Unmatched error code on Linux 6.2 for "connect()" #828
Comments
|
I suspect the same will happen if you change it to sync connect AND set O_NONBLOCK on the clientfd after opening the socket. Can you test? BTW, SQPOLL does not require root in any io_uring kernel you'd want to use. This includes 5.10-stable, 5.15-stable, and anything after those. |
|
OK this does look a bit odd... If you're able to compile and test your own kernels, please try: which does pass your test case. I'll clean that up and add it too. |
|
Here's where I ended up: I'll send it out for review. If you want a Reviewed-by: attribution, I'll need your name and email to add to it. Completely up to you. I already referenced this bug in the commit. |
…ests Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Signed-off-by: Jens Axboe <axboe@kernel.dk>
Check that repeated IORING_OP_CONNECT to a socket without a listener keeps yielding -ECONNREFUSED rather than -ECONNABORTED. Based on a reproducer referenced in the link below, and adopted to our usual test cases. Other changes made like looping, using different ring types, adding a memset() for reuse, etc. Link: #828 Signed-off-by: Jens Axboe <axboe@kernel.dk>
|
And here's the liburing test case: https://git.kernel.dk/cgit/liburing/commit/?id=7389eb1e4192132289e4ee9ccecb5bd00db888e0 |
|
Thank you for your quick response! It's very kind of you to mention me with that attribution. |
…ests Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk>
|
Sounds good, thanks! I've added the reported-by to the commit and pushed out a new one. |
|
Thank you for your help! Additionally, I was wondering if kernel versions 6.0 or 6.1 are expected to pass the test. Would you happen to know when this might be introduced? Our team is in need of a kernel version no lower than 6.0 for deployment, so any insight you have would be greatly appreciated. If not, do you think we can anticipate using version 6.3 instead? Thank you again. |
|
Thank you so much for your prompt work. I've tested the kernel 6.2.1 with the patch you provided, and it works perfectly. Please feel free to close this issue. |
|
Perfect, thanks for testing! And for the report in the first place, with the reproducer. In terms of kernel version, this will go into the 6.3-rc series this week, but will then makes its way into the stable branches as well. So if you based on 6.2-stable, you should be fine. |
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk>
…ests commit 74e2e17 upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org>
…ests BugLink: https://bugs.launchpad.net/bugs/2016877 commit 74e2e17ee1f8d8a0928b90434ad7e2df70f8483e upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org> Signed-off-by: Paolo Pisati <paolo.pisati@canonical.com>
…ests BugLink: https://bugs.launchpad.net/bugs/2016877 commit 74e2e17ee1f8d8a0928b90434ad7e2df70f8483e upstream. Since io_uring does nonblocking connect requests, if we do two repeated ones without having a listener, the second will get -ECONNABORTED rather than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry condition if we're nonblocking, if we haven't already seen it. Cc: stable@vger.kernel.org Fixes: 3fb1bd6 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT") Link: axboe/liburing#828 Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com> Signed-off-by: Jens Axboe <axboe@kernel.dk> Signed-off-by: Greg Kroah-Hartman <gregkh@linuxfoundation.org> Signed-off-by: Paolo Pisati <paolo.pisati@canonical.com>
* Merge tag 'ext4_for_linus_urgent' of git://git.kernel.org/pub/scm/linux/kernel/git/tytso/ext4
Pull ext4 fix from Ted Ts'o:
"Fix a double unlock bug on an error path in ext4, found by smatch and
syzkaller"
* tag 'ext4_for_linus_urgent' of git://git.kernel.org/pub/scm/linux/kernel/git/tytso/ext4:
ext4: fix possible double unlock when moving a directory
* Merge tag 'x86_urgent_for_v6.3_rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip
Pull x86 fixes from Borislav Petkov:
"There's a little bit more 'movement' in there for my taste but it
needs to happen and should make the code better after it.
- Check cmdline_find_option()'s return value before further
processing
- Clear temporary storage in the resctrl code to prevent access to an
unexistent MSR
- Add a simple throttling mechanism to protect the hypervisor from
potentially malicious SEV guests issuing requests in rapid
succession.
In order to not jeopardize the sanity of everyone involved in
maintaining this code, the request issuing side has received a
cleanup, split in more or less trivial, small and digestible
pieces. Otherwise, the code was threatening to become an
unmaintainable mess.
Therefore, that cleanup is marked indirectly also for stable so
that there's no differences between the upstream code and the
stable variant when it comes down to backporting more there"
* tag 'x86_urgent_for_v6.3_rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/mm: Fix use of uninitialized buffer in sme_enable()
x86/resctrl: Clear staged_config[] before and after it is used
virt/coco/sev-guest: Add throttling awareness
virt/coco/sev-guest: Convert the sw_exit_info_2 checking to a switch-case
virt/coco/sev-guest: Do some code style cleanups
virt/coco/sev-guest: Carve out the request issuing logic into a helper
virt/coco/sev-guest: Remove the disable_vmpck label in handle_guest_request()
virt/coco/sev-guest: Simplify extended guest request handling
virt/coco/sev-guest: Check SEV_SNP attribute at probe time
* Merge tag 'perf_urgent_for_v6.3_rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip
Pull perf fixes from Borislav Petkov:
- Check whether sibling events have been deactivated before adding them
to groups
- Update the proper event time tracking variable depending on the event
type
- Fix a memory overwrite issue due to using the wrong function argument
when outputting perf events
* tag 'perf_urgent_for_v6.3_rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
perf: Fix check before add_event_to_groups() in perf_group_detach()
perf: fix perf_event_context->time
perf/core: Fix perf_output_begin parameter is incorrectly invoked in perf_event_bpf_output
* xfs: walk all AGs if TRYLOCK passed to xfs_alloc_vextent_iterate_ags
Callers of xfs_alloc_vextent_iterate_ags that pass in the TRYLOCK flag
want us to perform a non-blocking scan of the AGs for free space. There
are no ordering constraints for non-blocking AGF lock acquisition, so
the scan can freely start over at AG 0 even when minimum_agno > 0.
This manifests fairly reliably on xfs/294 on 6.3-rc2 with the parent
pointer patchset applied and the realtime volume enabled. I observed
the following sequence as part of an xfs_dir_createname call:
0. Fragment the free space, then allocate nearly all the free space in
all AGs except AG 0.
1. Create a directory in AG 2 and let it grow for a while.
2. Try to allocate 2 blocks to expand the dirent part of a directory.
The space will be allocated out of AG 0, but the allocation will not
be contiguous. This (I think) activates the LOWMODE allocator.
3. The bmapi call decides to convert from extents to bmbt format and
tries to allocate 1 block. This allocation request calls
xfs_alloc_vextent_start_ag with the inode number, which starts the
scan at AG 2. We ignore AG 0 (with all its free space) and instead
scrape AG 2 and 3 for more space. We find one block, but this now
kicks t_highest_agno to 3.
4. The createname call decides it needs to split the dabtree. It tries
to allocate even more space with xfs_alloc_vextent_start_ag, but now
we're constrained to AG 3, and we don't find the space. The
createname returns ENOSPC and the filesystem shuts down.
This change fixes the problem by making the trylock scan wrap around to
AG 0 if it doesn't like the AGs that it finds. Since the current
transaction itself holds AGF 0, the trylock of AGF 0 will succeed, and
we take space from the AG that has plenty.
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
Reviewed-by: Dave Chinner <dchinner@redhat.com>
* xfs: add tracepoints for each of the externally visible allocators
There are now five separate space allocator interfaces exposed to the
rest of XFS for five different strategies to find space. Add
tracepoints for each of them so that I can tell from a trace dump
exactly which ones got called and what happened underneath them. Add a
sixth so it's more obvious if an allocation actually happened.
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
Reviewed-by: Dave Chinner <dchinner@redhat.com>
* xfs: test dir/attr hash when loading module
Back in the 6.2-rc1 days, Eric Whitney reported a fstests regression in
ext4 against generic/454. The cause of this test failure was the
unfortunate combination of setting an xattr name containing UTF8 encoded
emoji, an xattr hash function that accepted a char pointer with no
explicit signedness, signed type extension of those chars to an int, and
the 6.2 build tools maintainers deciding to mandate -funsigned-char
across the board. As a result, the ondisk extended attribute structure
written out by 6.1 and 6.2 were not the same.
This discrepancy, in fact, had been noticeable if a filesystem with such
an xattr were moved between any two architectures that don't employ the
same signedness of a raw "char" declaration. The only reason anyone
noticed is that x86 gcc defaults to signed, and no such -funsigned-char
update was made to e2fsprogs, so e2fsck immediately started reporting
data corruption.
After a day and a half of discussing how to handle this use case (xattrs
with bit 7 set anywhere in the name) without breaking existing users,
Linus merged his own patch and didn't tell the maintainer. None of the
ext4 developers realized this until AUTOSEL announced that the commit
had been backported to stable.
In the end, this problem could have been detected much earlier if there
had been any useful tests of hash function(s) in use inside ext4 to make
sure that they always produce the same outputs given the same inputs.
The XFS dirent/xattr name hash takes a uint8_t*, so I don't think it's
vulnerable to this problem. However, let's avoid all this drama by
adding our own self test to check that the da hash produces the same
outputs for a static pile of inputs on various platforms. This enables
us to fix any breakage that may result in a controlled fashion. The
buffer and test data are identical to the patches submitted to xfsprogs.
Link: https://lore.kernel.org/linux-ext4/Y8bpkm3jA3bDm3eL@debian-BULLSEYE-live-builder-AMD64/
Link: https://lore.kernel.org/linux-xfs/ZBUKCRR7xvIqPrpX@destitution/T/#md38272cc684e2c0d61494435ccbb91f022e8dee4
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
Reviewed-by: Dave Chinner <dchinner@redhat.com>
* Merge tag 'ras_urgent_for_v6.3_rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip
Pull RAS fix from Borislav Petkov:
- Flush out logged errors immediately after MCA banks configuration
changes over sysfs have been done instead of waiting until something
else triggers the workqueue later - another error or the polling
interval cycle is reached
* tag 'ras_urgent_for_v6.3_rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/tip/tip:
x86/mce: Make sure logged MCEs are processed after sysfs update
* cpumask: introduce for_each_cpu_or
Equivalent of for_each_cpu_and, except it ORs the two masks together
so it iterates all the CPUs present in either mask.
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Darrick J. Wong <djwong@kernel.org>
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
* pcpcntrs: fix dying cpu summation race
In commit f689054aace2 ("percpu_counter: add percpu_counter_sum_all
interface") a race condition between a cpu dying and
percpu_counter_sum() iterating online CPUs was identified. The
solution was to iterate all possible CPUs for summation via
percpu_counter_sum_all().
We recently had a percpu_counter_sum() call in XFS trip over this
same race condition and it fired a debug assert because the
filesystem was unmounting and the counter *should* be zero just
before we destroy it. That was reported here:
https://lore.kernel.org/linux-kernel/20230314090649.326642-1-yebin@huaweicloud.com/
likely as a result of running generic/648 which exercises
filesystems in the presence of CPU online/offline events.
The solution to use percpu_counter_sum_all() is an awful one. We
use percpu counters and percpu_counter_sum() for accurate and
reliable threshold detection for space management, so a summation
race condition during these operations can result in overcommit of
available space and that may result in filesystem shutdowns.
As percpu_counter_sum_all() iterates all possible CPUs rather than
just those online or even those present, the mask can include CPUs
that aren't even installed in the machine, or in the case of
machines that can hot-plug CPU capable nodes, even have physical
sockets present in the machine.
Fundamentally, this race condition is caused by the CPU being
offlined being removed from the cpu_online_mask before the notifier
that cleans up per-cpu state is run. Hence percpu_counter_sum() will
not sum the count for a cpu currently being taken offline,
regardless of whether the notifier has run or not. This is
the root cause of the bug.
The percpu counter notifier iterates all the registered counters,
locks the counter and moves the percpu count to the global sum.
This is serialised against other operations that move the percpu
counter to the global sum as well as percpu_counter_sum() operations
that sum the percpu counts while holding the counter lock.
Hence the notifier is safe to run concurrently with sum operations,
and the only thing we actually need to care about is that
percpu_counter_sum() iterates dying CPUs. That's trivial to do,
and when there are no CPUs dying, it has no addition overhead except
for a cpumask_or() operation.
This change makes percpu_counter_sum() always do the right thing in
the presence of CPU hot unplug events and makes
percpu_counter_sum_all() unnecessary. This, in turn, means that
filesystems like XFS, ext4, and btrfs don't have to work out when
they should use percpu_counter_sum() vs percpu_counter_sum_all() in
their space accounting algorithms
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Darrick J. Wong <djwong@kernel.org>
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
* fork: remove use of percpu_counter_sum_all
This effectively reverts the change made in commit f689054aace2
("percpu_counter: add percpu_counter_sum_all interface") as the
race condition percpu_counter_sum_all() was invented to avoid is
now handled directly in percpu_counter_sum() and nobody needs to
care about summing racing with cpu unplug anymore.
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Darrick J. Wong <djwong@kernel.org>
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
* pcpcntr: remove percpu_counter_sum_all()
percpu_counter_sum_all() is now redundant as the race condition it
was invented to handle is now dealt with by percpu_counter_sum()
directly and all users of percpu_counter_sum_all() have been
removed.
Remove it.
This effectively reverts the changes made in f689054aace2
("percpu_counter: add percpu_counter_sum_all interface") except for
the cpumask iteration that fixes percpu_counter_sum() made earlier
in this series.
Signed-off-by: Dave Chinner <dchinner@redhat.com>
Reviewed-by: Darrick J. Wong <djwong@kernel.org>
Signed-off-by: Darrick J. Wong <djwong@kernel.org>
* Merge tag 'char-misc-6.3-rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/char-misc
Pull char/misc driver fixes from Greg KH:
"Here are a few small char/misc/other driver subsystem patches to
resolve reported problems for 6.3-rc3.
Included in here are:
- Interconnect driver fixes for reported problems
- Memory driver fixes for reported problems
- nvmem core fix
- firmware driver fix for reported problem
All of these have been in linux-next for a while with no reported
issues"
* tag 'char-misc-6.3-rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/char-misc: (23 commits)
memory: tegra30-emc: fix interconnect registration race
memory: tegra20-emc: fix interconnect registration race
memory: tegra124-emc: fix interconnect registration race
memory: tegra: fix interconnect registration race
interconnect: exynos: drop redundant link destroy
interconnect: exynos: fix registration race
interconnect: exynos: fix node leak in probe PM QoS error path
interconnect: qcom: msm8974: fix registration race
interconnect: qcom: rpmh: fix registration race
interconnect: qcom: rpmh: fix probe child-node error handling
interconnect: qcom: rpm: fix registration race
nvmem: core: return -ENOENT if nvmem cell is not found
firmware: xilinx: don't make a sleepable memory allocation from an atomic context
interconnect: qcom: rpm: fix probe child-node error handling
interconnect: qcom: osm-l3: fix registration race
interconnect: imx: fix registration race
interconnect: fix provider registration API
interconnect: fix icc_provider_del() error handling
interconnect: fix mem leak when freeing nodes
interconnect: qcom: qcm2290: Fix MASTER_SNOC_BIMC_NRT
...
* Merge tag 'tty-6.3-rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/tty
Pull tty/serial driver fixes from Greg KH:
"Here are some small tty and serial driver fixes for 6.3-rc3 to resolve
some reported issues.
They include:
- 8250 driver Kconfig issue pointed out by you that showed up in -rc1
- qcom-geni serial driver fixes
- various 8250 driver fixes for reported problems
- fsl_lpuart driver fixes
- serdev fix for regression in -rc1
- vt.c bugfix
All have been in linux-next for over a week with no reported problems"
* tag 'tty-6.3-rc3' of git://git.kernel.org/pub/scm/linux/kernel/git/gregkh/tty:
tty: vt: protect KD_FONT_OP_GET_TALL from unbound access
serial: qcom-geni: drop bogus uart_write_wakeup()
serial: qcom-geni: fix mapping of empty DMA buffer
serial: qcom-geni: fix DMA mapping leak on shutdown
serial: qcom-geni: fix console shutdown hang
serdev: Set fwnode for serdev devices
tty: serial: fsl_lpuart: fix race on RX DMA shutdown
serial: 8250_pci1xxxx: Disable SERIAL_8250_PCI1XXXX config by default
serial: 8250_fsl: fix handle_irq locking
serial: 8250_em: Fix UART port type
serial: 8250: ASPEED_VUART: select REGMAP instead of depending on it
tty: serial: fsl_lpuart: skip waiting for transmission complete when UARTCTRL_SBK is asserted
Revert "tty: serial: fsl_lpuart: adjust SERIAL_FSL_LPUART_CONSOLE config dependency"
* tracing: Make splice_read available again
Since the commit 36e2c7421f02 ("fs: don't allow splice read/write
without explicit ops") is applied to the kernel, splice() and
sendfile() calls on the trace file (/sys/kernel/debug/tracing
/trace) return EINVAL.
This patch restores these system calls by initializing splice_read
in file_operations of the trace file. This patch only enables such
functionalities for the read case.
Link: https://lore.kernel.org/linux-trace-kernel/20230314013707.28814-1-sfoon.kim@samsung.com
Cc: stable@vger.kernel.org
Fixes: 36e2c7421f02 ("fs: don't allow splice read/write without explicit ops")
Signed-off-by: Sung-hun Kim <sfoon.kim@samsung.com>
Signed-off-by: Steven Rostedt (Google) <rostedt@goodmis.org>
* ring-buffer: remove obsolete comment for free_buffer_page()
The comment refers to mm/slob.c which is being removed. It comes from
commit ed56829cb319 ("ring_buffer: reset buffer page when freeing") and
according to Steven the borrowed code was a page mapcount and mapping
reset, which was later removed by commit e4c2ce82ca27 ("ring_buffer:
allocate buffer page pointer"). Thus the comment is not accurate anyway,
remove it.
Link: https://lore.kernel.org/linux-trace-kernel/20230315142446.27040-1-vbabka@suse.cz
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Cc: Ingo Molnar <mingo@elte.hu>
Reported-by: Mike Rapoport <mike.rapoport@gmail.com>
Suggested-by: Steven Rostedt (Google) <rostedt@goodmis.org>
Fixes: e4c2ce82ca27 ("ring_buffer: allocate buffer page pointer")
Signed-off-by: Vlastimil Babka <vbabka@suse.cz>
Reviewed-by: Mukesh Ojha <quic_mojha@quicinc.com>
Signed-off-by: Steven Rostedt (Google) <rostedt@goodmis.org>
* tracing/hwlat: Replace sched_setaffinity with set_cpus_allowed_ptr
There is a problem with the behavior of hwlat in a container,
resulting in incorrect output. A warning message is generated:
"cpumask changed while in round-robin mode, switching to mode none",
and the tracing_cpumask is ignored. This issue arises because
the kernel thread, hwlatd, is not a part of the container, and
the function sched_setaffinity is unable to locate it using its PID.
Additionally, the task_struct of hwlatd is already known.
Ultimately, the function set_cpus_allowed_ptr achieves
the same outcome as sched_setaffinity, but employs task_struct
instead of PID.
Test case:
# cd /sys/kernel/tracing
# echo 0 > tracing_on
# echo round-robin > hwlat_detector/mode
# echo hwlat > current_tracer
# unshare --fork --pid bash -c 'echo 1 > tracing_on'
# dmesg -c
Actual behavior:
[573502.809060] hwlat_detector: cpumask changed while in round-robin mode, switching to mode none
Link: https://lore.kernel.org/linux-trace-kernel/20230316144535.1004952-1-costa.shul@redhat.com
Cc: Masami Hiramatsu <mhiramat@kernel.org>
Fixes: 0330f7aa8ee63 ("tracing: Have hwlat trace migrate across tracing_cpumask CPUs")
Signed-off-by: Costa Shulyupin <costa.shul@redhat.com>
Acked-by: Daniel Bristot de Oliveira <bristot@kernel.org>
Signed-off-by: Steven Rostedt (Google) <rostedt@goodmis.org>
* Merge tag 'trace-v6.3-rc2' of git://git.kernel.org/pub/scm/linux/kernel/git/trace/linux-trace
Pull tracing fixes from Steven Rostedt:
- Fix setting affinity of hwlat threads in containers
Using sched_set_affinity() has unwanted side effects when being
called within a container. Use set_cpus_allowed_ptr() instead
- Fix per cpu thread management of the hwlat tracer:
- Do not start per_cpu threads if one is already running for the CPU
- When starting per_cpu threads, do not clear the kthread variable
as it may already be set to running per cpu threads
- Fix return value for test_gen_kprobe_cmd()
On error the return value was overwritten by being set to the result
of the call from kprobe_event_delete(), which would likely succeed,
and thus have the function return success
- Fix splice() reads from the trace file that was broken by commit
36e2c7421f02 ("fs: don't allow splice read/write without explicit
ops")
- Remove obsolete and confusing comment in ring_buffer.c
The original design of the ring buffer used struct page flags for
tricks to optimize, which was shortly removed due to them being
tricks. But a comment for those tricks remained
- Set local functions and variables to static
* tag 'trace-v6.3-rc2' of git://git.kernel.org/pub/scm/linux/kernel/git/trace/linux-trace:
tracing/hwlat: Replace sched_setaffinity with set_cpus_allowed_ptr
ring-buffer: remove obsolete comment for free_buffer_page()
tracing: Make splice_read available again
ftrace: Set direct_ops storage-class-specifier to static
trace/hwlat: Do not start per-cpu thread if it is already running
trace/hwlat: Do not wipe the contents of per-cpu thread data
tracing/osnoise: set several trace_osnoise.c variables storage-class-specifier to static
tracing: Fix wrong return in kprobe_event_gen_test.c
* Linux 6.3-rc3
* thunderbolt: Use const qualifier for `ring_interrupt_index`
`ring_interrupt_index` doesn't change the data for `ring` so mark it as
const. This is needed by the following patch that disables interrupt
auto clear for rings.
Cc: Sanju Mehta <Sanju.Mehta@amd.com>
Cc: stable@vger.kernel.org
Signed-off-by: Mario Limonciello <mario.limonciello@amd.com>
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
* thunderbolt: Disable interrupt auto clear for rings
When interrupt auto clear is programmed, any read to the interrupt
status register will clear all interrupts. If two interrupts have
come in before one can be serviced then this will cause lost interrupts.
On AMD USB4 routers this has manifested in odd problems particularly
with long strings of control tranfers such as reading the DROM via bit
banging.
Instead of clearing interrupts automatically, clear the bit corresponding
to the given ring's interrupt in the ISR.
Fixes: 7a1808f82a37 ("thunderbolt: Handle ring interrupt by reading interrupt status register")
Cc: Sanju Mehta <Sanju.Mehta@amd.com>
Cc: stable@vger.kernel.org
Tested-by: Anson Tsao <anson.tsao@amd.com>
Signed-off-by: Mario Limonciello <mario.limonciello@amd.com>
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
* drm/i915/mtl: Fix Wa_16015201720 implementation
The commit 2357f2b271ad ("drm/i915/mtl: Initial display workarounds")
extended the workaround Wa_16015201720 to MTL. However the registers
that the original WA implemented moved for MTL.
Implement the workaround with the correct register.
v3: Skip clock gating for pipe C, D DMC's and fix the title
Fixes: 2357f2b271ad ("drm/i915/mtl: Initial display workarounds")
Cc: Matt Atwood <matthew.s.atwood@intel.com>
Cc: Lucas De Marchi <lucas.demarchi@intel.com>
Signed-off-by: Radhakrishna Sripada <radhakrishna.sripada@intel.com>
Reviewed-by: Matt Roper <matthew.d.roper@intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230301201053.928709-2-radhakrishna.sripada@intel.com
(cherry picked from commit 0188be507b973e36f637ba010a369057c8cb7282)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915/fbdev: lock the fbdev obj before vma pin
lock the fbdev obj before calling into
i915_vma_pin_iomap(). This helps to solve below :
<7>[ 93.563308] i915 0000:00:02.0: [drm:intelfb_create [i915]] no BIOS fb, allocating a new one
<4>[ 93.581844] ------------[ cut here ]------------
<4>[ 93.581855] WARNING: CPU: 12 PID: 625 at drivers/gpu/drm/i915/gem/i915_gem_pages.c:424 i915_gem_object_pin_map+0x152/0x1c0 [i915]
Fixes: f0b6b01b3efe ("drm/i915: Add ww context to intel_dpt_pin, v2.")
Cc: Chris Wilson <chris.p.wilson@intel.com>
Cc: Matthew Auld <matthew.auld@intel.com>
Cc: Maarten Lankhorst <maarten.lankhorst@linux.intel.com>
Signed-off-by: Tejas Upadhyay <tejas.upadhyay@intel.com>
Signed-off-by: Radhakrishna Sripada <radhakrishna.sripada@intel.com>
Reviewed-by: Andi Shyti <andi.shyti@linux.intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230301201053.928709-5-radhakrishna.sripada@intel.com
(cherry picked from commit 561b31acfd65502a2cda2067513240fc57ccdbdc)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915: Preserve crtc_state->inherited during state clearing
intel_crtc_prepare_cleared_state() is unintentionally losing
the "inherited" flag. This will happen if intel_initial_commit()
is forced to go through the full modeset calculations for
whatever reason.
Afterwards the first real commit from userspace will not get
forced to the full modeset path, and thus eg. audio state may
not get recomputed properly. So if the monitor was already
enabled during boot audio will not work until userspace itself
does an explicit full modeset.
Cc: stable@vger.kernel.org
Tested-by: Lee Shawn C <shawn.c.lee@intel.com>
Signed-off-by: Ville Syrjälä <ville.syrjala@linux.intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230223152048.20878-1-ville.syrjala@linux.intel.com
Reviewed-by: Uma Shankar <uma.shankar@intel.com>
(cherry picked from commit 2553bacaf953b48c59357f5a622282bc0c45adae)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915/mtl: Disable MC6 for MTL A step
The Wa_14017073508 require to send Media Busy/Idle mailbox while
accessing Media tile. As of now it is getting handled while __gt_unpark,
__gt_park. But there are various corner cases where forcewakes are taken
without __gt_unpark i.e. without sending Busy Mailbox especially during
register reads. Forcewakes are taken without busy mailbox leads to
GPU HANG. So bringing mailbox calls under forcewake calls are no feasible
option as forcewake calls are atomic and mailbox calls are blocking.
The issue already fixed in B step so disabling MC6 on A step and
reverting previous commit which handles Wa_14017073508
Fixes: 8f70f1ec587d ("drm/i915/mtl: Add Wa_14017073508 for SAMedia")
Cc: Rodrigo Vivi <rodrigo.vivi@intel.com>
Signed-off-by: Badal Nilawar <badal.nilawar@intel.com>
Reviewed-by: Rodrigo Vivi <rodrigo.vivi@intel.com>
Signed-off-by: Anshuman Gupta <anshuman.gupta@intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230310061339.2495416-2-badal.nilawar@intel.com
(cherry picked from commit 038a24835ab68f341eaa7a0e3bcc6ce0f9b22e17)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915/guc: Fix missing ecodes
Error captures are tagged with an 'ecode'. This is a pseduo-unique magic
number that is meant to distinguish similar seeming bugs with
different underlying signatures. It is a combination of two ring state
registers. Unfortunately, the register state being used is only valid
in execlist mode. In GuC mode, the register state exists in a separate
list of arbitrary register address/value pairs rather than the named
entry structure. So, search through that list to find the two exciting
registers and copy them over to the structure's named members.
v2: if else if instead of if if (Alan)
Signed-off-by: John Harrison <John.C.Harrison@Intel.com>
Reviewed-by: Alan Previn <alan.previn.teres.alexis@intel.com>
Fixes: a6f0f9cf330a ("drm/i915/guc: Plumb GuC-capture into gpu_coredump")
Cc: Alan Previn <alan.previn.teres.alexis@intel.com>
Cc: Umesh Nerlige Ramappa <umesh.nerlige.ramappa@intel.com>
Cc: Lucas De Marchi <lucas.demarchi@intel.com>
Cc: Jani Nikula <jani.nikula@linux.intel.com>
Cc: Joonas Lahtinen <joonas.lahtinen@linux.intel.com>
Cc: Rodrigo Vivi <rodrigo.vivi@intel.com>
Cc: Tvrtko Ursulin <tvrtko.ursulin@linux.intel.com>
Cc: Matt Roper <matthew.d.roper@intel.com>
Cc: Aravind Iddamsetty <aravind.iddamsetty@intel.com>
Cc: Michael Cheng <michael.cheng@intel.com>
Cc: Matthew Brost <matthew.brost@intel.com>
Cc: Bruce Chang <yu.bruce.chang@intel.com>
Cc: Daniele Ceraolo Spurio <daniele.ceraolospurio@intel.com>
Cc: Matthew Auld <matthew.auld@intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230311063714.570389-2-John.C.Harrison@Intel.com
(cherry picked from commit 9724ecdbb9ddd6da3260e4a442574b90fc75188a)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915/active: Fix missing debug object activation
debug_active_activate() expected ref->count to be zero
which is not true anymore as __i915_active_activate() calls
debug_active_activate() after incrementing the count.
v2: No need to check for "ref->count == 1" as __i915_active_activate()
already make sure of that(Janusz).
References: https://gitlab.freedesktop.org/drm/intel/-/issues/6733
Fixes: 04240e30ed06 ("drm/i915: Skip taking acquire mutex for no ref->active callback")
Cc: Chris Wilson <chris@chris-wilson.co.uk>
Cc: Tvrtko Ursulin <tvrtko.ursulin@intel.com>
Cc: Thomas Hellström <thomas.hellstrom@intel.com>
Cc: Andi Shyti <andi.shyti@linux.intel.com>
Cc: intel-gfx@lists.freedesktop.org
Cc: Janusz Krzysztofik <janusz.krzysztofik@linux.intel.com>
Cc: <stable@vger.kernel.org> # v5.10+
Signed-off-by: Nirmoy Das <nirmoy.das@intel.com>
Reviewed-by: Janusz Krzysztofik <janusz.krzysztofik@linux.intel.com>
Reviewed-by: Andrzej Hajda <andrzej.hajda@intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230313114613.9874-1-nirmoy.das@intel.com
(cherry picked from commit bfad380c542438a9b642f8190b7fd37bc77e2723)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915/gt: perform uc late init after probe error injection
Probe pseudo errors should be injected only in places where real errors
can be encountered, otherwise unwinding code can be broken.
Placing intel_uc_init_late before i915_inject_probe_error violated
this rule, resulting in following bug:
__intel_gt_disable:655 GEM_BUG_ON(intel_gt_pm_is_awake(gt))
Fixes: 481d458caede ("drm/i915/guc: Add golden context to GuC ADS")
Acked-by: Nirmoy Das <nirmoy.das@intel.com>
Reviewed-by: Andi Shyti <andi.shyti@linux.intel.com>
Signed-off-by: Andrzej Hajda <andrzej.hajda@intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230314151920.1065847-1-andrzej.hajda@intel.com
(cherry picked from commit c4252a11131c7f27a158294241466e2a4e7ff94e)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915: Fix format for perf_limit_reasons
Use hex format so that it is easier to decode.
Fixes: fe5979665f64 ("drm/i915/debugfs: Add perf_limit_reasons in debugfs")
Signed-off-by: Vinay Belgaumkar <vinay.belgaumkar@intel.com>
Reviewed-by: Ashutosh Dixit <ashutosh.dixit@intel.com>
Signed-off-by: John Harrison <John.C.Harrison@Intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230315022906.2467408-1-vinay.belgaumkar@intel.com
(cherry picked from commit 5e008ba67cb80084e99b40ccd46f9029ae421632)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* drm/i915: Update vblank timestamping stuff on seamless M/N change
When we change the M/N values seamlessly during a fastset we should
also update the vblank timestamping stuff to make sure the vblank
timestamp corrections/guesstimations come out exact.
Note that only crtc_clock and framedur_ns can actually end up
changing here during fastsets. Everything else we touch can
only change during full modesets.
Technically we should try to do this exactly at the start of
vblank, but that would require some kind of double buffering
scheme. Let's skip that for now and just update things right
after the commit has been submitted to the hardware. This
means the information will be properly up to date when the
vblank irq handler goes to work. Only if someone ends up
querying some vblanky stuff in between the commit and start
of vblank may we see a slight discrepancy.
Also this same problem really exists for the DRRS downclocking
stuff. But as that is supposed to be more or less transparent
to the user, and it only drops to low gear after a long delay
(1 sec currently) we probably don't have to worry about it.
Any time something is actively submitting updates DRRS will
remain in high gear and so the timestamping constants will
match the hardware state.
Reviewed-by: Jani Nikula <jani.nikula@intel.com>
Reviewed-by: Mitul Golani <mitulkumar.ajitkumar.golani@intel.com>
Fixes: e6f29923c048 ("drm/i915: Allow M/N change during fastset on bdw+")
Signed-off-by: Ville Syrjälä <ville.syrjala@linux.intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230310235828.17439-1-ville.syrjala@linux.intel.com
(cherry picked from commit 8cb1f95cca68421b08333175719fdd3615372ca8)
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
* net: dsa: report rx_bytes unadjusted for ETH_HLEN
We collect the software statistics counters for RX bytes (reported to
/proc/net/dev and to ethtool -S $dev | grep 'rx_bytes: ") at a time when
skb->len has already been adjusted by the eth_type_trans() ->
skb_pull_inline(skb, ETH_HLEN) call to exclude the L2 header.
This means that when connecting 2 DSA interfaces back to back and
sending 1 packet with length 100, the sending interface will report
tx_bytes as incrementing by 100, and the receiving interface will report
rx_bytes as incrementing by 86.
Since accounting for that in scripts is quirky and is something that
would be DSA-specific behavior (requiring users to know that they are
running on a DSA interface in the first place), the proposal is that we
treat it as a bug and fix it.
This design bug has always existed in DSA, according to my analysis:
commit 91da11f870f0 ("net: Distributed Switch Architecture protocol
support") also updates skb->dev->stats.rx_bytes += skb->len after the
eth_type_trans() call. Technically, prior to Florian's commit
a86d8becc3f0 ("net: dsa: Factor bottom tag receive functions"), each and
every vendor-specific tagging protocol driver open-coded the same bug,
until the buggy code was consolidated into something resembling what can
be seen now. So each and every driver should have its own Fixes: tag,
because of their different histories until the convergence point.
I'm not going to do that, for the sake of simplicity, but just blame the
oldest appearance of buggy code.
There are 2 ways to fix the problem. One is the obvious way, and the
other is how I ended up doing it. Obvious would have been to move
dev_sw_netstats_rx_add() one line above eth_type_trans(), and below
skb_push(skb, ETH_HLEN). But DSA processing is not as simple as that.
We count the bytes after removing everything DSA-related from the
packet, to emulate what the packet's length was, on the wire, when the
user port received it.
When eth_type_trans() executes, dsa_untag_bridge_pvid() has not run yet,
so in case the switch driver requests this behavior - commit
412a1526d067 ("net: dsa: untag the bridge pvid from rx skbs") has the
details - the obvious variant of the fix wouldn't have worked, because
the positioning there would have also counted the not-yet-stripped VLAN
header length, something which is absent from the packet as seen on the
wire (there it may be untagged, whereas software will see it as
PVID-tagged).
Fixes: f613ed665bb3 ("net: dsa: Add support for 64-bit statistics")
Signed-off-by: Vladimir Oltean <vladimir.oltean@nxp.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
* net: qcom/emac: Fix use after free bug in emac_remove due to race condition
In emac_probe, &adpt->work_thread is bound with
emac_work_thread. Then it will be started by timeout
handler emac_tx_timeout or a IRQ handler emac_isr.
If we remove the driver which will call emac_remove
to make cleanup, there may be a unfinished work.
The possible sequence is as follows:
Fix it by finishing the work before cleanup in the emac_remove
and disable timeout response.
CPU0 CPU1
|emac_work_thread
emac_remove |
free_netdev |
kfree(netdev); |
|emac_reinit_locked
|emac_mac_down
|//use netdev
Fixes: b9b17debc69d ("net: emac: emac gigabit ethernet controller driver")
Signed-off-by: Zheng Wang <zyytlz.wz@163.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
* net: usb: lan78xx: Limit packet length to skb->len
Packet length retrieved from descriptor may be larger than
the actual socket buffer length. In such case the cloned
skb passed up the network stack will leak kernel memory contents.
Additionally prevent integer underflow when size is less than
ETH_FCS_LEN.
Fixes: 55d7de9de6c3 ("Microchip's LAN7800 family USB 2/3 to 10/100/1000 Ethernet device driver")
Signed-off-by: Szymon Heidrich <szymon.heidrich@gmail.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
* usb: plusb: remove unused pl_clear_QuickLink_features function
clang with W=1 reports
drivers/net/usb/plusb.c:65:1: error:
unused function 'pl_clear_QuickLink_features' [-Werror,-Wunused-function]
pl_clear_QuickLink_features(struct usbnet *dev, int val)
^
This static function is not used, so remove it.
Signed-off-by: Tom Rix <trix@redhat.com>
Signed-off-by: David S. Miller <davem@davemloft.net>
* net/ps3_gelic_net: Fix RX sk_buff length
The Gelic Ethernet device needs to have the RX sk_buffs aligned to
GELIC_NET_RXBUF_ALIGN, and also the length of the RX sk_buffs must
be a multiple of GELIC_NET_RXBUF_ALIGN.
The current Gelic Ethernet driver was not allocating sk_buffs large
enough to allow for this alignment.
Also, correct the maximum and minimum MTU sizes, and add a new
preprocessor macro for the maximum frame size, GELIC_NET_MAX_FRAME.
Fixes various randomly occurring runtime network errors.
Fixes: 02c1889166b4 ("ps3: gigabit ethernet driver for PS3, take3")
Signed-off-by: Geoff Levand <geoff@infradead.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
* net/ps3_gelic_net: Use dma_mapping_error
The current Gelic Etherenet driver was checking the return value of its
dma_map_single call, and not using the dma_mapping_error() routine.
Fixes runtime problems like these:
DMA-API: ps3_gelic_driver sb_05: device driver failed to check map error
WARNING: CPU: 0 PID: 0 at kernel/dma/debug.c:1027 .check_unmap+0x888/0x8dc
Fixes: 02c1889166b4 ("ps3: gigabit ethernet driver for PS3, take3")
Reviewed-by: Alexander Duyck <alexanderduyck@fb.com>
Signed-off-by: Geoff Levand <geoff@infradead.org>
Signed-off-by: David S. Miller <davem@davemloft.net>
* Merge branch 'ps3_gelic_net-fixes'
Geoff Levand says:
====================
net/ps3_gelic_net: DMA related fixes
v9: Make rx_skb_size local to gelic_descr_prepare_rx.
v8: Add more cpu_to_be32 calls.
v7: Remove all cleanups, sync to spider net.
v6: Reworked and cleaned up patches.
v5: Some additional patch cleanups.
v4: More patch cleanups.
v3: Cleaned up patches as requested.
====================
Signed-off-by: David S. Miller <davem@davemloft.net>
* Revert "drm/i915/hwmon: Enable PL1 power limit"
This reverts commit ee892ea83d99610fa33bea612de058e0955eec3a.
It was accidentally picked up for backporting. Revert.
Cc: Jani Nikula <jani.nikula@linux.intel.com>
Cc: Rodrigo Vivi <rodrigo.vivi@intel.com>
Signed-off-by: Ashutosh Dixit <ashutosh.dixit@intel.com>
Signed-off-by: Jani Nikula <jani.nikula@intel.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230319140300.2892032-1-ashutosh.dixit@intel.com
* thunderbolt: Rename shadowed variables bit to interrupt_bit and auto_clear_bit
cppcheck reports
drivers/thunderbolt/nhi.c:74:7: style: Local variable 'bit' shadows outer variable [shadowVariable]
int bit;
^
drivers/thunderbolt/nhi.c:66:6: note: Shadowed declaration
int bit = ring_interrupt_index(ring) & 31;
^
drivers/thunderbolt/nhi.c:74:7: note: Shadow variable
int bit;
^
For readablity rename the outer to interrupt_bit and the innner
to auto_clear_bit.
Fixes: 468c49f44759 ("thunderbolt: Disable interrupt auto clear for ring")
Cc: stable@vger.kernel.org
Signed-off-by: Tom Rix <trix@redhat.com>
Signed-off-by: Mika Westerberg <mika.westerberg@linux.intel.com>
* Merge tag 'nfs-for-6.3-2' of git://git.linux-nfs.org/projects/anna/linux-nfs
Pull NFS client fixes from Anna Schumaker:
- Fix /proc/PID/io read_bytes accounting
- Fix setting NLM file_lock start and end during decoding testargs
- Fix timing for setting access cache timestamps
* tag 'nfs-for-6.3-2' of git://git.linux-nfs.org/projects/anna/linux-nfs:
NFS: Correct timing for assigning access cache timestamp
lockd: set file_lock start and end when decoding nlm4 testargs
NFS: Fix /proc/PID/io read_bytes for buffered reads
* ACPI: video: Add backlight=native DMI quirk for Acer Aspire 3830TG
The Acer Aspire 3830TG predates Windows 8, so it defaults to using
acpi_video# for backlight control, but this is non functional on
this model.
Add a DMI quirk to use the native backlight interface which does
work properly.
Signed-off-by: Hans de Goede <hdegoede@redhat.com>
Signed-off-by: Rafael J. Wysocki <rafael.j.wysocki@intel.com>
* gpu: host1x: fix uninitialized variable use
The error handling for platform_get_irq() failing no longer works after
a recent change, clang now points this out with a warning:
drivers/gpu/host1x/dev.c:520:6: error: variable 'syncpt_irq' is uninitialized when used here [-Werror,-Wuninitialized]
if (syncpt_irq < 0)
^~~~~~~~~~
Fix this by removing the variable and checking the correct error status.
Fixes: 625d4ffb438c ("gpu: host1x: Rewrite syncpoint interrupt handling")
Signed-off-by: Arnd Bergmann <arnd@arndb.de>
Reviewed-by: Jon Hunter <jonathanh@nvidia.com>
Reviewed-by: Nick Desaulniers <ndesaulniers@google.com>
Reviewed-by: Mikko Perttunen <mperttunen@nvidia.com>
Reviewed-by: Nathan Chancellor <nathan@kernel.org>
Signed-off-by: Linus Torvalds <torvalds@linux-foundation.org>
* zonefs: Prevent uninitialized symbol 'size' warning
In zonefs_file_dio_append(), initialize the variable size to 0 to
prevent compilation and static code analizers warning such as:
New smatch warnings:
fs/zonefs/file.c:441 zonefs_file_dio_append() error: uninitialized
symbol 'size'.
The warning is a false positive as size is never actually used
uninitialized.
No functional change.
Reported-by: kernel test robot <lkp@intel.com>
Reported-by: Dan Carpenter <error27@gmail.com>
Link: https://lore.kernel.org/r/202303191227.GL8Dprbi-lkp@intel.com/
Signed-off-by: Damien Le Moal <damien.lemoal@opensource.wdc.com>
Reviewed-by: Johannes Thumshirn <johannes.thumshirn@wdc.com>
Reviewed-by: Himanshu Madhani <himanshu.madhani@oracle.com>
* zonefs: Fix error message in zonefs_file_dio_append()
Since the expected write location in a sequential file is always at the
end of the file (append write), when an invalid write append location is
detected in zonefs_file_dio_append(), print the invalid written location
instead of the expected write location.
Fixes: a608da3bd730 ("zonefs: Detect append writes at invalid locations")
Cc: stable@vger.kernel.org
Signed-off-by: Damien Le Moal <damien.lemoal@opensource.wdc.com>
Reviewed-by: Christoph Hellwig <hch@lst.de>
Reviewed-by: Johannes Thumshirn <johannes.thumshirn@wdc.com>
Reviewed-by: Himanshu Madhani <himanshu.madhani@oracle.com>
* Merge tag 'fscrypt-for-linus' of git://git.kernel.org/pub/scm/fs/fscrypt/linux
Pull fscrypt fix from Eric Biggers:
"Fix a bug where when a filesystem was being unmounted, the fscrypt
keyring was destroyed before inodes have been released by the Landlock
LSM.
This bug was found by syzbot"
* tag 'fscrypt-for-linus' of git://git.kernel.org/pub/scm/fs/fscrypt/linux:
fscrypt: check for NULL keyring in fscrypt_put_master_key_activeref()
fscrypt: improve fscrypt_destroy_keyring() documentation
fscrypt: destroy keyring after security_sb_delete()
* Merge tag 'fsverity-for-linus' of git://git.kernel.org/pub/scm/fs/fsverity/linux
Pull fsverity fixes from Eric Biggers:
"Fix two significant performance issues with fsverity"
* tag 'fsverity-for-linus' of git://git.kernel.org/pub/scm/fs/fsverity/linux:
fsverity: don't drop pagecache at end of FS_IOC_ENABLE_VERITY
fsverity: Remove WQ_UNBOUND from fsverity read workqueue
* block/io_uring: pass in issue_flags for uring_cmd task_work handling
io_uring_cmd_done() currently assumes that the uring_lock is held
when invoked, and while it generally is, this is not guaranteed.
Pass in the issue_flags associated with it, so that we have
IO_URING_F_UNLOCKED available to be able to lock the CQ ring
appropriately when completing events.
Cc: stable@vger.kernel.org
Fixes: ee692a21e9bf ("fs,io_uring: add infrastructure for uring-cmd")
Signed-off-by: Jens Axboe <axboe@kernel.dk>
* io_uring/net: avoid sending -ECONNABORTED on repeated connection requests
Since io_uring does nonblocking connect requests, if we do two repeated
ones without having a listener, the second will get -ECONNABORTED rather
than the expected -ECONNREFUSED. Treat -ECONNABORTED like a normal retry
condition if we're nonblocking, if we haven't already seen it.
Cc: stable@vger.kernel.org
Fixes: 3fb1bd688172 ("io_uring/net: handle -EINPROGRESS correct for IORING_OP_CONNECT")
Link: https://github.com/axboe/liburing/issues/828
Reported-by: Hui, Chunyang <sanqian.hcy@antgroup.com>
Signed-off-by: Jens Axboe <axboe@kernel.dk>
* octeontx2-vf: Add missing free for alloc_percpu
Add the free_percpu for the allocated "vf->hw.lmt_info" in order to avoid
memory leak, same as the "pf->hw.lmt_info" in
`drivers/net/ethernet/marvell/octeontx2/nic/otx2_pf.c`.
Fixes: 5c0512072f65 ("octeontx2-pf: cn10k: Use runtime allocated LMTLINE region")
Signed-off-by: Jiasheng Jiang <jiasheng@iscas.ac.cn>
Reviewed-by: Michal Swiatkowski <michal.swiatkowski@linux.intel.com>
Acked-by: Geethasowjanya Akula <gakula@marvell.com>
Link: https://lore.kernel.org/r/20230317064337.18198-1-jiasheng@iscas.ac.cn
Signed-off-by: Jakub Kicinski <kuba@kernel.org>
* drm: panel-orientation-quirks: Add quirk for Lenovo Yoga Book X90F
Like the Windows Lenovo Yoga Book X91F/L the Android Lenovo Yoga Book
X90F/L has a portrait 1200x1920 screen used in landscape mode,
add a quirk for this.
When the quirk for the X91F/L was initially added it was written to
also apply to the X90F/L but this does not work because the Android
version of the Yoga Book uses completely different DMI strings.
Also adjust the X91F/L quirk to reflect that it only applies to
the X91F/L models.
Signed-off-by: Hans de Goede <hdegoede@redhat.com>
Reviewed-by: Javier Martinez Canillas <javierm@redhat.com>
Link: https://patchwork.freedesktop.org/patch/msgid/20230301095218.28457-1-hdegoede@redhat.com
* entry: Fix noinstr warning in __enter_from_user_mode()
__enter_from_user_mode() is triggering noinstr warnings with
CONFIG_DEBUG_PREEMPT due to its call of preempt_count_add() via
ct_state().
The preemption disable isn't needed as interrupts are already disabled.
And the context_tracking_enabled() check in ct_state() also isn't needed
as that's already being done by the CT_WARN_ON().
Just use __ct_state() instead.
Fixes the following warnings:
vmlinux.o: warning: objtool: enter_from_user_mode+0xba: call to preempt_count_add() leaves .noinstr.text section
vmlinux.o: warning: objtool: syscall_enter_from_user_mode+0xf9: call to preempt_count_add() leaves .noinstr.text section
vmlinux.o: warning: objtool: syscall_enter_from_user_mode_prepare+0xc7: call to preempt_count_add() leaves .noinstr.text section
vmlinux.o: warning: objtool: irqentry_enter_from_user_mode+0xba: call to preempt_count_add() leaves .noinstr.text section
Fixes: 171476775d32 ("context_tracking: Convert state to atomic_t")
Signed-off-by: Josh Poimboeuf <jpoimboe@kernel.org>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Link: https://lore.kernel.org/r/d8955fa6d68dc955dda19baf13ae014ae27926f5.1677369694.git.jpoimboe@kernel.org
* sched/fair: Sanitize vruntime of entity being migrated
Commit 829c1651e9c4 ("sched/fair: sanitize vruntime of entity being placed")
fixes an overflowing bug, but ignore a case that se->exec_start is reset
after a migration.
For fixing this case, we delay the reset of se->exec_start after
placing the entity which se->exec_start to detect long sleeping task.
In order to take into account a possible divergence between the clock_task
of 2 rqs, we increase the threshold to around 104 days.
Fixes: 829c1651e9c4 ("sched/fair: sanitize vruntime of entity being placed")
Originally-by: Zhang Qiao <zhangqiao22@huawei.com>
Signed-off-by: Vincent Guittot <vincent.guittot@linaro.org>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Tested-by: Zhang Qiao <zhangqiao22@huawei.com>
Link: https://lore.kernel.org/r/20230317160810.107988-1-vincent.guittot@linaro.org
* perf/x86/amd/core: Always clear status for idx
The variable 'status' (which contains the unhandled overflow bits) is
not being properly masked in some cases, displaying the following
warning:
WARNING: CPU: 156 PID: 475601 at arch/x86/events/amd/core.c:972 amd_pmu_v2_handle_irq+0x216/0x270
This seems to be happening because the loop is being continued before
the status bit being unset, in case x86_perf_event_set_period()
returns 0. This is also causing an inconsistency because the "handled"
counter is incremented, but the status bit is not cleaned.
Move the bit cleaning together above, together when the "handled"
counter is incremented.
Fixes: 7685665c390d ("perf/x86/amd/core: Add PerfMonV2 overflow handling")
Signed-off-by: Breno Leitao <leitao@debian.org>
Signed-off-by: Peter Zijlstra (Intel) <peterz@infradead.org>
Reviewed-by: Sandipan Das <sandipan.das@amd.com>
Link: https://lore.kernel.org/r/20230321113338.1669660-1-leitao@debian.org
* entry/rcu: Check TIF_RESCHED _after_ delayed RCU wake-up
RCU sometimes needs to perform a delayed wake up for specific kthreads
handling offloaded callbacks (RCU_NOCB). These wakeups are performed
by timers and upon entry to idle (also to guest and to user on nohz_full).
However the delayed wake-up on kernel exit is actually performed after
the thread flags are fetched towards the fast path check for work to
do on exit to user. As a result, and if there is no other pending work
to do upon that kernel exit, the current task will resume to userspace
with TIF_RESCHED set and the pending wake up ignored.
Fix this with fetching the thread flags _after_ the delayed RCU-nocb
kthread wake-up.
Fixes: 47b8ff194c1f ("entry: Explicitly flush pending rcuog wakeup before last rescheduling point")
Signed-off-by: Frederic Weisbecker <frederic@kernel.org>
Signed-off-by: Paul E. McKenney <paulmck@kernel.org>
Signed-off-by: Joel Fernandes (Google) <joel@joelfernandes.org>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Link: https://lore.kernel.org/r/20230315194349.10798-3-joel@joelfernandes.org
* efi/libstub: zboot: Add compressed image to make targets
Avoid needlessly rebuilding the compressed image by adding the file
'vmlinuz' to the 'targets' Kbuild make variable.
Signed-off-by: Ard Biesheuvel <ardb@kernel.org>
* hwmon: (peci/cputemp) Fix miscalculated DTS for SKX
For Skylake, DTS temperature of the CPU is reported in S10.6 format
instead of S8.8.
Reported-by: Paul Fertser <fercerpav@gmail.com>
Link: https://lore.kernel.org/lkml/ZBhHS7v+98NK56is@home.paul.comp/
Signed-off-by: Iwona Winiarska <iwona.winiarska@intel.com>
Link: https://lore.kernel.org/r/20230321090410.866766-1-iwona.winiarska@intel.com
Signed-off-by: Guenter Roeck <linux@roeck-us.net>
* hwmon: fix potential sensor registration fail if of_node is missing
It is not sufficient to check of_node in current device.
In some cases, this would cause the sensor registration to fail.
This patch looks for device's ancestors to find a valid of_node if any.
Fixes: d560168b5d0f ("hwmon: (core) New hwmon registration API")
Signed-off-by: Phinex Hung <phinex@realtek.com>
Link: https://lore.kernel.org/r/20230321060224.3819-1-phinex@realtek.com
Signed-off-by: Guenter Roeck <linux@roeck-us.net>
* hwmon: (xgene) Fix ioremap and memremap leak
Smatch reports:
drivers/hwmon/xgene-hwmon.c:757 xgene_hwmon_probe() warn:
'ctx->pcc_comm_addr' from ioremap() not released on line: 757.
This is because in drivers/hwmon/xgene-hwmon.c:701 xgene_hwmon_probe(),
ioremap and memremap is not released, which may cause a leak.
To fix this, ioremap and memremap is modified to devm_ioremap and
devm_memremap.
Signed-off-by: Tianyi Jing <jingfelix@hust.edu.cn>
Reviewed-by: Dongliang Mu <dzm91@hust.edu.cn>
Link: https://lore.kernel.org/r/20230318143851.2191625-1-jingfelix@hust.edu.cn
[groeck: Fixed formatting and subject]
Signed-off-by: Guenter Roeck <linux@roeck-us.net>
* bootconfig: Fix testcase to increase max node
Since commit 6c40624930c5 ("bootconfig: Increase max nodes of bootconfig
from 1024 to 8192 for DCC support") increased the max number of bootconfig
node to 8192, the bootconfig testcase of the max number of nodes fails.
To fix this issue, we can not simply increase the number in the test script
because the test bootconfig file becomes too big (>32KB). To fix that, we
can use a combination of three alphabets (26^3 = 17576). But with that,
we can not express the 8193 (just one exceed from the limitation) because
it also exceeds the max size of bootconfig. So, the first 26 nodes will just
use one alphabet.
With this fix, test-bootconfig.sh passes all tests.
Link: https://lore.kernel.org/all/167888844790.791176.670805252426835131.stgit@devnote2/
Reported-by: Heinz Wiesinger <pprkut@slackware.com>
Link: https://lore.kernel.org/all/2463802.XAFRqVoOGU@amaterasu.liwjatan.org
Fixes: 6c40624930c5 ("bootconfig: Increase max nodes of bootconfig from 1024 to 8192 for DCC support")
Signed-off-by: Masami Hiramatsu (Google) <mhiramat@kernel.org>
Reviewed-by: Steven Rostedt (Google) <rostedt@goodmis.org>
* keys: Do not cache key in task struct if key is requested from kernel thread
The key which gets cached in task structure from a kernel thread does not
get invalidated even after expiry. Due to which, a new key request from
kernel thread will be served with the cached key if it's present in task
struct irrespective of the key validity. The change is to not cache key in
task_struct when key requested from kernel thread so that kernel thread
gets a valid key on every key request.
The problem has been seen with the cifs module doing DNS lookups from a
kernel thread and the results getting pinned by being attached to that
kernel thread's cache - and thus not something that can be easily got rid
of. The cache would ordinarily be cleared by notify-resume, but kernel
threads don't do that.
This isn't seen with AFS because AFS is doing request_key() within the
kernel half of a user thread - which will do notify-resume.
Fixes: 7743c48e54ee ("keys: Cache result of request_key*() temporarily in task_struct")
Signed-off-by: Bharath SM <bharathsm@microsoft.com>
Signed-off-by: David Howells <dhowells@redhat.com>
Reviewed-by: Jarkko Sakkinen <jarkko@kernel.org>
cc: Shyam Prasad N <nspmangalore@gmail.com>
cc: Steve French <smfrench@gmail.com>
cc: keyrings@vger.kernel.org
cc: linux-cifs@vger.kernel.org
cc: linux-fsdevel@vger.kernel.org
Link: https://lore.kernel.org/r/CAGypqWw951d=zYRbdgNR4snUDvJhWL=q3=WOyh7HhSJupjz2vA@mail.gmail.com/
* verify_pefile: relax wrapper length check
The PE Format Specification (section "The Attribute Certificate Table
(Image Only)") states that `dwLength` is to be rounded up to 8-byte
alignment when used for traversal. Therefore, the field is not required
to be an 8-byte multiple in the first place.
Accordingly, pesign has not performed this alignment since version
0.110. This causes kexec failure on pesign'd binaries with "PEFILE:
Signature wrapper len wrong". Update the comment and relax the check.
Signed-off-by: Robbie Harwood <rharwood@redhat.com>
Signed-off-by: David Howells <dhowells@redhat.com>
cc: Jarkko Sakkinen <jarkko@kernel.org>
cc: Eric Biederman <ebiederm@xmission.com>
cc: Herbert Xu <herbert@gondor.apana.org.au>
cc: keyrings@vger.kernel.org
cc: linux-crypto@vger.kernel.org
cc: kexec@lists.infradead.org
Link: https://learn.microsoft.com/en-us/windows/win32/debug/pe-format#the-attribute-certificate-table-image-only
Link: https://github.com/rhboot/pesign
Link: https://lore.kernel.org/r/20230220171254.592347-2-rharwood@redhat.com/ # v2
* asymmetric_keys: log on fatal failures in PE/pkcs7
These particular errors can be encountered while trying to kexec when
secureboot lockdown is in place. Without this change, even with a
signed debug build, one still needs to reboot the machine to add the
appropriate dyndbg parameters (since lockdown blocks debugfs).
Accordingly, upgrade all pr_debug() before fatal error into pr_warn().
Signed-off-by: Robbie Harwood <rharwood@redhat.com>
Signed-off-by: David Howells <dhowells@redhat.com>
cc: Jarkko Sakkinen <jarkko@kernel.org>
cc: Eric Biederman <ebiederm@xmission.com>
cc: Herbert Xu <herbert@gondor.apana.org.au>
cc: keyrings@vger.kernel.org
cc: linux-crypto@vger.kernel.org
cc: kexec@lists.infradead.org
Link: https://lore.kernel.org/r/20230220171254.592347-3-rharwood@redhat.com/ # v2
* ice: fix rx buffers handling for flow director packets
Adding flow director filters stopped working correctly after
commit 2fba7dc5157b ("ice: Add support for XDP multi-buffer
on Rx side"). As a result, only first flow director filter
can be added, adding next filter leads to NULL pointer
dereference attached below.
Rx buffer handling and reallocation logic has been optimized,
however flow director specific traffic was not accounted for.
As a result driver handled those packets incorrectly since new
logic was based on ice_rx_ring::first_desc which was not set
in this case.
Fix this by setting struct ice_rx_ring::first_desc to next_to_clean
for flow director received packets.
[ 438.544867] BUG: kernel NULL pointer dereference, address: 0000000000000000
[ 438.551840] #PF: supervisor read access in kernel mode
[ 438.556978] #PF: error_code(0x0000) - not-present page
[ 438.562115] PGD 7c953b2067 P4D 0
[ 438.565436] Oops: 0000 [#1] PREEMPT SMP NOPTI
[ 438.569794] CPU: 0 PID: 0 Comm: swapper/0 Kdump: loaded Not tainted 6.2.0-net-bug #1
[ 438.577531] Hardware name: Intel Corporation M50CYP2SBSTD/M50CYP2SBSTD, BIOS SE5C620.86B.01.01.0005.2202160810 02/16/2022
[ 438.588470] RIP: 0010:ice_clean_rx_irq+0x2b9/0xf20 [ice]
[ 438.593860] Code: 45 89 f7 e9 ac 00 00 00 8b 4d 78 41 31 4e 10 41 09 d5 4d 85 f6 0f 84 82 00 00 00 49 8b 4e 08 41 8b 76
1c 65 8b 3d 47 36 4a 3f <48> 8b 11 48 c1 ea 36 39 d7 0f 85 a6 00 00 00 f6 41 08 02 0f 85 9c
[ 438.612605] RSP: 0018:ff8c732640003ec8 EFLAGS: 00010082
[ 438.617831] RAX: 0000000000000800 RBX: 00000000000007ff RCX: 0000000000000000
[ 438.624957] RDX: 0000000000000800 RSI: 0000000000000000 RDI: 0000000000000000
[ 438.632089] RBP: ff4ed275a2158200 R08: 00000000ffffffff R09: 0000000000000020
[ 438.639222] R10: 0000000000000000 R11: 0000000000000020 R12: 0000000000001000
[ 438.646356] R13: 0000000000000000 R14: ff4ed275d0daffe0 R15: 0000000000000000
[ 438.653485] FS: 0000000000000000(0000) GS:ff4ed2738fa00000(0000) knlGS:0000000000000000
[ 438.661563] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 438.667310] CR2: 0000000000000000 CR3: 0000007c9f0d6006 CR4: 0000000000771ef0
[ 438.674444] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000
[ 438.681573] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400
[ 438.688697] PKRU: 55555554
[ 438.691404] Call Trace:
[ 438.693857] <IRQ>
[ 438.695877] ? profile_tick+0x17/0x80
[ 438.699542] ice_msix_clean_ctrl_vsi+0x24/0x50 [ice]
[ 438.702571] ice 0000:b1:00.0: VF 1: ctrl_vsi irq timeout
[ 438.704542] __handle_irq_event_percpu+0x43/0x1a0
[ 438.704549] handle_irq_event+0x34/0x70
[ 438.704554] handle_edge_irq+0x9f/0x240
[ 438.709901] iavf 0000:b1:01.1: Failed to add Flow Director filter with status: 6
[ 438.714571] __common_interrupt+0x63/0x100
[ 438.714580] common_interrupt+0xb4/0xd0
[ 438.718424] iavf 0000:b1:01.1: Rule ID: 127 dst_ip: 0.0.0.0 src_ip 0.0.0.0 UDP: dst_port 4 src_port 0
[ 438.722255] </IRQ>
[ 438.722257] <TASK>
[ 438.722257] asm_common_interrupt+0x22/0x40
[ 438.722262] RIP: 0010:cpuidle_enter_state+0xc8/0x430
[ 438.722267] Code: 6e e9 25 ff e8 f9 ef ff ff 8b 53 04 49 89 c5 0f 1f 44 00 00 31 ff e8 d7 f1 24 ff 45
84 ff 0f 85 57 02 00 00 fb 0f 1f 44 00 00 <45> 85 f6 0f 88 85 01 00 00 49 63 d6 48 8d 04 52 48 8d 04 82 49 8d
[ 438.722269] RSP: 0018:ffffffff86003e50 EFLAGS: 00000246
[ 438.784108] RAX: ff4ed2738fa00000 RBX: ffbe72a64fc01020 RCX: 0000000000000000
[ 438.791234] RDX: 0000000000000000 RSI: ffffffff858d84de RDI: ffffffff85893641
[ 438.798365] RBP: 0000000000000002 R08: 0000000000000002 R09: 000000003158af9d
[ 438.805490] R10: 0000000000000008 R11: 0000000000000354 R12: ffffffff862365a0
[ 438.812622] R13: 000000661b472a87 R14: 0000000000000002 R15: 0000000000000000
[ 438.819757] cpuidle_enter+0x29/0x40
[ 438.823333] do_idle+0x1b6/0x230
[ 438.826566] cpu_startup_entry+0x19/0x20
[ 438.830492] rest_init+0xcb/0xd0
[ 438.833717] arch_call_rest_init+0xa/0x30
[ 438.837731] start_kernel+0x776/0xb70
[ 438.841396] secondary_startup_64_no_verify+0xe5/0xeb
[ 438.846449] </TASK>
Fixes: 2fba7dc5157b ("ice: Add support for XDP multi-buffer on Rx side")
Signed-off-by: Piotr Raczynski <piotr.raczynski@intel.com>
Acked-by: Maciej Fijalkowski <maciej.fijalkowski@intel.com>
Reviewed-by: Simon Horman <simon.horman@corigine.com>
Tested-by: Arpana Arland <arpanax.arland@intel.com> (A Contingent worker at Intel)
Signed-off-by: Tony Nguyen <anthony.l.nguyen@intel.com>
* ice: check if VF exists before mode check
Setting trust on VF should return EINVAL when there is no VF. Move
checking for switchdev mode after checking if VF exists.
Fixes: c54d209c78b8 ("ice: Wait for VF to be reset/ready before configuration")
Signed-off-by: Michal Swiatkowski <michal.swiatkowski@intel.com>
Signed-off-by: Kalyan Kodamagula <kalyan.kodamagula@intel.com>
Tested-by: Sujai Buvaneswaran <sujai.buvaneswaran@intel.com>
Signed-off-by: Tony Nguyen <anthony.l.nguyen@intel.com>
* ice: remove filters only if VSI is deleted
Filters shouldn't be removed in VSI rebuild path. Removing them on PF
VSI results in no rule for PF MAC after changing for example queues
amount.
Remove all filters only in the VSI remove flow. As unload should also
cause the filter to be removed introduce, a new function ice_stop_eth().
It will unroll ice_start_eth(), so remove filters and close VSI.
Fixes: 6624e780a577 ("ice: split ice_vsi_setup into smaller functions")
Signed-off-by: Michal Swiatkowski <michal.swiatkowski@linux.intel.com>
Tested-by: Arpana Arland <arpanax.arland@intel.com> (A Contingent worker at Intel)
Signed-off-by: Tony Nguyen <anthony.l.nguyen@intel.com>
* iavf: fix hang on reboot with ice
When a system with E810 with existing VFs gets rebooted the following
hang may be observed.
Pid 1 is hung in iavf_remove(), part of a network driver:
PID: 1 TASK: ffff965400e5a340 CPU: 24 COMMAND: "systemd-shutdow"
#0 [ffffaad04005fa50] __schedule at ffffffff8b3239cb
#1 [ffffaad04005fae8] schedule at ffffffff8b323e2d
#2 [ffffaad04005fb00] schedule_hrtimeout_range_clock at ffffffff8b32cebc
#3 [ffffaad04005fb80] usleep_range_state at ffffffff8b32c930
#4 [ffffaad04005fbb0] iavf_remove at ffffffffc12b9b4c [iavf]
#5 [ffffaad04005fbf0] pci_device_remove at ffffffff8add7513
#6 [ffffaad04005fc10] device_release_driver_internal at ffffffff8af08baa
#7 [ffffaad04005fc40] pci_stop_bus_device at ffffffff8adcc5fc
#8 [ffffaad04005fc60] pci_stop_and_remove_bus_device at ffffffff8adcc81e
#9 [ffffaad04005fc70] pci_iov_remove_virtfn at ffffffff8adf9429
#10 [ffffaad04005fca8] sriov_disable at ffffffff8adf98e4
#11 [ffffaad04005fcc8] ice_free_vfs at ffffffffc04bb2c8 [ice]
#12 [ffffaad04005fd10] ice_remove at ffffffffc04778fe [ice]
#13 [ffffaad04005fd38] ice_shutdown at ffffffffc0477946 [ice]
#14 [ffffaad04005fd50] pci_device_shutdown at ffffffff8add58f1
#15 [ffffaad04005fd70] device_shutdown at ffffffff8af05386
#16 [ffffaad04005fd98] kernel_restart at ffffffff8a92a870
#17 [ffffaad04005fda8] __do_sys_reboot at ffffffff8a92abd6
#18 [ffffaad04005fee0] do_syscall_64 at ffffffff8b317159
#19 [ffffaad04005ff08] __context_tracking_enter at ffffffff8b31b6fc
#20 [ffffaad04005ff18] syscall_exit_to_user_mode at ffffffff8b31b50d
#21 [ffffaad04005ff28] do_syscall_64 at ffffffff8b317169
#22 [ffffaad04005ff50] entry_SYSCALL_64_after_hwframe at ffffffff8b40009b
RIP: 00007f1baa5c13d7 RSP: 00007fffbcc55a98 RFLAGS: 00000202
RAX: ffffffffffffffda RBX: 0000000000000000 RCX: 00007f1baa5c13d7
RDX: 0000000001234567 RSI: 0000000028121969 RDI: 00000000fee1dead
RBP: 00007fffbcc55ca0 R8: 0000000000000000 R9: 00007fffbcc54e90
R10: 00007fffbcc55050 R11: 0000000000000202 R12: 0000000000000005
R13: 0000000000000000 R14: 00007fffbcc55af0 R15: 0000000000000000
ORIG_RAX: 00000000000000a9 CS: 0033 SS: 002b
During reboot all drivers PM shutdown callbacks are invoked.
In iavf_shutdown() the adapter state is changed to __IAVF_REMOVE.
In ice_shutdown() the call chain above is executed, which at some point
calls iavf_remove(). However iavf_remove() expects the VF to be in one
of the states __IAVF_RUNNING, __IAVF_DOWN or __IAVF_INIT_FAILED. If
that's not the case it sleeps forever.
So if iavf_shutdown() gets invoked before iavf_remove() the system will
hang indefinitely because the adapter is already in state __IAVF_REMOVE.
Fix this by returning from iavf_remove() if the state is __IAVF_REMOVE,
as we already went through iavf_shutdown().
Fixes: 974578017fc1 ("iavf: Add waiting so the port is initialized in remove")
Fixes: a8417330f8a5 ("iavf: Fix race condition between iavf_shutdown and iavf_remove")
Reported-by: Marius Cornea <mcornea@redhat.com>
Signed-off-by: Stefan Assmann <sassmann@kpanic.de>
Reviewed-by: Michal Kubiak <michal.kubiak@intel.com>
Tested-by: Rafal Romanowski <rafal.romanowski@intel.com>
Signed-off-by: Tony Nguyen <anthony.l.nguyen@intel.com>
* i40e: fix flow director packet filter programming
Initialize to zero structures to build a valid
Tx Packet used for the filter programming.
Fixes: a9219b332f52 ("i40e: VLAN field for flow director")
Signed-off-by: Radoslaw Tyl <radoslawx.tyl@intel.com>
Reviewed-by: Michal Swiatkowski <michal.swiatkowski@linux.intel.com>
Tested-by: Arpana Arland <arpanax.arland@intel.com> (A Contingent worker at Intel)
Sign…
Considering this case:
A client socket tries to connect to a non-listening port of a server socket. Based on my knowledge, the client will receive an RST and the errno is set to ECONNREFUSED (which is the behavior implemented in Linux). On the second try, the behavior should be the same and errno is still ECONNREFUSED.
This behavior is the same for sync "connect()" on both the 5.15 and 6.2 kernels and the io_uring connect on Linux 5.15. But for the 6.2 kernel, the second io_uring connect returns
ECONNABORTED.I made a minimal test to demonstrate this and will be put at the end of this issue. I would like to know if I am doing anything wrong or if this is a bug or a known issue or if it is intended. Thank you!
Code to reproduce:
On Linux 5.15:
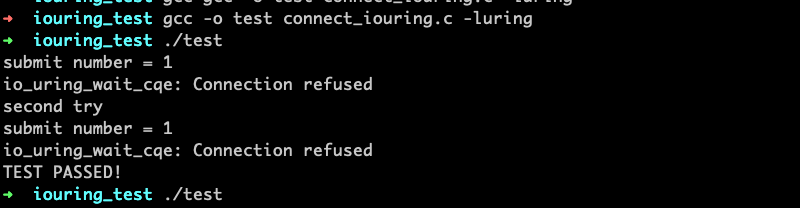
On Linux 6.2:

The text was updated successfully, but these errors were encountered: