![]()
![]()
This gem provides Faraday middleware that allows you to set dynamic timeouts on HTTP requests based on the current number of requests being made to an endpoint. This allows you to set a long enough timeout to handle your slowest requests when the system is healthy, but then progressively set shorter timeouts as load increases so requests can fail fast in an unhealthy system.
It's always hard to figure out what the proper timeout is for an HTTP request. If you set it too short, then you will get errors on an occasional request that takes just a little longer than normal. If you set it too long, then you will end up with a system that becomes unresponsive when something goes wrong and most of your application resouces can end up waiting on an external system that just isn't working.
This middleware works by letting you set "buckets" of timeouts. In a simple use case, you would setup a small bucket with a long timeout and a large bucket with a short timeout. Each concurrent request to a service will use up one slot in each bucket and will use the highest available request timeout available.
Under normal load, the long timeout will be used for all requests (if you've set the bucket limit high enough). However, as the number of concurrent requests increases (for example, when the external service starts responding more slowly), the request timeouts will be automatically reduced as requests start falling over to the next bucket with a lower timeout. If the number of concurrent requests exceeds the limit of the last bucket, then an exception will be raised without even making the request.
This chart shows the basic logic:
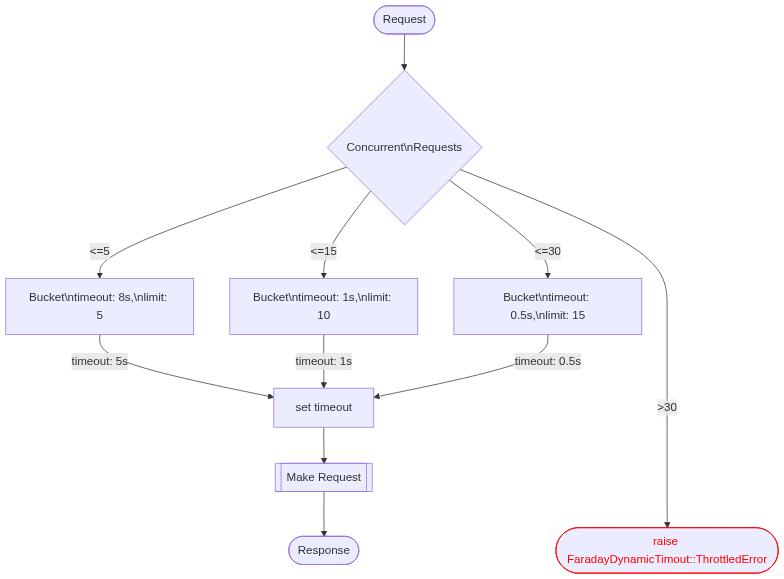
This setup makes for a system that degrades gracefully and predictably. When the external system starts having issues, you will still be sending requests to it, but they will start failing fast and at a certain limit they will fail immediately without even trying to make a request (which would have most likely only added to the issues on the external system). This can allow your system to remain functional (albeit in a degraded state) and to automatically recover when the external system recovers.
The middleware requires a redis server which is used to count the number of concurrent requests being made to an endpoint across all processes.
The middleware can be installed in your Faraday connection like this:
require "faraday_dynamic_timeout"
connection = Faraday.new do |faraday|
faraday.use(
:dynamic_timeout,
buckets: [
{timeout: 8, limit: 5},
{timeout: 1, limit: 10},
{timeout: 0.5, limit: 20}
]
)
endIn this example, the timeout will be set to 8 seconds if there are 5 or fewer requests being made to an endpoint, 1 second if there are 10 or fewer requests, and 0.5 seconds if there are 20 or fewer requests. If there are more than 20 requests being made to an endpoint, an exception will be raised.
-
:buckets- An array of bucket configurations. Each bucket is a hash with two keys::timeoutand:limit. The:timeoutvalue is the timeout to use for requests when it falls into that bucket. The:limitvalue is the maximum number of concurrent requests that can use that bucket. Requests will always try to use the bucket with the highest timeout, so order does not matter. If a bucket has a limit less than zero, it will be considered unlimited and requests will never fall over to the next bucket. This value can also be set as aProc(or any object that responds tocall) that will be evaluated at runtime when each request is made. -
:redis- The redis connection to use. This should be aRedisobject or aProcthat yields aRedisobject. If not provided, a defaultRedisconnection will be used (configured using environment variables). If the value is explicitly set to nil, then the middleware will pass through all requests without doing anything. -
:name- An optional name for the resource. By default the hostname and port of the request URL will be used to identify the resource. Each resource will report a separate count of concurrent requests and processes. You can group multiple resources from different hosts together with the:nameoption. -
:before_request- An optional callback that will be called before each request is made. The callback can be aProcor any object that responds tocall. It will be called before the request is made with theFaraday::Envobject and the timeout being used. You can use this to make changes to the request based on the timeout being used. This can be used, for example, to add the timeout to the request payload. -
:callback- An optional callback that will be called after each request. The callback can be aProcor any object that responds tocall. It will be called with aFaradayDyamicTimeout::RequestInfoargument. You can use this to log the number of concurrent requests or to report metrics to a monitoring system. This can be very useful for tuning the bucket settings.
You can use the FaraadyDynamicTimeout::CapacityStrategy class to build a bucket configuration based on the current capacity of your application rather than hard coding bucket limits. This can be useful if you have a system that can scale up and down based on load. It works by estimating the total number of threads available in your application and uses that value to calculate bucket limits based on a percentage provided by the :capacity option.
capacity = FaradayDynamicTimeout::CapacityStrategy.new(
buckets: [
{timeout: 8, capacity: 0.05, limit: 3},
{timeout: 1, capacity: 0.05},
{timeout: 0.5, capacity: 0.10},
{timeout: 0.2, capacity: 1.0}
],
threads_per_process: 4
)In this example, it will be assumed that each process has 4 threads, The first bucket will have a limit of 5% of the application threads but it will never be less than 3 (because of the hardcoded :limit option). The second bucket will have a limit of 5% of the application threads (rounded up). The third bucket will have a limit of 10% of the application threads. The forth bucket will have unlimited capacity (100%) and will serve all requests that exceed the limits of the previous buckets.
The number of processes is estimated. Every time a process makes a request through the middleware, it will be remembered for 60 seconds. So if you have processes that have not made any requests through the middleware, they will not be counted. Processes that have been terminated will also be considered in the calculation for up to 60 seconds. You should still get a pretty good estimate of the number of processes that are currently running. The number will be less accurate if you application is scaling up and down very quickly (i.e. during a deployment) or when it is not very active. In the deployment case the estimate will be high so it should not cause any problems. In the low activity case you aren't really worried about load and the bucket sizes will never be lower than 1. In any case, it's a good idea to set a minimum limit on the first bucket.
For this example, we will configure the opensearch gem with this middleware along with metrics tracking to a statsd servers.
# Set up a redis connection to coordinate counting concurrent requests.
redis = Redis.new(url: ENV.fetch("REDIS_URL"))
# Set the query timeout to match the request timeout so the search nodes will stop
# processing if the request times out.
set_query_timeout = ->(env, timeout) do
query_params = (Faraday::Utils.parse_query(env.url.query) || {})
query_params["timeout"] = "#{timeout}s"
env.url.query = Faraday::Utils.build_query(query_params)
end
# Set up a statsd client to report metrics with the DataDog extensions.
statsd = Statsd.new(ENV.fetch("STATSD_HOST"), ENV.fetch("STATSD_PORT"))
metrics_callback = ->(request_info) do
batch = Statsd::Batch.new(statsd)
batch.gauge("opensearch.concurrent_requests", request_info.request_count)
batch.timing("opensearch.duration", (request_info.duration * 1000).round)
batch.increment("opensearch.throttled") if request_info.throttled?
batch.increment("opensearch.timed_out") if request_info.timed_out?
batch.flush
end
client = OpenSearch::Client.new(host: 'localhost', port: '9200') do |faraday|
faraday.request :dynamic_timeout,
buckets: [
{timeout: 8, max_requests: 5},
{timeout: 1, max_requests: 10},
{timeout: 0.5, max_requests: 20}
],
name: "opensearch",
redis: redis,
filter: ->(env) { env.url.path.end_with?("/_search") },
before_request: set_payload_timeout,
callback: metrics_callback
endAdd this line to your application's Gemfile:
gem "faraday_dynamic_timeout"And then execute:
$ bundleOr install it yourself as:
$ gem install faraday_dynamic_timeoutOpen a pull request on GitHub.
Please use the standardrb syntax and lint your code with standardrb --fix before submitting.
The gem is available as open source under the terms of the MIT License.