audio_device selection in Livespeech #23
Comments
|
@saibharani but if you are asking about an ALSA audio_device=2 you may get (like I am getting...):
LiveSpeech() seems to be trying pulseaudio, can it use ALSA device? Can we use a USB mic that only supports 44.1K and 48K sample_rate? |
|
@slowrunner . may be this late as I joined this platform late.. May be you are not in this need anymore. But can be helpful for others.. By default LiveSpeech will call ad_pulse.py when sys.platform.startswith('linux').. as in your case it is calling ad_pulse. But if you want to change this call to as_alsa.py, simple change below lines in /usr/local/lib/python2.7/dist-packages/sphinxbase/init.py: import sys if sys.platform.startswith('win'): from .sphinxbase import * Please check above in bold and italic. Hope this helps |
|
@bkravi-os-iot Thank you. Made that change in each sphinxbase/__init__.py, but still not having enough success. If I use LiveSpeech(audio_device='hw:1,0',sampling_rate=16000...), it finds the capture device but claims: (This may be the HDMI device though, not my USB mic) which is weird because in a non-livespeech script I use: and pocketsphinx works just fine. I tried sampling_rate=11025 but pocketsphinx only has a 16k model and cores: btw: arecord -l |
|
I got a sollution (works for me) (: Example NOTE: I needed to change the init.py as @bkravi-os-iot said. (Thank you) |
|
Hi (:
Yes, what i did was chage the file __init__.py that is on the sphinxbase directory.
Just get into that directory and type:
sudo nano __init__.py
Change the two lines and it's done.
I'll put two screenshots to make it easier for you.
El 09/12/2019 6:54 p. m., Judison Bacalso <notifications@github.com> escribió:
Hi @Ozer0<https://github.com/Ozer0> I was just wondering how did you change the init.py that @bkravi-os-iot<https://github.com/bkravi-os-iot> said. because i cannot change it because it cannot be writable. Thanks!
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub<#23?email_source=notifications&email_token=AMFRP7XP7G5MUZ5MTIUIRSDQX3SGDA5CNFSM4DMNPF72YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEGLHUIA#issuecomment-563509792>, or unsubscribe<https://github.com/notifications/unsubscribe-auth/AMFRP7URAOEIIBHT6PUBN63QX3SGDANCNFSM4DMNPF7Q>.
|
|
Hi @Ozer0 Error opening audio device plughw:1,0 for capture: Invalid argument I just follow what you said above about the audio_device. |
|
By the way, I am running this in Raspberry Pi |
|
Ok, my init.py looks like this. I had the same problem. Did you tried with this comand on the console? If there's the problem like "ERROR continuos.c" maybe when you builded sphinxbase the Raspberry choosed pulseaudio instead of ALSA. So, check this link. http://robot.laylamah.com/?p=35 You have to verify Sphinxbase uses ALSA when you type the comand ./configure. Even if you didn't installed pulseaudio this could happen (my case), so what I did was look for that pulseaudio.h file that makes that error. It was on a directory called Pulse in the /home/pi I think you could look for the file with whis comand on the console |
|
Working with pocketsphinx python on Raspberry could be difficult because of many errors while installing all dependencies, that's why I'm working on a YouTube tutorial for begginers like me. |
|
How can I choose the ALSA? I cannot find this when i configure the sphinxbase I am really confused now :< |
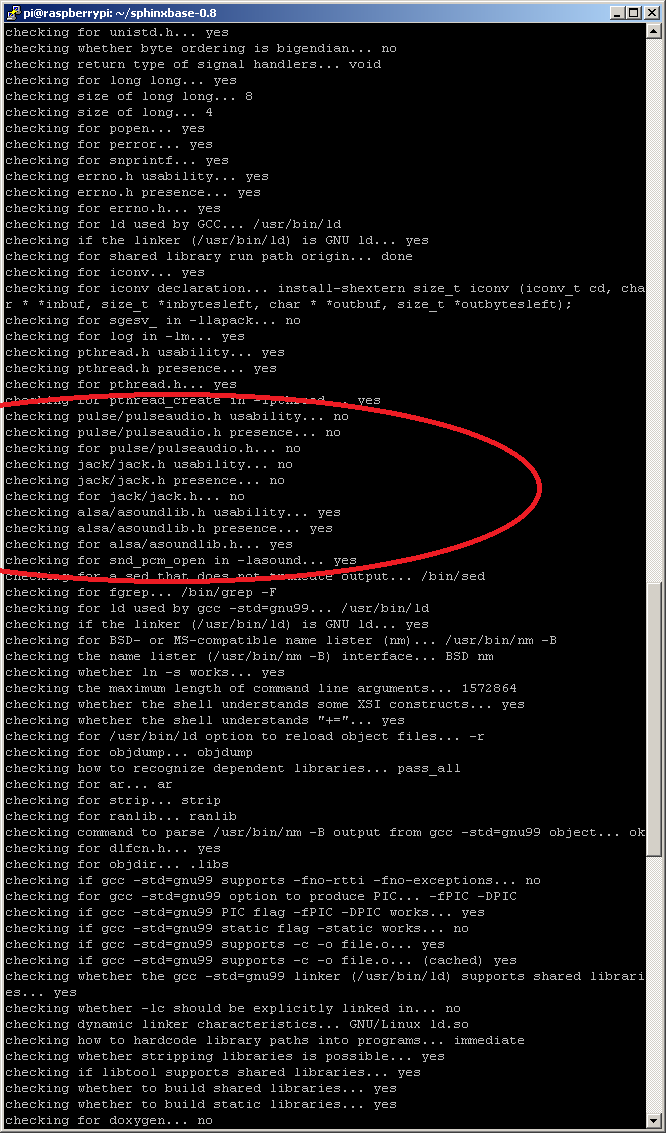
|
First of all do the steps to rename or move the "pulseaudio.h" file or if it's the case, uninstall pulseaudio. Then you have to re-configure sphinxbase with ./configure |
|
I already re-configured my sphinxbase and I already saw checking for alsa/aaoundlib.h .. yes. And I also uninstall my pulseaudio. My problem now is when i check the alsamixer it has an error: After I uninstall my pulseaudio this error came up. Been searching for a while for this error but cannot fixed. |

|
Did you only uninstall pulseaudio? |
|
I uninstall pocketsphinx and sphinxbase. Re-configured them all but when I check init.py i doesnt have any code. Now, when i run this: pocketsphinx_continuous -inmic yes -adcdev plughw:1,0 this is the output:
Can you determine what did I do wrong? |


|
Are you sure you're trying to edit the sphinxbase's init.py? And about the problem, seems you need to specific the language model. You can try with a comand like this Try tp add the 3 parameter |

|
Hi sir! I am able to run the continuous now. But the thing is i cannot run this line: pocketsphinx_continuous -inmic yes -adcdev plughw:1,0 I can only run by using this ./src/programs/pocketsphinx_continuous -adcdev plughw:1,0 -nfft 2048 -samprate 48000. When im using the first one the error is this But when I use the second one i need to go to the pocketsphinx folder and run it there. I just followed the steps you linked to me before. |

|
I fixed it using sudo ldconfig. |
|
Happy to hear that. |
|
Yes, I am using the one you gave. Is there a way to catch the string? Or I will need the LiveSpeech? |
|
Yeah, you have to use LiveSpeech and convert the "phrase" in code. Also you can create your own dictionary and language model to reduce the error, it's very helpful. See this page (Step 8) https://medium.com/@ranjanprj/for-some-time-now-i-have-been-thinking-really-hard-to-build-a-diy-study-aid-for-children-which-uses-17ce90e72f43 |
|
I followed the steps of the video you showed me and it has an error about the LiveSpeech But the using the pocketpshinx_continuous does not have an error. I even create my own dictionary and language. |

|
Why are you executing your script with ./ ? |
|
Why I cannot import LiveSpeech? |
|
That's was my problem too haha Here are the steps I followed, you should try with pip3 instead of pip. |

|
First try to uninstall pocketsphinx python with |
|
Hi! Do you have any idea how to deal with this?
|

|
I am back with this error.
I already change init.py from pulse to alsa. Both 3.7 and 2.7. I just followed the video you linked. |

|
Hey man, did you solve it? |
|
Nah. I keep getting the error like this. Same error for python 2 and 3.
I changed the init.py but the error still there. |
|
What parameters you put in the LiveSpeech? |
|
See my first reply on this post |
|
I got it now sir! Thank you so much! 👍 really appreciate your help! |
|
Very happy to hear you finally can use it :D And not a Sir, I'm just 22 haha |
|
Hi! Im back again! :D Is there a way to catch it? |
|
Do you want to do something with the words you say? |
|
Yes. It cannot catch all of my sentence because when I try to use it, it will automatically read what I say. Is there way that the livespeech could run when im done talking? |
|
I have a custom language model and dictionary already. |
|
Ok, you have to use your .lm and .dict files in the LiveSpeech's parameters function. Then you need to compare the string with the words you say |
|
|

|
|

|
|

|
Ya, we have the same code. But I dont know why it will automatically print the phrase even if im not done talking yet. |
|
The dictionary you created is conformed of only words?, or you wrote the wole phrases (two or more words)? etc |
|
What I wrote on my txt file is by word like OFF, ON, OPEN, CLOSE, etc. I cannot get the whole sentence because it will break automatically for example i will say "Please turn on the lights". The sentence will be separated to PLEASE TURN and ON THE LIGHTS. That is my problem as of now. I cannot get the whole phrase |
|
Maybe you should try using the whole phrases in your txt file. |
|
Hi @Ozer0 ,I hope you want to help me But i still have a error like this Error opening audio device plughw:1,0 for capture: Device or resource busy As you can see audio device plughw:1,0 is error, i already check using arecord -l, i hope you have any solution, anyway im using respeaker 4-mic array |
|
pi@raspberrypi:~ $ arecord -l |
|
|
@Ozer0 Thanks for you reply, actually i already fix that but now i have this error RuntimeError: new_Decoder returned -1 I know this is happend because path problem, but i dont know how to set right path, i use your code model_path = get_model_path() speech = LiveSpeech( Can you teach me this part of line " model_path = get_model_path() " |
Hi, you solved the problem? |
|
@Ozer0 actually no error right now, but now my problem is LiveSpeech cant recognize anything.. When i use http://blog.justsophie.com/python-speech-to-text-with-pocketsphinx/ decode method, it can recognize 1 word then input over flowed because my raspberry pi cpu too slow So my last hope is using LiveSpeech, im wondering why no error but cant recognize anything, when I use pocketsphinx_continuous, it works can record my word and can give me output. Can you help me |
Well, gotta say I used LiveSpeech in a Raspberry Zero so i don't think the CPU is your problem. |
|
@Ozer0 i find the another solution! I use decode method not using LiveSpeech and can do hotword after that give intruction to system. Thanks for this thread and all of you guys, really helped me |
I want to do keyword recognition from a specific mic. Can you tell me how to do audio_device selection.
I want to select audio_device with index 2.
Thank you.
The text was updated successfully, but these errors were encountered: