ccrawler is a distributed crawler framework use celery+gevent+redis.
It use celery, a Distributed Task Queue, to distributed cralwing. redis is used for broker of celery. gevent is used for async socket.
- docker
- python2.7
- python2-requests
- python2-celery>=3.1.13
- python2-gevent
- python2-redis
- python2-beautifulsoup4
- python2-pymongo
- python2-pybloom
- python2-couchdb
- python2-jieba
Add a new python module or package under the crawlers/ directory.
e.g. crawlers/example.py
Run ./bin/newcrawler.py crawler_name to generate a new python module crawlers/crawler_name.py
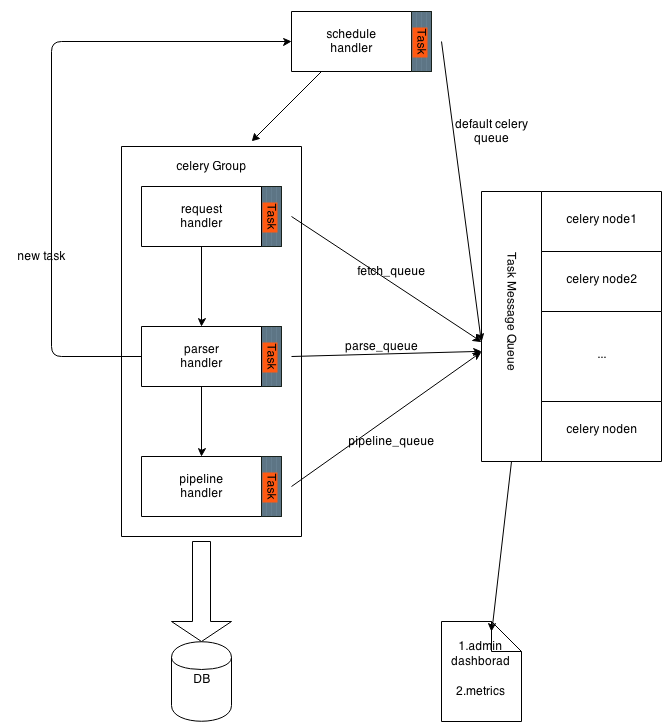
You need write 4 classes:
-
RequestHandlerRewrite the
handle(self, task, use_proxy=False, **kwargs)method.Task is a python dict contains the
url. This method used to fetch the page. You can just callBaseRequestHandler.handle. The return value is dict contains response. -
ParseHandlerRewrite the
handle(self, task)method. Task is a python dict containsresponse. This method used to parse the content of web page. The return value is a tuple in the form(task, new_tasks).taskcontains parsed result, new_tasks is the list contains new tasks. -
SchedulerRewrite the
init_generator(self)method. Return aiterator(list, tuple etc.) orgeneratorwhose item is init task. -
PipelineRewite the
process(self, results)method. Results is a list contains multi results. This method used to save the result to disk. For couchdb, you can just callbasePipeline.save_to_couchdbmethod, whose param is a result to save. Or you can callbasePipeline.print_resultto print the result...
Bellow is the example crawler code:
# -*- coding: utf-8 -*-
"""
example.py
~~~~~~~~~~
"""
import os
import sys
current_path = os.path.dirname(os.path.abspath(__file__))
sys.path.append(os.path.join(current_path, '..'))
sys.path.append(os.path.join(current_path, '../..'))
from request.baseRequestHandler import BaseRequestHandler
from parse.baseParseHandler import BaseParseHandler
from schedule.baseScheduler import BaseScheduler
from database.basePipeline import BasePipeline
import time
import datetime
import json
from bs4 import BeautifulSoup
class RequestHandler(BaseRequestHandler):
def handle(self, task, use_proxy=False, **kwargs):
task = super(RequestHandler, self).handle(task)
return task
class ParseHandler(BaseParseHandler):
def handle(self, task):
r = task['response']['content']
soup = BeautifulSoup(r, "lxml")
new_tasks = []
if task['url_depth'] < 2:
for link in soup.find_all('a'):
if link.get('href', '').startswith('http') and not link.get('href', '').endswith('exe'):
item = {'url': link.get('href'), 'url_depth': task['url_depth']}
new_tasks.append(item)
return task, new_tasks
class Scheduler(BaseScheduler):
def init_generator(self):
task = {
'url': 'http://qq.com',
}
yield task
class Pipeline(BasePipeline):
def process(self, results):
for r in results:
self.print_result(r)
pass
if __name__ == '__main__':
from bin.stand_alone_run import BaseCrawler
crawler = BaseCrawler(RequestHandler(), ParseHandler(), Scheduler(), Pipeline())
crawler.run()Then register the crawler in celeryconfig.py as following:
crawlers = [
{
'name': 'weibo',
'requestHandler': weibo.RequestHandler(use_proxy=0),
'parseHandler': weibo.ParseHandler(),
'scheduler': weibo.Scheduler(),
'pipeline': weibo.Pipeline(),
},
] You can just run the crawler module to run in stand-alone mode.
For distributed mode.
Run celery worker with four queues: schedule, parse, pipeline, request
Run ./bin/run_queue.sh ${node_name} ${queue_name}[,more_queue_name] $concurency to run a queue.
e.g. ./bin/run_queue.sh request1 request 100, ./bin/run_queue.sh node1 request,parse 200.
After run schedule, parse, pipeline, request queues, use ./bin/run.py to run the crawler.
docker build -t crawler .And then
docker run -v $PWD:/code -w /code -d centos:celery ./bin/run_queue.sh ${queue}${node}_1 ${queue} $concurency
Or just run ./run_in_docker.sh, but don't forget to change the node name in run_in_docker.sh
Then ./bin/run.py
All the configuration is in the config.py and celeryconfig.py. Former is universal configuration and the latter is configuration related to celery.
The configuration is a object. Some critical argument:
## crawl control
error_retry_cnt = 3
retry_time = 10 # seconds
max_retries = 3
rate_limit = '1000/s'
time_limit = 100
max_task_queue_size = 1000 # max length of task queue
task_batch_size = 100
new_task_check_interval = 7
broker = 'redis://127.0.0.1'
proxy_pool = {'host': '127.0.0.1', 'port': 6379} # if use
tasks_pool = {'host': '127.0.0.1', 'port': 8888}
rfilter_redis = '127.0.0.1'
task_pool_key = 'newtasks'
couchdb = 'http://127.0.0.1:5984/' # if use
couchdb:
CouchDB won’t recover from this error on its own. To fix it, you need to edit /usr/bin/couchdb(it’s a Bash script). At the beginning of the script, there’s a variable named RESPAWN_TIMEOUT. It’s set to 0 by default, simply change it to say 5 and restart CouchDB. That should fix it.