[FOSS] hot fix and improvement #2207
Conversation
 mingkun2020
commented
mingkun2020
commented
Nov 4, 2021
- Companion stack for MSK, MQ tests
- Throttling handle mechanism
- Option for adding pipeline name as testing stack prefix
- Update template runtime version
integration/resources/templates/combination/function_with_all_event_types.yaml
Outdated
Show resolved
Hide resolved
| try: | ||
| return func(*args, **kwargs) | ||
| except exc: | ||
| sleep_time = random.uniform(0, math.pow(2, retry_attempt) * delay) |
There was a problem hiding this comment.
What's the reason for adding jitter?
Shouldn't sleep time be calculated by delay +/- jitter instead of a random int between 0 to max delay?
The current approach on a 10th retry can range from 0 to 512 seconds. This seems to be a large range and I'm not sure what that will accomplish.
There was a problem hiding this comment.
The Cloudformation'sdescribe_stack api that we use to check the stack status has hard limit(maybe 10 calls per sec) and cannot be changed. Since we run the tests in parallel(for example 10 thread in concurrent), we will have 10 calls in the same time(imagine a big call cluster in a small time frame). So we need to add jitter(add some randomness) to spread the calls over a large time frame to avoid the throttling. If we just use exponential back off, the call cluster will appear once again after exponential time and won't solve the issue, therefore we need the jitter.
delay +/- jitter similar to the Equal jitter and the one I used here range from 0 to exponential delay is a Full jitter. They don't have much different in performance. More detail can be referred from this blog: https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/
There was a problem hiding this comment.
Why is the final delay generated with a random between 0 to max delay instead of plus minus a percentage of the max delay?
In the example of 10th retry, it could have only 1 second delay which defeats the purpose of exponential backoff.
There was a problem hiding this comment.
Green as minimal, Red as maximum, and Purple as average.
This is the current implementation:
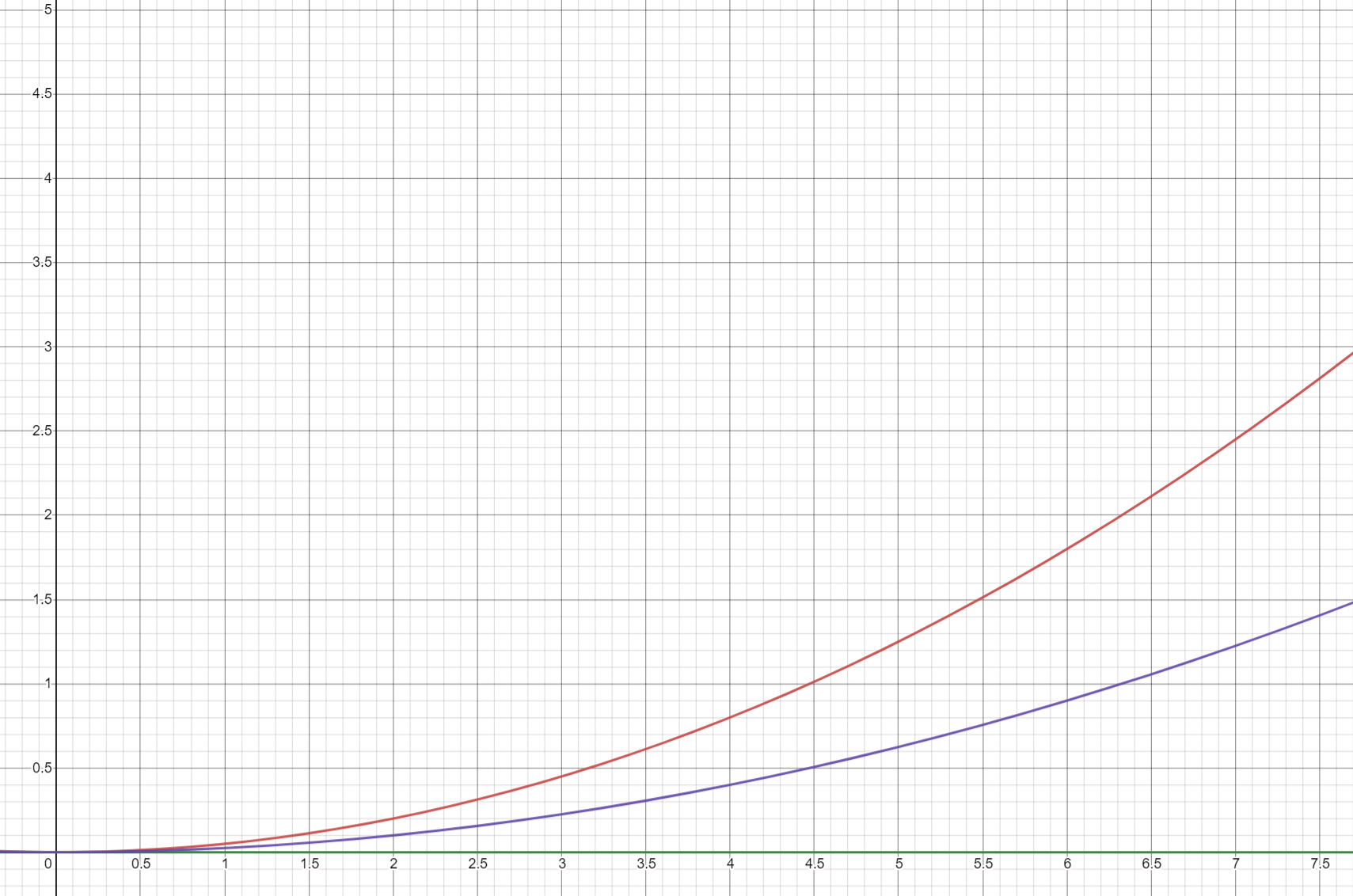
The minimal seems off to me and a really large range as retry count increases.
With a percentage based jitter:
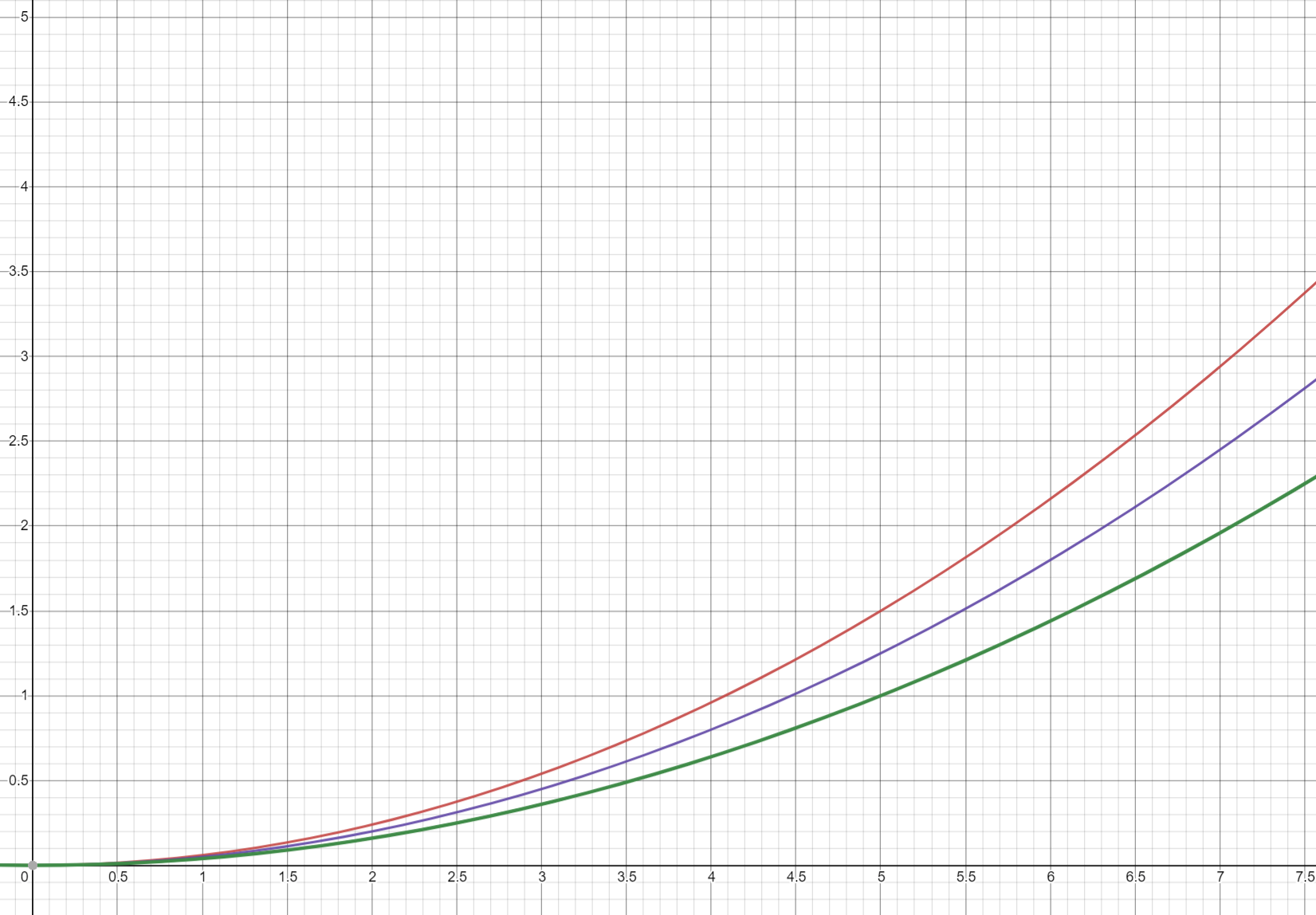
There was a problem hiding this comment.
Our goal is trying to spread the api calls among the test time frame as even as possible(If we use delay + jitter we might have some time block with no call). Thinking now how to do some simulation about this.
There was a problem hiding this comment.
Tracking:
Current implementation is following the blog post: https://aws.amazon.com/blogs/architecture/exponential-backoff-and-jitter/
One assumption the blog post makes is that the calls will continue to happen until the job is complete. However, in our case, we will fail the test if it fails after an x amount of retries. Although the total amount of "Work" is less, there could be a case where a job rolls low numbers for 5 times and fails the execution.
I think there is a better solution for our use case than either full jitter or equal jitter.
@mingkun2020 will work on a simulator for our use case specifically to test out different approaches.
This comment is not blocking.
Codecov Report
@@ Coverage Diff @@
## develop #2207 +/- ##
===========================================
- Coverage 94.43% 94.33% -0.11%
===========================================
Files 95 95
Lines 6558 6598 +40
Branches 1325 1331 +6
===========================================
+ Hits 6193 6224 +31
- Misses 169 179 +10
+ Partials 196 195 -1
Continue to review full report at Codecov.
|

| @@ -1,5 +1,7 @@ | |||
| import hashlib | |||
|
|
|||
| import pytest | |||
There was a problem hiding this comment.
Unused import, removed it.
| deployments = self.client_provider.code_deploy_client.list_deployments()["deployments"] | ||
| deployments = self.client_provider.code_deploy_client.list_deployments( | ||
| applicationName=application_name, deploymentGroupName=deployment_group | ||
| )["deployments"] |
There was a problem hiding this comment.
For client responses like this are we catching any possible client errors? Also if the client returned a None response due to some error ["deployments"] would also be error prone? (Maybe get("deployments") would be a better option
There was a problem hiding this comment.
If it returns a None, it will break and the test will failed as expected(it shouldn't be none).
Reviewer is busy on other tasks and this pr already get get 2 approvals