本文将从系统架构、事务背书的基本工作流程、背书策略、有效账本和PeerLedger裁剪技术这四方面对fabric进行介绍,主要参考官方文档。
fabric是区块链技术的实现,目标是成为开发区块链应用和解决方案的基础,更多详细信息请参考文档。
Fabric架构具有以下优点:
-
链代码信任灵活性. 该结构将链代码(区块链应用)的信任假设从排序服务的信任假定分离出来。换句话说,订购服务可以由一组节点(orderers)提供,并且允许其中一节节点失败或行为异常,并且对于每个链代码,背书者可能是不同的。这意味着就算是有部分节点数据被篡改,系统仍然可以正常工作,并且能够控制不同链代码对账本数据具有不同的可见性。
-
可扩展性. 由于负责特定链代码的背书节点与排序节点分离,相比通过相同节点完成这些功能,系统能够更容易扩展。具体而言,当不同的链代码指定不相交的背书节点时,能够使得背书节点之间的链代码能够区分开并且并行的执行(背书)。此外,链代码的执行有可能非常耗时,将链代码的执行从排序服务的关键路径分离出来,可以避免阻塞整个系统。
-
保密性. 该架构便于部署具有关于其事务的内容和状态更新的机密性要求的链代码。
-
共识模块化. 该架构是模块化的,并且允许不同的共识算法(ordering service能够支持Raft、PBFT等共识算法)以插件形式添加到架构中。如果存在作恶节点即存在拜占庭问题,选用PBFT,一般情况下只有错误节点而没有作恶节点,那么Paxos、Raft等共识算法都能满足需求。
PS:系统架构、事务背书的基本工作流程、背书策略 是Hyperledger Fabric v1版本的内容,有效账本和PeerLedger裁剪技术是post-v1版本的内容。
区块链是由多个彼此通信的节点组成的分布式系统。区块链运行的程序称为chaincode(链代码),保存状态和账本数据,并执行事务。链代码是链式代码调用事务操作的核心元素。所有事务必须得到“背书”,只有已经背书的事务被认可并对节点状态产生作用。存在一个或多个特殊的链代码,这些链代码能够对一般的链代码的函数和参数进行管理,这些特殊的链代码统称为*系统链代码*。
具有两种类型的事务:
-
部署事务 负责创建新的链代码并把程序作为输入参数。当部署事务成功执行时,链代码已经安装在区块链上。
-
调用事务 调用事务在先前部署的链代码的上下文中执行。调用事务是指链代码及其提供的功能之一。链代码执行成功后会执行指定的函数-这可能涉及修改相应的状态,并返回一个输出。
如后面所述,部署事务是特殊的调用事务,其中负责创建链代码的部署事务对应于系统链代码的调用事务。也就是说,不管是部署事务还是调用事务,其实都可看作调用事务。
备注: 这篇文档目前假设一个事务或者创建新的链代码或者调用已经部署的链代码。本文档尚未描述:
a)针对查询(只读)事务的优化(包含在v1版本);
b)对交叉链代码事务的支持(post-v1特性)。
区块链的最新状态(或简称为状态)被模拟为版本化的键/值存储(KVS),其中key是字符串类型表示名字,values可以是任意类型的二进制数据。这些键值对通过运行在区块链上的链代码(区块链应用)的Put和Get这两种操作来进行读写。状态被持久地存储并且记录状态的更新。请注意,采用版本化的KVS作为状态模型,在实现时可以使用实际的KVS系统,或者使用关系型数据库RDBMS或任何其他方案。
形式化表示,状态s表示成映射K -> (V X N),其中:
k是一组键v是一组值N是一个无限的有序版本号。内射函数next: N -> N把N的一个元素当作输入,并返回下一个版本号。
当N为最小的版本号是,V和N都包含一个特殊元素\bot。在最开始时,所有的值都被映射成(\bot,\bot)。对于s(k)=(v,ver),使用s(k).value来表示v,使用s(k).version来表示ver。
KVS操作可以使用下面的形式化表示:
put(k,v),对于每个在键集合K的键kk in K和每个在值集合Valu的值vv in V,记区块链状态s,改变后的状态为s'。如果k'!=k,有s'(k)=(v,next(s(k).version));而当k'=k时,有s'(k')=s(k')。就是说,put(k,v)操作只同时改变键k的值和版本,而不改变其他键的值,但是其他键的版本号需要修改为下个版本号。get(k)返回s(k)。
状态由peers节点来维护,而不是由orderer节点或者client端来维护。因为client只负责发起事务请求,而orderer只负责事务的排序、分发。
状态分区. KVS中的key可以从它们的名字中被识别为属于特定的链代码,这也意味着只有某个链代码的事务才能修改属于这个链代码的键值对。原则上,任何链代码都能读取属于其他链代码的键值对。而支持跨链代码事务,修改属于两个或者多个链代码的状态是post-v1版本新增的特性。
账本提供了一个在系统运行过程中发生的所有成功状态变化(这里称作有效事务)和不成功的尝试改变状态(这里称作无效事务)的可验证历史,就是一切操作皆可溯源。
账本由排序服务(参见1.3.3节)构建的,以(有效或无效)事务块的完全有序的哈希链存在。哈希链会强制约束账本中的区块顺序,并且每个区块会包含一组完全有序的事务。这就强制约束着整个账本里面的所有事务的顺序。因此账本、区块、事务间的关系可以用图1所示:

账本保存在所有peer节点中,并可选地,保存在一个orderer节点子集中。在orderer上下文中,我们把OrdererLedger称为账本,而在peer上下文中,我们把PeerLedger称为账本。PeerLedger与OrdererLedger的不同之处在于,peer节点会在本地维护一个比特位掩码,这个比特位掩码用于区分有效事务和无效事务。(更多细节参见2.4节)
Peer节点可能会对PeerLedger进行裁剪,如[第4章]所描述(post-v1版本特性)。Orderer节点维护OrdererLedger以保证PeerLedger的容错性和可用性,在ordering service的属性(参见1.3.3节)能够保持成立的情况下,Orderer节点将可能在任何时候裁剪OrdererLedger。ordering service需要保持的属性分别为safety(一致性保证)和liveness(活性保证),事实上这两个属性也是构建分布式系统的基础属性。safety保证所有事务操作结果是对的,无歧义的,不会出现错误情况;而liveness保证所有peer最后都能收到ordering service提交的事务。
Peer节点通过账本能够回放所有事务的发生历史,通过回放事务可以重新构建区块链的最新状态。因此,1.2.1节所描述的状态,是一种可选的数据结构,但是如果Peer节点能维护状态,那么就不用每次都回放所有历史事务,也能够得到区块链的最新状态。
节点是区块链的通信实体。一个“节点”只是一个逻辑上的概念,事实上不同类型的节点可以运行在同一个虚拟机或者物理机上。重要的是节点如何分组在“信任域”中,并与控制它们的逻辑实体相关联。fabric使用PKI公钥基础设施来控制节点、客户端对不同账本所拥有的权限以及加密节点间通讯信息,以此来保证区块链数据的安全、可靠性。
fabric有以下三种类型的节点:
- 客户端或提交客户端:客户端能够把一个实际的事务调用请求发送到背书节点,并且能够把事务提案通过广播发送到排序服务。
- Peer:Peer节点能够提交一个事务并维护状态和一份账本副本(请见1.2节)。另外,peer节点有可能也是背书节点。
- Orderer或排序服务节点:运行通讯服务的节点,保证事务的分发,比如原子广播或者全部顺序的广播。
下面将更详细地解析节点的类型。
客户端表示最终用户的实体,比如对账本的读写,首先由客户端发起请求,虽然peer才是最终对账本实现读写的节点,但peer自身不会主动发起,只有客户端是事务发起实体。它必须连接到peer节点与区块链进行通讯。客户端可以连接到其选择的任何peer节点,客户端创建并因此能够调用事务。
如第2部分所述,客户端与peer节点和orderer节点进行通讯。
peer节点从排序服务中以块的形式接收有序的状态更新并维护状态和账本信息。
peer节点还会充当起背书节点。背书节点的特殊功能是针对特定的链代码进行的,并且在事务提交之前进行背书。每个链代码可以指定一个背书策略,这个背书策略可能涉及到一组背书节点。该策略定义了有效事务背书(通常是一组背书节点的签名)的充分必要条件,如后面的第2和第3部分描述。在部署事务额度特殊情况下,安装链代码的(部署)背书策略是指定系统链代码的背书策略。因为部署(安装)链代码是一种特殊的系统链代码调用事务。
fabric通过排序节点提供事务排序服务,能够保证事务分发可靠性的通讯服务。事务排序服务可以以不同的方式实现:从中心化服务(例如在开发和测试中)到针对不同网络和节点故障模型的分布式协议。
排序服务为客户端和peer节点提供共享的通信channel,为包含事务的消息提供广播服务。客户端连接到channel并且可能通过channel广播消息,然后这些消息会被分发到peer节点。channel能够支持所有消息的原子交付,即全部顺序的交付和(实现特定)可靠性的消息通信。换句话说,channel向所有连接的peer节点输出相同的消息,并以相同的逻辑顺序输出到所有连接的peer节点。这种原子通信保证也被称为toral-order broadcast、atomic broadcast,在分布式系统中也被称为consensus(共识)。传达的消息是包含在区块链状态中的候选事务。
分区(排序服务channel).排序服务可以支持与发布/订阅(pub/sub)消息传递系统的topic类似的多个channel。客户端可以连接到特定的channel,然后可以发送消息和获取到达的消息。channel可以被认为是分区,连接到某个channel的客户端是不感知其他channel的存在的,但是客户端可能连接到多个channel。尽管Hyperledger Fabric中包含的一些排序服务实现支持多个channel,但为了简化表示,在文档的其余部分,我们假设排序服务由单个channel/topic组成。
排序服务API.peer节点通过排序服务提供的接口连接到提供排序服务的channel。排序服务API由两种操作组成(更广泛地说是两种异步事件)。
TODO补充用于获取客户端/peer制定序列号下特定的区块API介绍。
broadcast(blob):客户端调用这个接口能够在channel中广播任意消息blob。在向服务发送请求时,这在BFT(拜占庭)系统中也叫做request(blob)。deliver(seqno,prevhash,blob):排序服务通过在peer节点上调用这个接口来分发消息blob,消息都会有一个非负整数序列号seqno,以及前一个区块的hash值(prevhash)。换句话说,这是来自ordering服务的输出。deliver()在pub-sub系统中有时候被称为notify(),在BFT系统中被称为commit()。
下面将结合fabric的源码来进一步描述broadcast以及deliver这两个用于保证共识的关键API。因为区块链的最大贡献是价值共识,价值共识的核心是共识算法。而共识算法的实现细节都体现在这两个API里面,所以对这两个API深入分析,有助于理解fabric系统的架构。
在分析源码前,先介绍fabric的典型事务处理过程,如图2所示,下图参考极客头条:
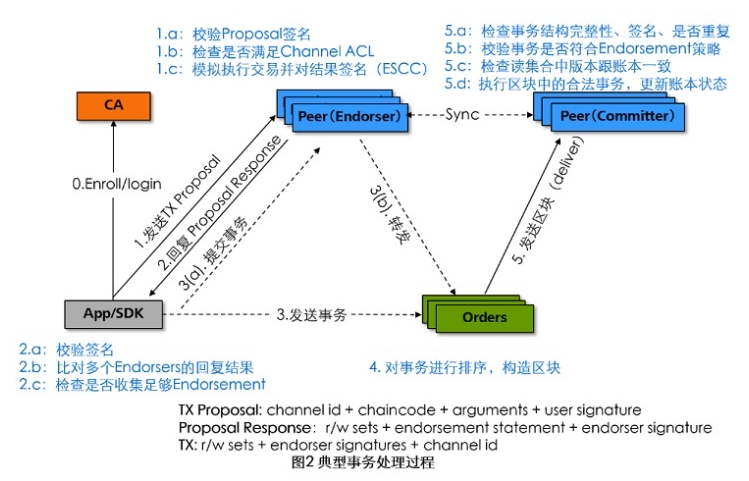
-
客户端(APP/SDK):客户端应用使用SDK来跟fabric网络打交道。首先,客户端从CA获取合法的身份证书来加入网络内的应用。发起正式事务前,需要先构造事务提案(Proposal)提交给Endorser进行背书;客户端收集到足够(背书策略决定)的背书支持后可以利用背书构造一个合法的事务请求,发送给orderer进行排序处理。
-
背书节点(Endorser):主要完成对事务提案的背书(目前主要是签名)处理。收到来自客户端的事务提案后,首先进行合法性和ACL权限检查,检查通过后模拟执行事务,对事务导致的状态变化(以读写集形式记录,包括读状态的键和版本,写状态的键值)进行背书并返回结果给客户端段。注意网络中只有部分节点担任Endorser角色。
-
Committer节点:负责维护区块链和账本结构(包括状态DB、历史DB、索引DB等)。该节点回定期地从orderer获取排序后的批量事务区块结构,对这些交易进行持久化存储前进行最终检查。(包括交易消息结构、签名完整性、是否重复、读写集合版本是否匹配等)。检查通过后执行合法的事务,将结果写入账本,同时构造新的区块,更新区块中BlockMetadata[2](TRANSACTIONS_FILTER)记录事务是否合法等信息。同一个物理节点可以仅作为Committer角色运行,也可以同时担任Endorser和Committer这两种角色。
-
ordere节点:仅负责排序。为网络中所有合法事务进行全局排序,并将一批排序后的事务组合生成区块结构,orderer一般不直接读写账本和执行具体事务。
-
CA:负责网络中所有证书的管理(分发、撤销等),实现标准的PKI架构。CA在签发证书后,自身也不参与到网络中的事务过程。
fabric网络里节点都是通过gRPC来实现通信的,所以从gRPC入口分析broadcast和deliver。这两个接口定义在hyperledger/fabric/protos/orderer/ab.proto的AtomicBroadcast服务里。
service AtomicBroadcast {
// broadcast receives a reply of Acknowledgement for each common.Envelope in order, indicating success or type of failure
rpc Broadcast(stream common.Envelope) returns (stream BroadcastResponse) {}
// deliver first requires an Envelope of type DELIVER_SEEK_INFO with Payload data as a mashaled SeekInfo message, then a stream of block replies is received.
rpc Deliver(stream common.Envelope) returns (stream DeliverResponse) {}
}从上面的proto可以发现Broadcast、Deliver都是双向流式RPC接口,客户端在调用Broadcast接口时是不断地发送请求Envelope,服务端也会对每个请求Envelope进行处理并返回BroadcastResponse,每发送一个Envelope就会收到一个BroadcastResponse。读到这里可能会有疑问,Broadcast、Deliver这两个接口的客户端和服务端分别是什么,Broadcast具体广播什么消息,Deliver具体又是接收什么消息呢?
- 先回答Broadcast的客户端是什么这个问题。通过分析Broadcast的gRPC客户端接口可以发现,广播的接口是在hyperledger/fabric/peer/common/ordererclient.go里面定义的,从代码所在路径就大致才到Broadcast的客户端就是peer节点,另外从代码注释和文件名同样可以猜测到Broadcast的服务端就是orderer节点。
type BroadcastClient interface {
//Send data to orderer
Send(env *cb.Envelope) error
Close() error
}继续分析BroadcastClient接口的Send方法的调用的地方有这么几处:调用链代码ChaincodeInvokeOrQuery,发起创建channel事务sendCreateChainTransaction、初始化链代码IsccInstantiate、更新链代码chaincodeUpgrade、发起更新channel事务update。这些调用方都是peer节点,所以可以确认Broadcast的客户端就是peer节点。需要注意的是初始化、调用、更新链代码,或者是创建、更新channel,这些请求都是由用户APP/SDK发起的,peer不会主动发起。但实际中App/SDK不会向orderer直接发送请求,如图2第3步所示,APP/SDK会向peer节点发送请求,再由peer节点进行转发调用orderer的Broadcast接口,向所有orderer节点广播消息。

到这里,Broadcast具体是广播什么消息这个问题也就显而易见,就是广播调用初始化、调用、更新链代码,创建、更新channel这些消息(Envelope),当然这些信息都是经过peer签名的。如hyperledger/fabirc/peer/channel/create.go的创建channel方法第159行,通过校验后进行签名再进行广播(170行)。通过进一步分析Envelope的proto文件hyperledger/fabric/protos/common/common.proto,广播消息的详细内容如图4所示。

在广播消息中引入头部Header是为了防范重放攻击,并且头部可以作为签名数据的身份信息。字段信息如下:
- type: 头部类型,proto文件并没有详细说明,分析代码hyperledger/fabric/protos/common/common.pb.go,可以知道一共有8种类型消息,每种类型的消息处理方式不一样。比如CONFIG_UPDATE,表示这是一个更新配置的信息,那么广播消息的data就是ConfigUpdateEnvelope配置增量的序列化数据(hyperledger/fabric/peer/channel/create.go sanityCheckAndSignConfigTx);

- version: 用于制定消息协议版本;
- timestamp: 发送者创建消息的时间;
- channel_id: 消息所属的channel,这就意味着广播只是特定channel的广播;
- tx_id: 端到端唯一的事务id,通常由用户或SDK生成,背书节点会对事务id进行唯一性检查,peer节点也会执行检查,最后写入账本;
- epoch: 头部创建时间,基于区块高度来定义。这个时间用于表示某个逻辑发生的时间段,类似于raft的term的概念。peer要接受proposal时,epoch需要满足两个条件: 1.peer当前epoch与收到的消息的epoch要相等 2.收到的消息在当前epoch时间段内只出现过一次(不能重复);
- extension: 扩展字段;
- tls_cert_hash: 客户端TLS证书的hash值;
- creator: 消息的创建者,为msp.SerializedIdentity的序列化数据;
- nonce: 随机数,用于检测是否存在重放攻击;
- data: 在说明type时候已经描述过,data存放的数据依赖于消息类型;
- signature: 签名,用于校验消息是否被篡改。
分析完Broadcast的客户端接口和广播消息,接下来就需要分析Broadcast的服务端接口,orderer节点如何处理接收到的广播消息。目前fabric的peer节点还没实现或支持BroadcastServer,而orderer节点的BroadcastServer的代码在hyperledger/fabric/orderer/common/broadcast/broadcast.go的func (bh *handlerImpl) Handle(srv ab.AtomicBroadcast_BroadcastServer) error方法里。
// Handle starts a service thread for a given gRPC connection and services the broadcast connection
func (bh *handlerImpl) Handle(srv ab.AtomicBroadcast_BroadcastServer) error {
addr := util.ExtractRemoteAddress(srv.Context())
logger.Debugf("Starting new broadcast loop for %s", addr)
for {
msg, err := srv.Recv() // 典型的双向流式gRPC处理流程,接收一个消息处理一个消息
if err == io.EOF { // 本次连接的消息已经接收完毕,处理流程结束
logger.Debugf("Received EOF from %s, hangup", addr)
return nil
}
if err != nil {
logger.Warningf("Error reading from %s: %s", addr, err)
return err
}
chdr, isConfig, processor, err := bh.sm.BroadcastChannelSupport(msg) // 从消息中提取Channel header,判断是否为更新配置消息,processor为专门用于处理指定channel的处理器(类型为ChainSupport)
if err != nil {
logger.Warningf("[channel: %s] Could not get message processor for serving %s: %s", chdr.ChannelId, addr, err)
return srv.Send(&ab.BroadcastResponse{Status: cb.Status_INTERNAL_SERVER_ERROR, Info: err.Error()})
}
if err = processor.WaitReady(); err != nil { // 阻塞当前goroutine,直到processor能够处理新的,这是为了保证之前的消息被完全处理前不被新接收的消息影响
logger.Warningf("[channel: %s] Rejecting broadcast of message from %s with SERVICE_UNAVAILABLE: rejected by Consenter: %s", chdr.ChannelId, addr, err)
return srv.Send(&ab.BroadcastResponse{Status: cb.Status_SERVICE_UNAVAILABLE, Info: err.Error()})
}
if !isConfig { // 不是更新配置消息
logger.Debugf("[channel: %s] Broadcast is processing normal message from %s with txid '%s' of type %s", chdr.ChannelId, addr, chdr.TxId, cb.HeaderType_name[chdr.Type])
configSeq, err := processor.ProcessNormalMsg(msg) // 处理普通消息,如构建genesis block事务、peer加入channel事务,检查当前消息是否合法(如消息长度是否合法、消息是否为空、消息的policy是否合法等),并返回当前配置的序列号
if err != nil {
logger.Warningf("[channel: %s] Rejecting broadcast of normal message from %s because of error: %s", chdr.ChannelId, addr, err)
return srv.Send(&ab.BroadcastResponse{Status: ClassifyError(err), Info: err.Error()})
}
err = processor.Order(msg, configSeq) // 对消息进行排序、打包为区块,然后把区块写入到账本。fabric架构有3种不同的order模式,分别为solo、kafka、sbft这3种模式,不同的模式对消息的处理会不同。比如solo、kafka这两种模式会对消息按顺序组织成消息流、再对消息流切割为区块,最后把区块写入到账本;而sbft模式会把消息组织成块,再对块进行排序,最后写入到账本。
if err != nil {
logger.Warningf("[channel: %s] Rejecting broadcast of normal message from %s with SERVICE_UNAVAILABLE: rejected by Order: %s", chdr.ChannelId, addr, err)
return srv.Send(&ab.BroadcastResponse{Status: cb.Status_SERVICE_UNAVAILABLE, Info: err.Error()})
}
} else { // isConfig
logger.Debugf("[channel: %s] Broadcast is processing config update message from %s", chdr.ChannelId, addr)
config, configSeq, err := processor.ProcessConfigUpdateMsg(msg)
if err != nil {
logger.Warningf("[channel: %s] Rejecting broadcast of config message from %s because of error: %s", chdr.ChannelId, addr, err)
return srv.Send(&ab.BroadcastResponse{Status: ClassifyError(err), Info: err.Error()})
}
err = processor.Configure(config, configSeq)
if err != nil {
logger.Warningf("[channel: %s] Rejecting broadcast of config message from %s with SERVICE_UNAVAILABLE: rejected by Configure: %s", chdr.ChannelId, addr, err)
return srv.Send(&ab.BroadcastResponse{Status: cb.Status_SERVICE_UNAVAILABLE, Info: err.Error()})
}
}
logger.Debugf("[channel: %s] Broadcast has successfully enqueued message of type %s from %s", chdr.ChannelId, cb.HeaderType_name[chdr.Type], addr)
err = srv.Send(&ab.BroadcastResponse{Status: cb.Status_SUCCESS})
if err != nil {
logger.Warningf("[channel: %s] Error sending to %s: %s", chdr.ChannelId, addr, err)
return err
}
}
}solo和kafka两种模式的order过程可参考知乎文章,对应的时序分别如图7、8所示。


- 至此,前面提到的与Broadcast接口相关的问题都通过分析得到答案,但是Broadcast接口最后的处理流程只是把事务写入到账本,
Deliver接口跟Broadcast什么关系?它的客户端、服务端又是什么?这个接口具体要完成什么功能?带着这些疑问,继续分析Deliver接口的源码,毕竟只看说明文档会忽略掉很多细节,导致理解不全面。
fabric对Deliver的gRPC的接口进行了封装,代码在hyperledger/fabric/core/deliverservice/blocksprovider/blocksprovider.go
// BlocksDeliverer defines interface which actually helps
// to abstract the AtomicBroadcast_DeliverClient with only
// required method for blocks provider.
// This also decouples the production implementation of the gRPC stream
// from the code in order for the code to be more modular and testable.
type BlocksDeliverer interface {
// Recv retrieves a response from the ordering service
Recv() (*orderer.DeliverResponse, error)
// Send sends an envelope to the ordering service
Send(*common.Envelope) error
}Send方法的最终调用方有两处,一处是hyperledger/fabric/core/chaincode/shim/chaincode.go的chatWithPeer,一处是hyperledger/peer/node/start.go的nodeStartCmd命令。其中第一处是客户端在调用链代码时,链代码需要与peer通信。链代码在状态变化过程中(处理事务前)需要回调peer来更新账本信息。而第二处是peer节点在启动中,通过gossip协议从peer所加入的channel里面获取区块信息。所以两处的最终调用方可归结为一处,deliver接口的客户端就是peer节点。
- 从BlocksDeliverer的Send接口也可以看出deliver的内容与广播接口Broadcast一样,如图4所示。前面在介绍图4广播消息的结构的时候,已经提到过如果消息Header的type不一样,那么消息的data携带的信息也就不一样。而deliver client所发送的消息Header的类型都是HeaderType_CONFIG_UPDATE,data为seekInfo,如下面代码所示:
func (b *blocksRequester) seekOldest() error {
seekInfo := &orderer.SeekInfo{
Start: &orderer.SeekPosition{Type: &orderer.SeekPosition_Oldest{Oldest: &orderer.SeekOldest{}}},
Stop: &orderer.SeekPosition{Type: &orderer.SeekPosition_Specified{Specified: &orderer.SeekSpecified{Number: math.MaxUint64}}},
Behavior: orderer.SeekInfo_BLOCK_UNTIL_READY,
}
//TODO- epoch and msgVersion may need to be obtained for nowfollowing usage in orderer/configupdate/configupdate.go
msgVersion := int32(0)
epoch := uint64(0)
// 消息类型为HeaderType_CONFIG_UPDATE,data为seekInfo
env, err := utils.CreateSignedEnvelope(common.HeaderType_CONFIG_UPDATE, b.chainID, localmsp.NewSigner(), seekInfo, msgVersion, epoch)
if err != nil {
return err
}
return b.client.Send(env) // deliver客户端发送消息
}
func (b *blocksRequester) seekLatestFromCommitter(height uint64) error {
seekInfo := &orderer.SeekInfo{
Start: &orderer.SeekPosition{Type: &orderer.SeekPosition_Specified{Specified: &orderer.SeekSpecified{Number: height}}},
Stop: &orderer.SeekPosition{Type: &orderer.SeekPosition_Specified{Specified: &orderer.SeekSpecified{Number: math.MaxUint64}}},
Behavior: orderer.SeekInfo_BLOCK_UNTIL_READY,
}
//TODO- epoch and msgVersion may need to be obtained for nowfollowing usage in orderer/configupdate/configupdate.go
msgVersion := int32(0)
epoch := uint64(0)
// 消息类型为HeaderType_CONFIG_UPDATE,data为seekInfo
env, err := utils.CreateSignedEnvelope(common.HeaderType_CONFIG_UPDATE, b.chainID, localmsp.NewSigner(), seekInfo, msgVersion, epoch)
if err != nil {
return err
}
return b.client.Send(env) // deliver客户端发送消息
}seekInfo有3个字段,分别为Start、Stop、Behavior,Start、Stop表示起始区块高度、结束区块高度,Behavior表示直到区块状态ready为止。接着分析deliver客户端接口返回的内容是什么以及peer是怎么处理deliver接口返回的内容,代码在hyperledger/fabric/coredeliverservice/blocksprovider/blocksprovider.go的DeliverBlocks方法里。由于篇幅有限,代码就不贴了,读者可仔细分析。返回内容就是最开始的gRPC Deliver接口所定义的DeliverResponse,peer通过gRPC从order节点获取DeliverResponse,当DeliverResponse状态为Succ时,会包含区块数据,peer再把区块数据封装成gossip消息,利用gossip协议把区块数据同步到不同的peer节点,使得peer节点的账本数据保持一致。那么从前面的内容,大致就可以推测出deliver接口的作用就是peer节点从order节点里面获取区块数据,这些区块数据范围在高度Start、Stop,并且状态为ready。当成功返回区块时,peer节点会继续把区块数据同步到各个peer节点。推测仅仅时推测,我们需要从deliver的服务端接口区验证。
- 现在通过分析deliver的服务端接口来解答最后一个疑问和验证我们的推测是正确的。
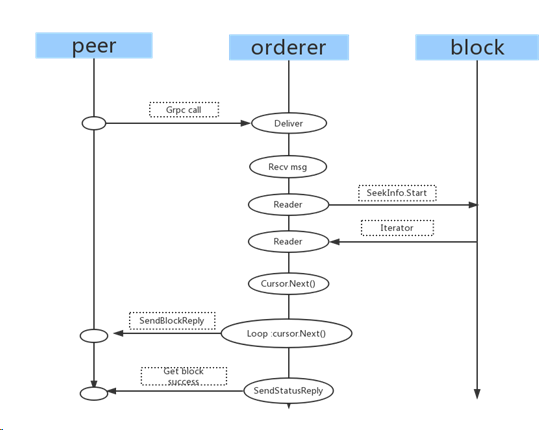
Deliver的gRPC服务端接口代码在hyperledger/fabric/common/deliver/deliver.go的deliverBlocks方法里,这里的逻辑比较复杂并且限于篇幅,只能分析核心逻辑。希望读者能进行详尽的分析,并且经过自己的分析,理解会更深刻些:) deliverBlocks的核心逻辑如下:
func (ds *deliverServer) deliverBlocks(srv ab.AtomicBroadcast_DeliverServer, envelope *cb.Envelope) error {
// ...
for {
if seekInfo.Behavior == ab.SeekInfo_FAIL_IF_NOT_READY {
if number > chain.Reader().Height()-1 {
return sendStatusReply(srv, cb.Status_NOT_FOUND)
}
}
// seekInfo.Behavior为ready
block, status := nextBlock(cursor, erroredChan) // 获取下一个区块数据,准备发送
if status != cb.Status_SUCCESS {
cursor.Close()
logger.Errorf("[channel: %s] Error reading from channel, cause was: %v", chdr.ChannelId, status)
return sendStatusReply(srv, status)
}
// increment block number to support FAIL_IF_NOT_READY deliver behavior
number++ // 增加区块
currentConfigSequence := chain.Sequence()
if currentConfigSequence > lastConfigSequence {
lastConfigSequence = currentConfigSequence
if err := sf.Apply(envelope); err != nil {
logger.Warningf("[channel: %s] Client authorization revoked for deliver request from %s: %s", chdr.ChannelId, addr, err)
return sendStatusReply(srv, cb.Status_FORBIDDEN)
}
}
logger.Debugf("[channel: %s] Delivering block for (%p) for %s", chdr.ChannelId, seekInfo, addr)
if err := sendBlockReply(srv, block); err != nil { // 通过gRPC,向peer节点返回DeliverResponse
logger.Warningf("[channel: %s] Error sending to %s: %s", chdr.ChannelId, addr, err)
return err
}
if stopNum == block.Header.Number {
break // 直到当前区块的高度等于stopNum为止
}
}
// ...
}上述代码的的时序图如图9所示,参考知乎文章。
{kind=link}

到这里,ordering service的相关接口已经介绍完毕。
账本(请参见1.2.2节)包含ordering service输出的所有数据。简而言之,它是一系列deliver(seqno, prevhash, blob)事件,根据之前描述的prevhash的计算形成一个哈希链。
大多数情况下,出于效率的原因,ordering service不会输出单个事务(blob),而是在单个delvier事件对blob进行分组(按批处理),组织成区块作为输出。在这种情况下,ordering service必须对每个区块的blob按一个确定的序列进行排序。一个区块的blob数量是在实现ordering service的时候动态选择的,数量并不固定。
在下面,为了便于表述,假设每个deliver事件只包含一个blob。我们将定义ordering service属性(本小节其余部分),并解析事务的(背书流程)。假设一个区块的deliver事件对应于一个区块内每个blob的单独deliver事件的序列,则根据上面提到的在一个区块内的blob的确定性排序,这些很容易扩展到块。
Ordering service(或原子广播channel)的保证规定了广播消息发生了什么以及与deliver消息之间的关系(之间的关系请参考上面所述)。这些保证如下,事实上这两条属性也是所有分布式系统的基础属性:
1.Safety(安全性或一致性保证):只要peer连接到channel的时间足够长(它们可以断开连接或崩溃,但将重新启动并重新连接),它们将看到相同的一系列delivered(seqno, prevhash, blob)消息。这意味着deliver()事件的输出在所有peer节点上按照相同的顺序发生,并且序列号相同的消息包含相同的内容(blob和prevhash)。注意,这只是一个逻辑顺序,并且在一个peer节点上的deliver(seqno, prevhash, blob)不需要同时在另外一个peer节点上发生。但是只要发生了,deliver事件最终在所有的peer都会产生。换句话说,一条消息给定一个特定的seqno,没有两个正确的peer节点收到的这个消息所包含的内容不一样(blob,prevhash)。此外,除非某些客户端(peer节点)实际调用broadcast(blob)接口,否则不会产生deliver事件,并且每次调用broadcast(blob)只会产生一次deliver事件。
另外,deliver()事件会包含之前deliver()事件(prevhash)中数据的加密散列值。当Ordering service实现原子广播保证时,prevhash是序列号为seqno-1的deliver事件的参数的加密散列值(prevhash==hash(seqno,prevhash,blob))。这将在deliver()事件之间建立一个哈希链,用于帮助验证Ordering service输出的完整性,如后面的第4节和第5节所述。特别地,对于第一个deliver()事件来说,它的prevhash有一个默认值。
2.Liveness(交付保证):Ordering service的Liveness保证由Ordering service的实现来保证,确切的保证取决于网络和节点鼓掌模型。
原则上,如果提交的客户端没有失败,那么Ordering service应该保证每个与它连接的正确的peer节点最终deliver到每个提交的事务。
总之,Ordering service确保以下属性,这些属性又是保证整个区块链系统正常运行:
-
Agreement.对于任何两个在正确peer节点上的deliver事件
deliver(seqno,prevhash0,blob0)和deliver(seqno,prevhash1,blob1),如果seqno相等,那么prevhash0==prevhash1并且blob0==blob1。 -
Hashchain integrity.对于任何两个在正确节点上的deliver事件
deliver(seqno-1,prevhash0,blob0)和deliver(seqno,prevhash,blob),prevhash = HASH(seqno01 || prevhash0 || blob0); -
No skipping.如果Ordering service在一个正确的peer节点p上输出
deliver(seqno, prevhash, blob),例如seqno>0,则p已经收到事件deliver(seqno-1,prevhash0,blob0);根据递归定义,p也肯定收到了序列号为1,2,...,seqno-1的所有事件; -
No creation.在一个正确的peer节点上任何
deliver(seqno, prevhash, blob)事件产生前,必须先在一些(可能是不同的)peer节点上产生broadcast(blob)事件; -
No duplication.(可选,但是最好能保证)对于任何两个广播事件
broadcast(blob)和broadcast(blob'),当两个deliver事件deliver(seqno0, prevhash0, blob0)和deliver(seqno1, prevhash1, blob')在blob==blob'时,seqno0==seqno1并且prevhash0==prevhash1。 -
Liveness.如果一个正确的客户端发一起一个广播事件
broadcast(blob),那么每个正确的peer节点“最终”都会向order节点发出一个deliver事件deliver(*,*,blob),其中*表示一个任意值,具体指需要peer根据当前条件决定。