When I use the #898 code, there are some problems #941
Comments
|
Have you tried using MXNet version: |
|
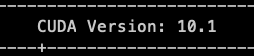
Hey bro, I found something different, It might be helpful. When i use following versions of the package. Everything work normally except num_workers can't set. EnvironmentMXNet version: mxnet 1.4.1 |
So problem 1 & 2 disappeared, but again, multiprocessing doesn't work? |
Yes, but this time I use cpu, it is very slow |
|
@k-user does the problem still occur? |
|
I wrote a little demo to test it, but it still gave me an error. This is data:This is my code:import pandas as pd
from gluonts.dataset import common
from gluonts.model import deepar
from gluonts.trainer import Trainer
df = pd.read_csv('deepar_test.csv')
df['monitor_time'] = pd.to_datetime(df['monitor_time'])
df = df.set_index('monitor_time')
data = common.ListDataset([{"start": df.index[0],
"target": df.Measured[:]}],
freq='H')
estimator = deepar.DeepAREstimator( prediction_length=24,
num_parallel_samples=100,
freq="H",
trainer=Trainer(ctx="gpu", epochs=200, learning_rate=1e-3))
predictor = estimator.train(training_data=data, num_workers=2)Error log:
|

|
Hey @k-user, Could you try putting: import multiprocessing
multiprocessing.set_start_method("spawn", force=True)at the beginning of your script? For me, your code works fine using this. Let me know if that resolves your issue. |
Ok,i will try it and report result here.Thanks! |
|
@PascalIversen I tried this method, but it seems to cause another error. This my code: import multiprocessing
multiprocessing.set_start_method("spawn", force=True)
import pandas as pd
from gluonts.dataset import common
from gluonts.model import deepar
from gluonts.trainer import Trainer
df = pd.read_csv('deepar_test.csv')
df['monitor_time'] = pd.to_datetime(df['monitor_time'])
df = df.set_index('monitor_time')
data = common.ListDataset([{"start": df.index[0],
"target": df.monitor_value[:]}],
freq='H')
estimator = deepar.DeepAREstimator( prediction_length=24,
num_parallel_samples=100,
freq="H",
trainer=Trainer(ctx="gpu",
epochs=200,
learning_rate=1e-3))
predictor = estimator.train(training_data=data, num_workers=2)That's part of the mistake: |
|
Thanks for trying this @k-user. Are you on Windows? Could you tell me the output of: import sys
print(sys.platform)GluonTS's multiprocessing is not supported on Windows, but there should have been a warning instead of the error. |
|
@PascalIversen |
|
That is strange, I am also running on linux and I can not reproduce the error. Just to make sure: Are you using the latest version of GluonTS? |
|
@PascalIversen Yes,I'm using the latest gluonts.Can I have a look at the process you are running.Or you look at mine. |
|
@k-user as a side note, maybe unrelated: it seems like you're training a model on a single time series, in which case multiprocessing won't help you, so you might want to turn that off for that specific example. You can check whether that's what causing the problem, by doubling the size of the dataset that you're using: data = common.ListDataset(
[{"start": df.index[0], "target": df.monitor_value[:]}] * 2,
freq='H'
) |
It's helpful.Thanks! But some issue happened: import multiprocessing
multiprocessing.set_start_method("spawn", force=True)When i add this code, Evaluator results in an error: |
|
A quick fix is setting num_workers=0 for the However, I can reproduce this on Python 3.6 and 3.7 using import multiprocessing
multiprocessing.set_start_method("spawn", force=True)
import pandas as pd
from gluonts.dataset import common
from gluonts.model import deepar
from gluonts.mx.trainer import Trainer
from gluonts.dataset.repository.datasets import get_dataset
from gluonts.evaluation import Evaluator
data = get_dataset("m4_hourly").train
estimator = deepar.DeepAREstimator( prediction_length=24,
freq="H",
trainer=Trainer(ctx="gpu",
epochs=1))
predictor = estimator.train(training_data=data, num_workers=None)
from gluonts.evaluation.backtest import make_evaluation_predictions
forecast_it, ts_it = make_evaluation_predictions(
dataset=data, # test dataset
predictor=predictor, # predictor
num_samples=100, # number of sample paths we want for evaluation
)
forecasts = list(forecast_it)
tss = list(ts_it)
evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9], num_workers = 2)
agg_metrics, item_metrics = evaluator(iter(tss), iter(forecasts), num_series=len(data))AssertionError Traceback (most recent call last)
<ipython-input-4-2d8e2921f68f> in <module>
25
26 evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9], num_workers = 2)
---> 27 agg_metrics, item_metrics = evaluator(iter(tss), iter(forecasts), num_series=len(data))
~/anaconda3/envs/mxnet_latest_p37/lib/python3.7/site-packages/gluonts/evaluation/_base.py in __call__(self, ts_iterator, fcst_iterator, num_series)
155 func=_worker_fun,
156 iterable=iter(it),
--> 157 chunksize=self.chunk_size,
158 )
159 mp_pool.close()
~/anaconda3/envs/mxnet_latest_p37/lib/python3.7/multiprocessing/pool.py in map(self, func, iterable, chunksize)
266 in a list that is returned.
267 '''
--> 268 return self._map_async(func, iterable, mapstar, chunksize).get()
269
270 def starmap(self, func, iterable, chunksize=None):
~/anaconda3/envs/mxnet_latest_p37/lib/python3.7/multiprocessing/pool.py in get(self, timeout)
655 return self._value
656 else:
--> 657 raise self._value
658
659 def _set(self, i, obj):
AssertionError: Something went wrong with the worker initialization. |
|
@PascalIversen |
|
Closing this since multiprocessing data loader was removed in #2018 |
Description
In the past, when I used gluon-ts-0.5.0, num_workers>1 could not be set. I saw the code lostella released in #898 the other day and pulled it down for use. Num_workers can be set to greater than 1, but there are some problems.
Problem 1: when epoch reaches about 200, the training will end.
Problem 2: CUDA initialization error occurs when training the next target.
I made a demo to reproduce the problem, and some of the data will be uploaded. Thanks! @lostella
data.zip
To Reproduce
Error message or code output
Environment
3b:00.0 3D controller: NVIDIA Corporation GV100 [Tesla V100 PCIe] (rev a1)
b1:00.0 3D controller: NVIDIA Corporation GV100 [Tesla V100 PCIe] (rev a1)
The text was updated successfully, but these errors were encountered: