Multiple AZ/subnets support #3576
Comments
|
Hello zbarr, Thank you for the information. Multiple AZ support is a popular feature request. We are discussing this and will let you know any progress. Cheers, |
|
Any updates or timelines for the multiple AZ support? |
|
We don't have yet a timeline to share for this feature enhancement. An high level alternative is to use Slurm Federation to manage multiple Slurm clusters. See Workshop: Using AWS ParallelCluster for Research. |
|
I successfully did multi-AZ / multi-subnet with ParallelCluster 2.11.3 running SGE. I am not sure if the issues people are seeing are SLURM-specific, or if there's something else I'm doing right here that AWS doesn't necessarily know about. @enrico-usai , can you weigh in? We are using: scheduler = sge with As you can see in the screenshots, simply changing the ASG causes the autoscaler to spot request in multiple AZs, and running jobs span across the AZs:
|




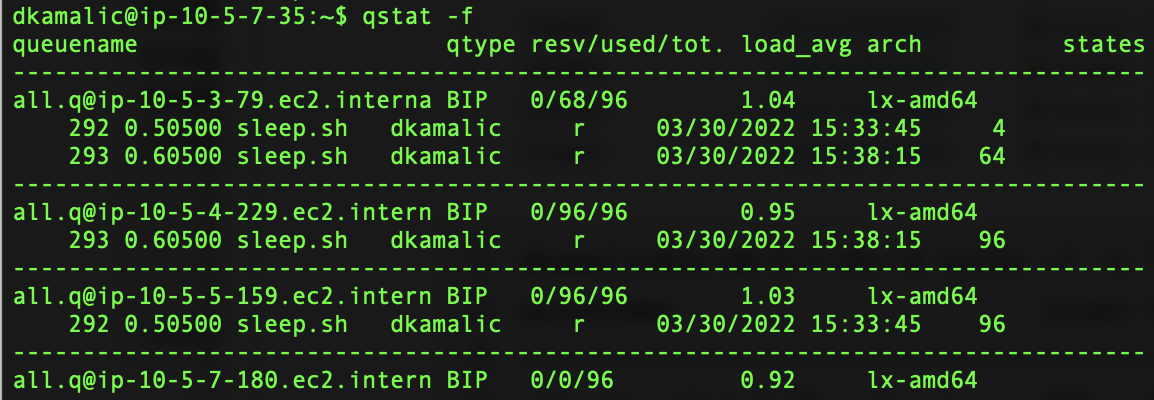
|
Hi @gns-build-server, thanks for your contribute! Your approach works with SGE (or Torque) because ParallelCluster uses ASG to manage compute fleet, so by manually modifying the ASG you're adding more capabilities to your cluster. This is not a suggested approach because you're manually modifying resources created by ParallelCluster so this can causes unexpected issues. Then this approach has some limits, for example the instance types you can use for compute fleet must be in the same avail zone. For Slurm (starting from ParallelCluster 2.9.0) this approach cannot work because we moved away from ASG and we're using Slurm Cloud Bursting native support, providing a better integration with AWS. As part of 2.9.0 we also introduced support for multiple queues and multiple instance types. With this issue we're tracking the possibility to natively use multiple Availability Zones together with different instance types, for example to overcome capacity limits. |
|
@enrico-usai That's what I was worried about. If there is no roadmap for the functionality to use multiple AZs in Parallelcluster with SLURM, then this is a dealbreaker for us to move onto Parallelcluster 3.0 where the SGE scheduler no longer exists. For us to continue using Parallelcluster without SGE and ASGs, we will absolutely need multiple availability zones, because at the scale we are runinng, we frequently run into capacity limits when stuck in single AZs, and using SLURM Federation to federate between multiple-clusters is a non-starter for our product. I would like to chime in with the other voices requesting a timeline for the ability to natively use multiple AZs together with the "different instance types" built into Parallelcluster >=2.9.0 in order to overcome capacity limits. It is vital for us to be able to continue using Parallelcluster beyond the version we're currently stuck at, which according to https://docs.aws.amazon.com/parallelcluster/latest/ug/support-policy.html, will reach its End-Of-Support date on 12/31/2022. |
|
@gns-build-server +1, @enrico-usai, we are also stuck due to the same limitations. |
|
@gns-build-server, @devanshkv, @zbarr could you please add more details about your use-cases? |
|
@enrico-usai, this is due to the GPU capacity issues. |
|
If I can chime in, My particular use case, we use HPC to run processing pipelines which also contain GPU isntances. |
|
@enrico-usai , We find that when we run our application, (using spot, with 96-VCPU nodes such as m6a.24xlarge and m6i.24xlarge), we frequently find ourselves unable to get capacity if we are stuck with a single AZ. We primarily run in US-East-1. Like @lletourn , we are not latency bound as our application is mostly embarrassingly parallel, and we run at large scale so capacity frequently becomes an issue. Our clusters will frequently scale to 50-100 96-VCPU nodes when the queue is stacked with jobs, but capacity issues don't only crop up when the queue is stacked. Before implementing the multi-subnet ASG method I described in my post above, we frequently found a cluster unable to get even a single node even when it's currently at zero nodes. The cluster would never get the node, or the node would come up for a minute and then immediately get interrupted. What we found ourselves doing in that case is looking at the Spot Advisor and trying to guess, according to the "% interruption" column for our region, which instance types we should change the cluster to. Even this doesn't work well, because we frequently find that the Spot Advisor is indicating low % interruption and we still can't get any capacity for that instance type in a particular AZ. My suspicion is the Spot Advisor will indicate low % interruption even when one or more AZs in a region are out of capacity, as long as there are some AZs in the region that still have high capacity. So we try another. And then we find that one can't get capacity either. So we try another. And that one can't get capacity either. So we try to outsmart it a bit, and say "Well, there are particular instance types, like m5 versus m5d or m5dn, that AWS clearly owns "more of", so let's prefer those instance types even when the Spot Advisor shows them as having higher interruption." And then, eventually, we hit on one that might actually have some capacity. For now. Tomorrow, it might be different. This frankly, makes the Spot Advisor incredibly frustrating to get any useful information out of in a single-AZ situation. If we were to move to SLURM right now, we could potentially mitigate this a bit by having multiple instance types set even within a single AZ, but we do that with StarCluster (VanillaImprovements fork) already, and it doesn't really work well even in the situation where we have multiple instance types set, ever since StarCluster's AZ choice mechanism became broken due to AWS's changing how they do pricing. (StarCluster always prefers whichever AZ/instance type combination in your "instance type array" has the cheapest price, modified by whatever weighting factor you assign to prefer certain instance types even at higher current price. Ever since, a couple of years ago, AWS changed how spot pricing works such that an AZ with low capacity no longer has HIGHER price, this mechanism became broken. It used to be that if an AZ had no spot capacity for that instance type, the price shot up to 10X the on-demand price, and the StarCluster would always choose a lower-priced AZ for that instance type, or a different instance type in a lower-priced AZ. After AWS made that change -- without warning customers, I might add -- a pure price-prioritized spot mechanism like StarCluster's will frequently get stuck in a single AZ because it may be the lowest priced one even though it has zero spot capacity.) Because of our extensive experience having terrible capacity problems when getting stuck in a single AZ, even when trying to switch between a handful of instance types appropriate for the application, we are not going to move from SGE to SLURM on ParallelCluster 3.0+ until multi-AZ in SLURM on ParallelCluster is available and works at least as well as it does with SGE/ASG's on ParallelCluster right now as I outlined in my method above. The urgency now is that your ending support for ParallelCluster 2.11.x on 12/31/22 makes us feel like we're in limbo with the plans to move to SLURM and ParallelCluster 3.0.x. For the record, Azure CycleCloud does great with this functionality. Just sayin'. |
|
I haven't chimed in since I opened this up in December, but my anticipation that we would need this was warranted as we're hitting capacity issues now. Use case: Multiple clusters for different groups of users, spinning up jobs of 50-100 SPOT instances (for now), ideally across multiple AZ's in a region and ideally across multiple generations of the same spec'd resource type. Problem: We hit capacity limits. We were using 6th gen Intel c nodes but found that capacity was limited so we switched to 5th gen. Although multiple "ComputeResources" somewhat works, I found that when it would hit capacity limits on one of the resource types, slurm/pcluster wouldn't always grab from the other resource type. That is almost irrelevant though (for this issue), because if I was able to span multiple AZ's, I would be less likely to run into these capacity issues in the first place. For now, I have tried to put different clusters (since we have multiple) into different AZ's so they don't step on each other but this manual balancing is proving to be a pretty tedious and is burning time on something that should otherwise be automated. If we had this feature, along with maybe a smoother mechanism for using multiple instance types within the same queue, I would consider this product 100% complete for our use case. |
|
Also, based on looking at #3114 , I suspect @tanantharaman and @hy714335634 also have a good usage case here. |
|
I've done some work on multi-AZ support for Slurm based on PCluster 3.1.1. Anyone interested in this can find the code here, and follow the user guide to have a try. |
|
Thank you for going deep on this issue and we truly appreciate the efforts and are also looking into some for the great ideas discussed here. |
Thank you, @Chen188 -- I will try this! I would encourage @enrico-usai to look at it, since of course we want them to incorporate this -- or something like it -- into the main branch rather than us having to run a custom build in our productionalized environment. |
|
Any news on this? We are hitting ressource limits rather frequently. This morning for example: |
|
+1 on this. seems like the spot capacity is getting more and more competitive in us-east-1. since we host our data on s3 in this region, it is important that we can run our cluster in the same reason so we don't incur heavy data-transfer costs. the broader the pool of spot inventory we can access, the better this will work. or amazon can add more capacity and there won't be a need for this feature... |
|
Large scale HPC without this feature is almost impossible. I've changed my approach to a custom head node with AWS plugin for Slurm (https://github.com/aws-samples/aws-plugin-for-slurm )that supports multiple subnets. I've also made a fork to add headnode high availability support, more flexible node hostnames, and HTTPS proxy support (https://github.com/pauloestrela/aws-plugin-for-slurm). |
|
@pauloestrela probably not relevant for you since you're on slurm, but i have managed to get awsbatch working with multiple AZ's. I basically bypassed the compute-environment and job-queue created by pcluster and created my own. the only real difference is to add more subnets to the "computeResources" section of the compute-env. i'm not sure if this breaks some features of pcluster, but i think for my case it is fine because my compute nodes do not need to communicate with each other. this method has the added benefit that you can use your own container image instead of the pcluster one (also specified in the compute-environment), assuming you use pcluster's entrypoint script (in this github repo) and add all necessary dependencies, it is able to mount the shared volume and integrate successfully. |
|
us-east-1 is completely packed so it's unlikely they'll be able to add capacity anytime soon. I've talked to support a couple of times, and I've gathered that while there were sometimes 800+ M5.4xlarge available in 1a at the time they checked, you still cannot get any spot because this head-room literally swing to 0 in minutes..
We've pretty much completely gave up running spot there.. if someone knows of 64GB+ types that usually have capacity I'll gladly take the tip!
…________________________________
From: msherman13 ***@***.***>
Sent: Friday, October 21, 2022 8:43:05 AM
To: aws/aws-parallelcluster ***@***.***>
Cc: Quentin Machu ***@***.***>; Manual ***@***.***>
Subject: Re: [aws/aws-parallelcluster] Multiple AZ/subnets support (Issue #3576)
+1 on this. seems like the spot capacity is getting more and more competitive in us-east-1. since we host our data on s3 in this region, it is important that we can run our cluster in the same reason so we don't incur heavy data-transfer costs. the broader the pool of spot inventory we can access, the better this will work. or amazon can add more capacity and there won't be a need for this feature...
—
Reply to this email directly, view it on GitHub<#3576 (comment)>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AZRAAOXN44XFDSH56FHJRPLWEKMWTANCNFSM5JQITKNA>.
You are receiving this because you are subscribed to this thread.Message ID: ***@***.***>
|
|
Coming back here one more time to emphasize how helpful this would be. As this is the most discussed open issue for this project, I think we can all agree that this feature would have a huge impact! |
|
Hello all, |
There's an issue open for this but it is specifically for awsbatch whereas I need this for Slurm. Our own proprietary "Slurm with AWS" implementation had this so we've gone backwards a bit in that respect by moving to ParallelCluster. Hoping you guys are able to get to this soon! Documentation indicates it's coming.
The text was updated successfully, but these errors were encountered: