{kind=link}
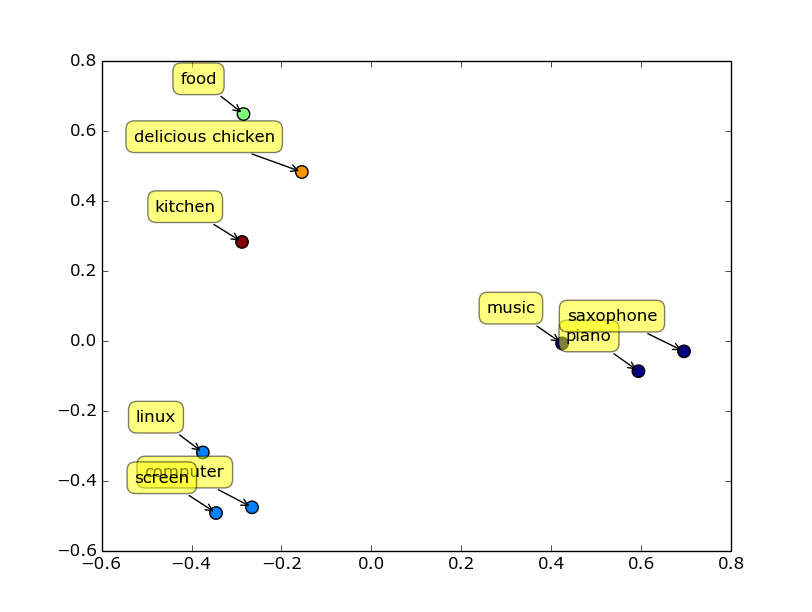
Word2Vec + Principal Component Analysis + Clustering for low-dimensional semantic representation of a set of words or compositional MWEs.
Make sure you have at least 10GB of RAM available before running the script
Require python and the following packages :
gensim, numpy, scipy, matplotlib, sklearn, nltk (+ english stopwords dictionnary).
As well as the pre-trained word2vec model on Google News (heavy, decompress it in the same folder) : https://drive.google.com/file/d/0B7XkCwpI5KDYNlNUTTlSS21pQmM/edit
Enter words or MWEs > food,kitchen,delicious chicken,music,piano,saxophone,computer,screen,linux