This project is a city search service powered by Algolia using gazetteer data from GeoNames. This document details the rationale behind the design and implementation of the city search service. The url of this service is the following: https://benjbaron.github.io/GeoNames/. The page shows a search input, just start typing the name of a city and the search box will automatically suggest relevant cities. The source code for the web client is under a different branch of this repository available at this link.
The data is downloaded from the GeoNames data repository. The GeoNames dataset consists of multiple files, including the following files that are important for the purpose of the service:
allCountries: all countries combined in one file,alternateNamesV2: alternate names with language codes andgeonameId.
Note that, according to the GeoNames documentation, the field alternatenames in the GeoNames dataset (allCountries) is a short version of the alternateNamesV2 dataset. As such, they imply that both are equivalent. For the rest of this project, I will not consider the alternateNamesV2 dataset and instead use the alternatenames field in the GeoNames dataset.
Remark: the field 'alternatenames' in the table 'geoname' is a short version of the 'alternatenames' table without links and postal codes but with ascii transliterations. You probably don't need both. If you don't need to know the language of a name variant, the field 'alternatenames' will be sufficient. If you need to know the language of a name variant, then you will need to load the table 'alternatenames' and you can drop the column in the geoname table.
The postal codes are made available in a different data repository.
While each GeoName feature is identified by a unique id (geonameid), the postal codes are not directly associated to the different GeoNames features. The main challenge in implementing this service is to link the different postal codes features with individual GeoNames features.
A general picture of the data processing pipeline is depicted in the figure below. The pipeline is divided in three main stages:
- Preliminary filtering of the two datasets,
- Matching the Postal Code features with GeoNames features by joining and aggregating the two datasets,
- Preparation of the final dataset by joining to get all the feature attributes.
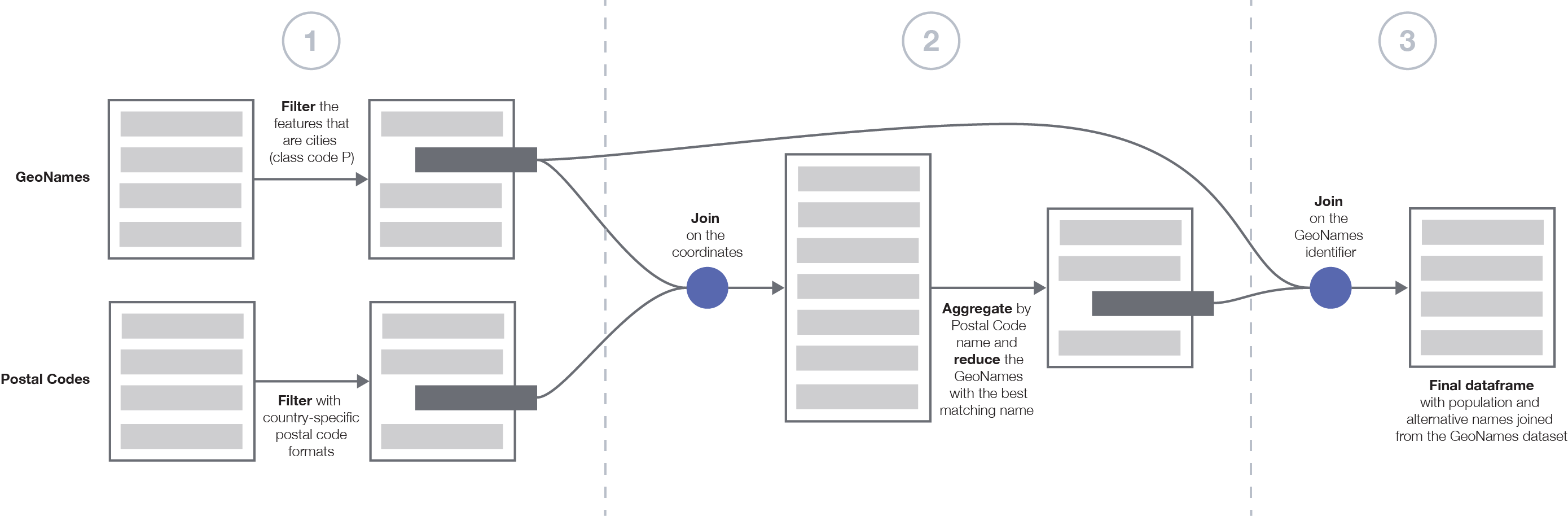
The data processing pipeline was written in a Jupyter notebook. The resulting files of the pipeline are given in the output folder.
Filter cities. First, I processed the features of the GeoNames dataset in order to filter those that correspond to cities. According to the documentation of the GeoNames dataset, city features are given by the feature class P, which correspond to populated places such as cities, villages, etc. This reduces the size of the dataset from 11,816,412 features in the GeoNames dataset to 4,697,045 features in the filtered GeoNames dataset.
Filtering postal codes. There are a few caveats when linking postal codes with cities. The first one is the fact that some countries do not have postal codes. Since the GeoNames dataset covers the whole world, it spans countries that do not have postal codes, therefore the association with the cities cannot be made.
Furthermore, the postal codes follow well-defined patterns specific to each country. In order to filter the postal codes that do not match the defined patterns, I reported these patterns in a CSV file into regex formats and used this file to filter the postal codes that do not match the patterns. This has been useful to detect and remove the "CEDEX" postal codes in France as well as the DOM/TOM territories. This first filter step allowed to remove some features, from 1,264,592 postal code features to 1,249,933 filtered ones.
Without loss of generality, the goal is to match the postal codes features with a single GeoNames feature. Matching the features of both datasets is made challenging because no common key is shared between the two datasets. The fields shared between the two datasets such as the name, country codes, administrative codes, and coordinates cannot be used as keys for the join. In the following, I detail the reasons why these fields cannot be used as keys for an exact match of the two datasets.
Problem with the names. The name given in the postal codes dataset does not necessarily exactly match the name associated to the GeoNames features. For instance, “Trois-Bassins” (-21.1, 55.3) in the postal codes dataset matches to the GeoNames feature “Les Trois-Bassins” (-21.1, 55.3).
Problem with the administrative codes. Features in both datasets are associated to several hierarchical administrative areas of varying sizes. For instance, Paris 08 (75008) is in the country France of code FR, the first-level administrative area 11 (Île-de-France), the second-level administrative area 75 (Paris), and the third-level administrative area 751 (Paris). However, while the administrative codes given in both datasets may match for certain countries such as France, they do not necessarily match for other countries such as Mexico, see for instance this instance for Tampico, Mexico.
Postal Codes dataset.
+---+---+---+--------------+-------+--------+-----+
|AC1|AC2|AC3| NAME| LAT| LON| PC|
+---+---+---+--------------+-------+--------+-----+
|TAM|038| 10| Tampico|22.2553|-97.8686|89137|
|TAM|038| 10|Ignacio Romero|22.2553|-97.8686|89137|
+---+---+---+--------------+-------+--------+-----+
GeoNames dataset.
+---+---+----+-------+--------+--------+-------+
|AC1|AC2| AC3| NAME| LAT| LON| GNID|
+---+---+----+-------+--------+--------+-------+
| 28|038|null|Tampico|22.24484|-97.8352|3516355|
+---+---+----+-------+--------+--------+-------+
Problem with the coordinates. For instance, the coordinates associated with “Saint-Denis” (-20.8823, 55.4504) in the postal codes dataset do not exactly match those associated with the GeoNames feature “Saint-Denis” (-20.88231, 55.4504). While they are very close, they do not match, making the exact coordinate matching challenging.
Proposed solution: Loose coordinate matching. Each feature in both datasets is associated to coordinates that consist of a longitude and a latitude given in the WGS84 coordinate system. The coordinates are more or less precise depending on the feature. The precision of the coordinates is given by the number of decimal places given in the latitude and longitude float number. According to this Wikipedia page, the physical length that can be measured depends on the precision of the coordinates as per the number of decimal places. As such, a precision of one decimal place corresponds to a length of 7.871 kilometers at 45 degrees N/S (this does depend on the latitude). Therefore, comparing coordinates at this precision level would be precise enough to absorb the difference between the coordinates in both datasets, while avoiding overlap on multiple cities. As an illustration, I represent the area covered by the different coordinate precision as a function of the decimal place.

Reducing the GeoNames features using string similarity. I join the two GeoNames and Postal Codes datasets based on the coordinates of the features using a precision of one decimal place. When aggregating on the postal code name, for a given postal code there are multiple GeoNames features that match (all the GeoNames cities that are within range of the coordinate precision). I further need to aggregate the resulting dataset by reducing the GeoNames feature to select the one that best matches the postal code feature. I match the two features based on their name. As I have discussed above the names loosely match one another, as such I perform a string match based on the cosine distance of the two name strings. In particular, it removes the special characters, tokenizes the string into words, and then compares the words shared between two strings. If the distance between the name in the GeoNames dataset and the one in the Postal Codes dataset is more than 20%, the two names will be matched.
Finally, the other features of the GeoNames dataset (population and alternative names) are joined to the aggregated and reduced dataset using the GeoNames identifier.
In the final phase of this project, I used the Python API developed by Algolia to send the data I processed for each country in batch mode.
Ranking the search results. I used the ranking options offered by Algolia through their dashboard to rank the different cities using the default ranking as well as their population and geographic coordinates. The searchable attributes are the folowing:
- The name of the city,
- The set of alternative names of the city,
- The third-level administrative area of the city,
- The second-level administrative area of the city,
- The first-level administrative area of the city,
- The set of postal codes of the city.
According to the documentation, the ranking will include the features that are near a point of reference.
The ranking formula contains a Geo criterion which by default is the second ranking criteria in the formula. This criterion is only effective when records contain the
_geolocattribute with the corresponding lat and lng properties. Results will be ranked by distance, from the closest to the farthest based on a point of reference.
In the web client, when a user starts to type the name of a city, I perform two simultaneous searches :
- The two first autocomplete results are local using Algolia's geo search around the location given by the current view of the map behind the search box, using the
aroundLatLngsearch attribute. The results of the search will then be local to the location of current map view. The local search results adapt with the current map view, whether the user selects a place or pans the map. - The three last autocomplete results are global using standard search with the ranking based on the decreasing population of the matching cities. Among these results, I filter those are already returned by the first local search query.
The two searches are performed simultaneously by Javascript client with different search arguments. The user can then select a place and the map behind the search box will move to the selected city.
I list here the different points to extend and improve the current proposed solution for this project.
Alternative names. As I have discussed above, I chose not to use the alternateNamesV2 dataset and instead use the alternatenames field in the GeoNames dataset. As an extension, I could use the alternateNamesV2 dataset by joining the GeoNames dataset on the geonameid field.
Scalability of the data processing pipeline. I used Apache Spark, an industry-standard distributed data processing system that leverages the compute power of multiple nodes (CPU cores and/or hosts) to implement the pipeline and process the GeoNames datasets. Apache Spark is scalable as it allows to add more worker (executors) nodes to increase the level of parallelism of the pipeline. I decided to split the dataset by country codes and processed each country separately in order to reduce the size of the joined dataset and avoid OutOfMemory errors or errors specific to certain countries. This division of the dataset further allows to process each dataset independently and increases the level of parallelism. In the proposed solution I used a for loop to process the different countries but this part of the code can be easily parallelizable. Joining the two datasets on the coordinates of the features can produce a lot of non-necessary overhead for dense places and utilize large computing resources for the aggregation step (with the cosine distance computation). Therefore, I could envisage an adaptive threshold based for instance on the accuracy field in the Postal Codes dataset. This would reduce the number of GeoNames features associated to a Postal Codes feature.
Accuracy of the proposed solution. It is difficult to assess the accuracy of the postal code and GeoNames datasets matching. One way to conduct an evaluation is to use Mechanical Turkers for quality assessment over different parts of the world, or crowdsourced bug reporting in the data. Another way to test the produced dataset would be to compare it against other services that also leverage GeoNames such as Algolia Places and Mapbox but also other services such as Google Maps and Here.
Moreover, the population is null for some cities (for instance Lyon, see below), which results in improper rankings. One way to fix this would to check the produced dataset against null populations and replace them using population data from Wikipedia for instance.
Recall that the best matching GeoNames feature name with the Postal Codes feature is determined using the cosine distance between the two name strings. I chose to use this distance metric because it only considers non-zero dimensions and therefore performs well with sparse vectors (in our case, the sparse vectors contain the number of words in the names of the cities that are compared). In particular, I chose to tokenize the words in the city names because I assumed that similar city names will share the same words in the same language and there is little chance to have typos or different spellings across the two datasets. If this assumption does not hold, another way to carry out the comparison would be to consider the n-grams (e.g., bigrams) composed of n characters shared between the two strings instead of the words themselves. Alternatively one can consider another metric, such as the Levenshtein distance that compares the edit distance between two strings in terms of insertion, deletion, and substitutions. The different metrics can then be compared against one another according to the accuracy of the resulting aggregation.
Some places in the produced dataset are redundant (they share the same name or same geonameid field) and require futher filtering based on the names and geonameid of the produced dataset. The names that are shown in the autocomplete are the names of the Postal Codes dataset, which are sometimes different from the names in the GeoNames dataset as well as the alternative names. As such, it is challenging to determine the best name for a city. Some cities like Paris have many districts (e.g., Paris 08) that are returned by the autocomplete but are less relevant than the city itself. The challenge is to determine the hierarchy between the city and its districts, possibly using the lowest administrative code and weighing the city more in the search rankings.
Caveats of the current solution. The proposed solution is not perfect. Indeed, some countries require further investigation. Because of the short timeline of this project, the following country codes have been omitted from the final dataset: LT, RO, PL, LI, JP. After some initial investigation, the processing of these countries produces some errors that are probably due to the use of special characters in the names of the cities. Cities of the countries that were not present in the Postal Codes dataset.
The cities produced in the dataset are only those present in the Postal Codes dataset and thus those that are present in the GeoNames dataset but not present in the Postal Codes dataset were not processed and added to the final dataset. Adding them would necessitate to adapt the last join in the third stage of the pipeline to include the cities of the GeoNames dataset that were not processed in the join of the second stage.
After assessing the correctness of the produced dataset, it appeared that the Arrondissements in Lyon have a population of 0 inhabitants, as such, the population fields have been modified with the latest population estimate (484,344 inhabitants as of 2010).
The city of Porto has a lot of postal codes associated to it: https://worldpostalcode.com/portugal/porto/. As such, the whole record does not fit as an Algolia index, so I had to limit the number of postal codes to 200, randomly chosen.