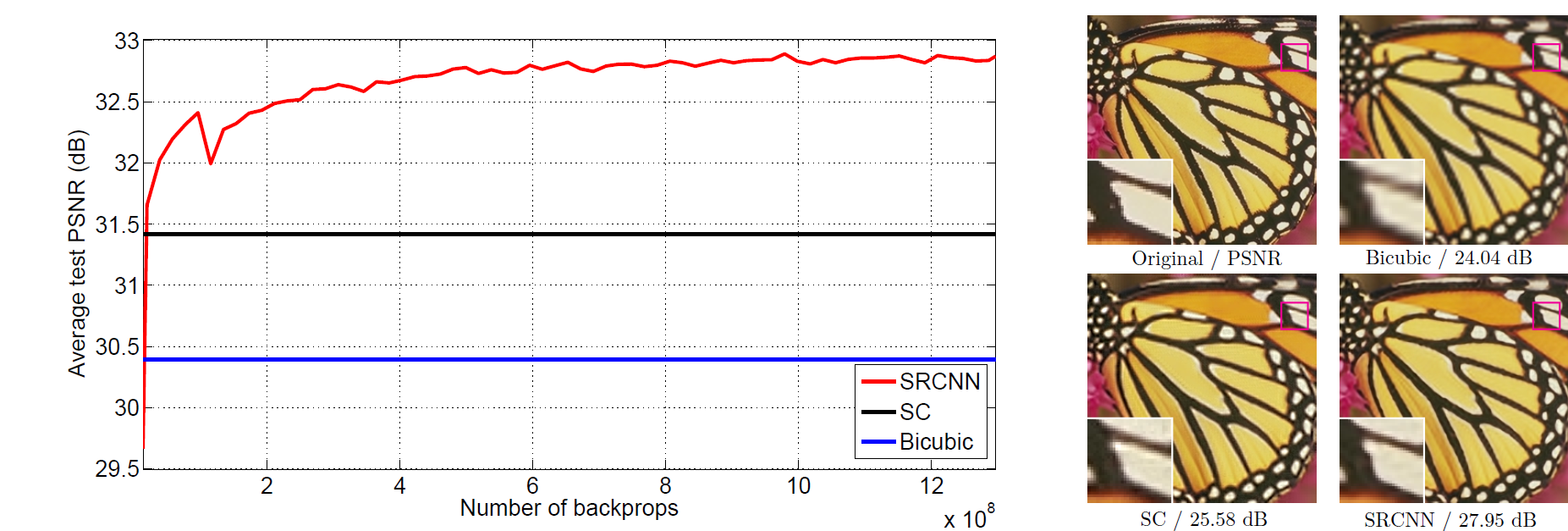
The proposed Super-Resolution Convolutional Neural Network (SRCNN) surpasses the bicubic baseline with just a few training iterations, and outperforms the sparse-coding-based method (SC) with moderate training. The performance may be further improved with more training iterations.
- Prepare degraded images by introducing quality distortions by resizing up and down: new image(degraded) are of same resolution as base images.When sizing down the image we store the original pixel info in smaller area so we lost that info when sizing up the image. This was done using OpenCV(cv2 library), it is incredibly fast as it is designed for real time computer vision application. The degraded images are put into source folder.
- Building the SRCNN Model:
# define model type
SRCNN = Sequential()
#add model layers;filters = no. of nodes in the layer
SRCNN.add(Conv2D(filters=128, kernel_size = (9, 9), kernel_initializer='glorot_uniform', activation='relu', padding='valid', use_bias=True, input_shape=(None, None, 1)))#only if in keras.json image_data_format is channels_last; else if channels_first then 1,None,None
SRCNN.add(Conv2D(filters=64, kernel_size = (3, 3), kernel_initializer='glorot_uniform', activation='relu', padding='same', use_bias=True))
SRCNN.add(Conv2D(filters=1, kernel_size = (5, 5), kernel_initializer='glorot_uniform', activation='linear', padding='valid', use_bias=True))
#input_shape takes image of any height and width as long it is one channel
#that is how the SRCNN handles input,it handles image slice inputs, it doesn't work at all 3 channels at once
#SRCNN was trained on the luminescence channel in the YCrCb color space
# define optimizer
adam = Adam(lr=0.0003)
# compile model
SRCNN.compile(optimizer=adam, loss='mean_squared_error', metrics=['mean_squared_error'])
-
Pre-processing the images: This processing will include cropping and color space conversions.load the degraded and reference images, in opencv, images are loaded as BGR channels
-
modcrop(): #necessary because when we run images through SRCNN based on the kernel sizes and convulational layers, we are going to lose some of these outside pixels,the images are going to get smaller and that's why it is neccesary to have a divisible image size,ie, divisible by scale by cropping the images size
-
shave(): crop offs the bordersize from all sides of the image
-
-
Load(deploy) the SRCNN: To save us the time it takes to train a deep neural network, we will be loading pre-trained weights for the SRCNN. These weights can be found at the following GitHub page: https://github.com/MarkPrecursor/SRCNN-keras
-
Testing the model: Once we have tested our network, we can perform single-image super-resolution on all of our input images. Furthermore, after processing, we can calculate the PSNR, MSE, and SSIM on the images that we produce.
- convert the image to YCrCb(3 channel image) - (srcnn trained on Y channel)
- create image slice and normalize cuz SRCNN works on one dimensional input(or 3D inputs of depth 1 ,ie, inputs with one channel)
- perform super-resolution with srcnn
- post-process output normalized prediction image back to its range(0-255)
- there is only the luminescence channel in the prediction image ,Socopy Y channel back to image and convert to BGR
- remove border from reference and degraded image, so that all our images(ref,degraded(low res.), and ouput(high res.)) are of the same size
- image quality metric calculations: All the image quality metrics got better; PSNR increased, MSE devreased and SSIM increased from degraded image to reconstructed image
- save the new high resolution images to output folder