Automatic batching/instancing of draw commands #9685
Conversation
50966c1
to
b45cd5c
Compare
42ffd8d
to
2d5566d
Compare
|
I think this is ready for an initial review pass. If people are on-board with this, then I think the batching can probably be made more generic and reusable and then systems handling batching for both core and custom phases can be added more easily. Perhaps there is also a need to be able to opt-out of automatic batching if that's necessary for people to be able to do completely custom stuff. I think if the entity would just not match the object query, then the prepare systems would skip those entities/phase items. |
|
I just noticed that this breaks |
|
So the reason |
|
I'll probably add some batching tests when I can. |
|
These examples don't appear to be working properly. The rest seem OK. (29b8a29 was tested, all examples, comparing screenshots) |
|
Right, many_foxes should be fixed now. I’ll check the other two. Thanks! EDIT: Fixed. |
crates/bevy_pbr/src/render/mesh.rs
Outdated
| struct BatchState<'mat, 'mesh> { | ||
| meta: BatchMeta<'mat, 'mesh>, | ||
| /// The base index in the object data binding's array | ||
| gpu_array_buffer_index: GpuArrayBufferIndex<MeshUniform>, |
There was a problem hiding this comment.
We may want to consider renaming MeshUniform to ObjectUniform or something.
There was a problem hiding this comment.
Yeah, I want to call it PerObjectData or PerInstanceData. Or that without Per. ObjectUniform is also a decent suggestion. I’ve avoided ‘uniform’ because it feels like it implies the data is stored in a uniform buffer and it may not be.
There was a problem hiding this comment.
Me too. I did have a concern about using the term instance and its clash with instanced rendering. But, I'm coming to think that it isn't a clash. We are using instance indices to look up the per-instance data. That they aren't in an instance-rate vertex buffer (note that being instance-rate is a qualifier to indicate that the data in that vertex buffer is per-instance and is stepped as instances are stepped) doesn't matter.
@cart any opinion on this renaming? Also, what about 2D vs 3D meshes? Per2dInstanceData? PerInstance2dData? PerInstanceData2d? I think I prefer Per2dInstanceData as an initial reaction.
|
I revisited my notes in #89 (comment) and I see that when writing that, I didn't consider significant batching for CPU-driven rendering. I noted two things:
I haven't implemented this. Currently the only way for a Material to have a dynamic offset as part of its binding is if a custom material contains a dynamic offset uniform/storage buffer as one of the material members. I feel like we could live with this and fix it in a separate PR if/when someone notices it is missing. Otherwise there are more gains to be had that benefit more people from focusing on other efforts.
This approach has carried over. The same per-object data would be written multiple times to the I think the best we will be able to do for CPU-driven will practically be reducing bindings so much so that encoding opaque draws is occasionally swapping material bindings and mostly just drawing instances of index/vertex ranges and nothing else. The rest will have to be GPU-driven. |
materials can't currently use dynamic offsets as
it's still an improvement over the current status quo where a binding+draw is issued per mesh per view. |
| if let Some(gpu_mesh) = meshes.into_inner().get(&mesh_handle.0) { | ||
| pass.set_vertex_buffer(0, gpu_mesh.vertex_buffer.slice(..)); | ||
| #[cfg(all(feature = "webgl", target_arch = "wasm32"))] | ||
| pass.set_push_constants( |
There was a problem hiding this comment.
What is the story here for webgl? I thought webgl didn't support push constants (and im guessing wgpu is emulating them somehow with implicit uniforms or something?) What purpose does this serve?
There was a problem hiding this comment.
Could use a comment explaining this
There was a problem hiding this comment.
This is a copy-pasted workaround for how the shader instance index built in is handled in the GL backend. WGSL defines the instance index as the base instance index + the instance being drawn in this sequence. So basically the range we pass to the draw command. But GL doesn't, it is just the instance in the sequence. As such, we work around it by passing a push constant, which is implemented as a glUniform with no buffer. This was the approach I found to work around the shortcoming of the GL backend and its deviation from the semantics of what instance index in WGSL should mean. This should really be fixed in wgpu.
| values.push((entity, MorphIndex { index })); | ||
| // NOTE: Because morph targets require per-morph target texture bindings, they cannot | ||
| // currently be batched. | ||
| values.push((entity, (MorphIndex { index }, NoAutomaticBatching))); |
There was a problem hiding this comment.
Seems like it would be safer to make "no automatic batching" the default and then opt in to automatic batching via a marker type. Is it done in reverse for perf reasons?
There was a problem hiding this comment.
You could say that. I want people to get better performance by default. Why not batch if you can? And then if stuff breaks, opt-out or fix the things needed to get batching working.
There was a problem hiding this comment.
I think "automatic batching" should definitely apply to user facing types for things like PbrBundle, SpriteBundle, etc. But this is a RenderApp component. If someone is building a new rendered entity type with custom rendering logic, idk if we should batch that by default if there are "hidden" data access constraints that we don't check or enforce. Provided adding a AutomaticBatching component doesn't cost us anything significant for things in the hot path, I think it makes sense to opt-in things like sprites, 2d + 3d meshes, etc.
|
Interestingly, now that |
|
@rparrett yeah. That's because it practically has to re-bind the material between every draw as they're no longer in groups. This illustrates the cost of rebinding to update a dynamic offset between draws. |
# Objective - Implement the foundations of automatic batching/instancing of draw commands as the next step from bevyengine#89 - NOTE: More performance improvements will come when more data is managed and bound in ways that do not require rebinding such as mesh, material, and texture data. ## Solution - The core idea for batching of draw commands is to check whether any of the information that has to be passed when encoding a draw command changes between two things that are being drawn according to the sorted render phase order. These should be things like the pipeline, bind groups and their dynamic offsets, index/vertex buffers, and so on. - The following assumptions have been made: - Only entities with prepared assets (pipelines, materials, meshes) are queued to phases - View bindings are constant across a phase for a given draw function as phases are per-view - `batch_and_prepare_render_phase` is the only system that performs this batching and has sole responsibility for preparing the per-object data. As such the mesh binding and dynamic offsets are assumed to only vary as a result of the `batch_and_prepare_render_phase` system, e.g. due to having to split data across separate uniform bindings within the same buffer due to the maximum uniform buffer binding size. - Implement `GpuArrayBuffer` for `Mesh2dUniform` to store Mesh2dUniform in arrays in GPU buffers rather than each one being at a dynamic offset in a uniform buffer. This is the same optimisation that was made for 3D not long ago. - Change batch size for a range in `PhaseItem`, adding API for getting or mutating the range. This is more flexible than a size as the length of the range can be used in place of the size, but the start and end can be otherwise whatever is needed. - Add an optional mesh bind group dynamic offset to `PhaseItem`. This avoids having to do a massive table move just to insert `GpuArrayBufferIndex` components. ## Benchmarks All tests have been run on an M1 Max on AC power. `bevymark` and `many_cubes` were modified to use 1920x1080 with a scale factor of 1. I run a script that runs a separate Tracy capture process, and then runs the bevy example with `--features bevy_ci_testing,trace_tracy` and `CI_TESTING_CONFIG=../benchmark.ron` with the contents of `../benchmark.ron`: ```rust ( exit_after: Some(1500) ) ``` ...in order to run each test for 1500 frames. The recent changes to `many_cubes` and `bevymark` added reproducible random number generation so that with the same settings, the same rng will occur. They also added benchmark modes that use a fixed delta time for animations. Combined this means that the same frames should be rendered both on main and on the branch. The graphs compare main (yellow) to this PR (red). ### 3D Mesh `many_cubes --benchmark` <img width="1411" alt="Screenshot 2023-09-03 at 23 42 10" src="https://github.com/bevyengine/bevy/assets/302146/2088716a-c918-486c-8129-090b26fd2bc4"> The mesh and material are the same for all instances. This is basically the best case for the initial batching implementation as it results in 1 draw for the ~11.7k visible meshes. It gives a ~30% reduction in median frame time. The 1000th frame is identical using the flip tool:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4615 seconds ``` ### 3D Mesh `many_cubes --benchmark --material-texture-count 10` <img width="1404" alt="Screenshot 2023-09-03 at 23 45 18" src="https://github.com/bevyengine/bevy/assets/302146/5ee9c447-5bd2-45c6-9706-ac5ff8916daf"> This run uses 10 different materials by varying their textures. The materials are randomly selected, and there is no sorting by material bind group for opaque 3D so any batching is 'random'. The PR produces a ~5% reduction in median frame time. If we were to sort the opaque phase by the material bind group, then this should be a lot faster. This produces about 10.5k draws for the 11.7k visible entities. This makes sense as randomly selecting from 10 materials gives a chance that two adjacent entities randomly select the same material and can be batched. The 1000th frame is identical in flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4537 seconds ``` ### 3D Mesh `many_cubes --benchmark --vary-per-instance` <img width="1394" alt="Screenshot 2023-09-03 at 23 48 44" src="https://github.com/bevyengine/bevy/assets/302146/f02a816b-a444-4c18-a96a-63b5436f3b7f"> This run varies the material data per instance by randomly-generating its colour. This is the worst case for batching and that it performs about the same as `main` is a good thing as it demonstrates that the batching has minimal overhead when dealing with ~11k visible mesh entities. The 1000th frame is identical according to flip:  ``` Mean: 0.000000 Weighted median: 0.000000 1st weighted quartile: 0.000000 3rd weighted quartile: 0.000000 Min: 0.000000 Max: 0.000000 Evaluation time: 0.4568 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d` <img width="1412" alt="Screenshot 2023-09-03 at 23 59 56" src="https://github.com/bevyengine/bevy/assets/302146/cb02ae07-237b-4646-ae9f-fda4dafcbad4"> This spawns 160 waves of 1000 quad meshes that are shaded with ColorMaterial. Each wave has a different material so 160 waves currently should result in 160 batches. This results in a 50% reduction in median frame time. Capturing a screenshot of the 1000th frame main vs PR gives:  ``` Mean: 0.001222 Weighted median: 0.750432 1st weighted quartile: 0.453494 3rd weighted quartile: 0.969758 Min: 0.000000 Max: 0.990296 Evaluation time: 0.4255 seconds ``` So they seem to produce the same results. I also double-checked the number of draws. `main` does 160000 draws, and the PR does 160, as expected. ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --material-texture-count 10` <img width="1392" alt="Screenshot 2023-09-04 at 00 09 22" src="https://github.com/bevyengine/bevy/assets/302146/4358da2e-ce32-4134-82df-3ab74c40849c"> This generates 10 textures and generates materials for each of those and then selects one material per wave. The median frame time is reduced by 50%. Similar to the plain run above, this produces 160 draws on the PR and 160000 on `main` and the 1000th frame is identical (ignoring the fps counter text overlay).  ``` Mean: 0.002877 Weighted median: 0.964980 1st weighted quartile: 0.668871 3rd weighted quartile: 0.982749 Min: 0.000000 Max: 0.992377 Evaluation time: 0.4301 seconds ``` ### 2D Mesh `bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --vary-per-instance` <img width="1396" alt="Screenshot 2023-09-04 at 00 13 53" src="https://github.com/bevyengine/bevy/assets/302146/b2198b18-3439-47ad-919a-cdabe190facb"> This creates unique materials per instance by randomly-generating the material's colour. This is the worst case for 2D batching. Somehow, this PR manages a 7% reduction in median frame time. Both main and this PR issue 160000 draws. The 1000th frame is the same:  ``` Mean: 0.001214 Weighted median: 0.937499 1st weighted quartile: 0.635467 3rd weighted quartile: 0.979085 Min: 0.000000 Max: 0.988971 Evaluation time: 0.4462 seconds ``` ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite` <img width="1396" alt="Screenshot 2023-09-04 at 12 21 12" src="https://github.com/bevyengine/bevy/assets/302146/8b31e915-d6be-4cac-abf5-c6a4da9c3d43"> This just spawns 160 waves of 1000 sprites. There should be and is no notable difference between main and the PR. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --material-texture-count 10` <img width="1389" alt="Screenshot 2023-09-04 at 12 36 08" src="https://github.com/bevyengine/bevy/assets/302146/45fe8d6d-c901-4062-a349-3693dd044413"> This spawns the sprites selecting a texture at random per instance from the 10 generated textures. This has no significant change vs main and shouldn't. ### 2D Sprite `bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --vary-per-instance` <img width="1401" alt="Screenshot 2023-09-04 at 12 29 52" src="https://github.com/bevyengine/bevy/assets/302146/762c5c60-352e-471f-8dbe-bbf10e24ebd6"> This sets the sprite colour as being unique per instance. This can still all be drawn using one batch. There should be no difference but the PR produces median frame times that are 4% higher. Investigation showed no clear sources of cost, rather a mix of give and take that should not happen. It seems like noise in the results. ### Summary | Benchmark | % change in median frame time | | ------------- | ------------- | | many_cubes | 🟩 -30% | | many_cubes 10 materials | 🟩 -5% | | many_cubes unique materials | 🟩 ~0% | | bevymark mesh2d | 🟩 -50% | | bevymark mesh2d 10 materials | 🟩 -50% | | bevymark mesh2d unique materials | 🟩 -7% | | bevymark sprite | 🟥 2% | | bevymark sprite 10 materials | 🟥 0.6% | | bevymark sprite unique materials | 🟥 4.1% | --- ## Changelog - Added: 2D and 3D mesh entities that share the same mesh and material (same textures, same data) are now batched into the same draw command for better performance. --------- Co-authored-by: robtfm <50659922+robtfm@users.noreply.github.com> Co-authored-by: Nicola Papale <nico@nicopap.ch>
# Objective - since #9685 ,bevy introduce automatic batching of draw commands, - `batch_and_prepare_render_phase` take the responsibility for batching `phaseItem`, - `GetBatchData` trait is used for indentify each phaseitem how to batch. it defines a associated type `Data `used for Query to fetch data from world. - however,the impl of `GetBatchData ` in bevy always set ` type Data=Entity` then we acually get following code `let entity:Entity =query.get(item.entity())` that cause unnecessary overhead . ## Solution - remove associated type `Data ` and `Filter` from `GetBatchData `, - change the type of the `query_item ` parameter in get_batch_data from` Self::Data` to `Entity`. - `batch_and_prepare_render_phase ` no longer takes a query using `F::Data, F::Filter` - `get_batch_data `now returns `Option<(Self::BufferData, Option<Self::CompareData>)>` --- ## Performance based in main merged with #11290 Window 11 ,Intel 13400kf, NV 4070Ti  frame time from 3.34ms to 3 ms, ~ 10% 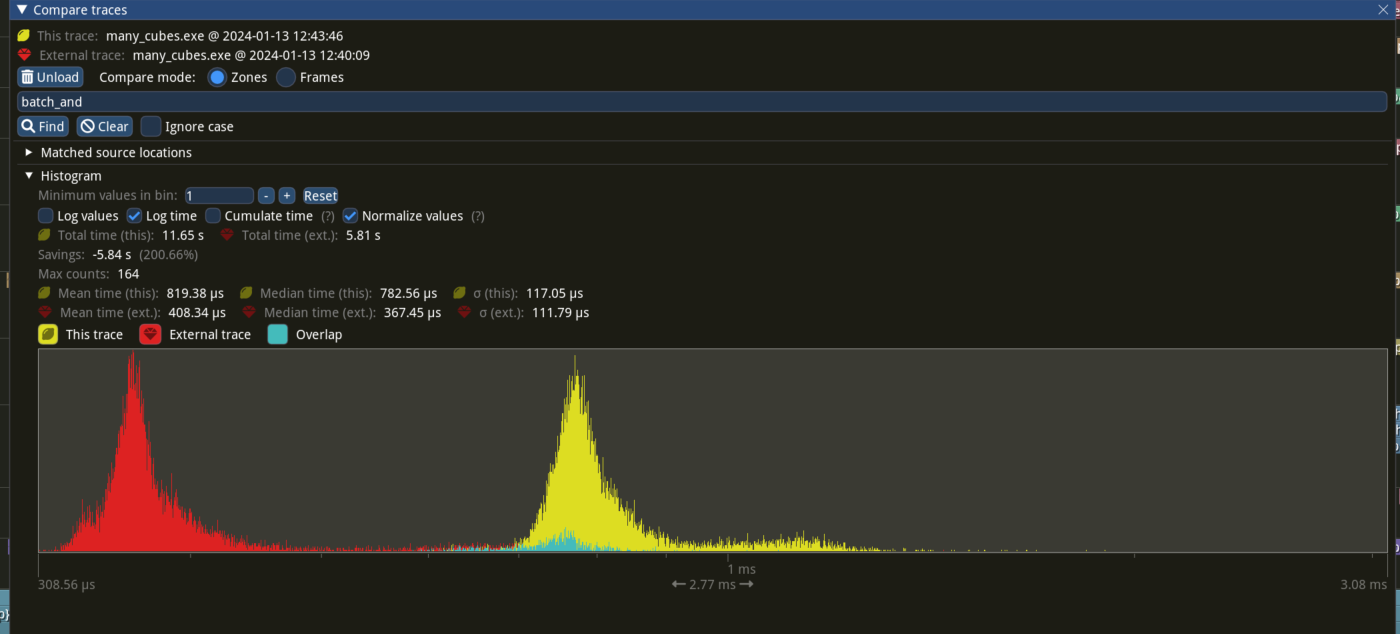 `batch_and_prepare_render_phase` from 800us ~ 400 us ## Migration Guide trait `GetBatchData` no longer hold associated type `Data `and `Filter` `get_batch_data` `query_item `type from `Self::Data` to `Entity` and return `Option<(Self::BufferData, Option<Self::CompareData>)>` `batch_and_prepare_render_phase` should not have a query
Objective
Solution
batch_and_prepare_render_phaseis the only system that performs this batching and has sole responsibility for preparing the per-object data. As such the mesh binding and dynamic offsets are assumed to only vary as a result of thebatch_and_prepare_render_phasesystem, e.g. due to having to split data across separate uniform bindings within the same buffer due to the maximum uniform buffer binding size.GpuArrayBufferforMesh2dUniformto store Mesh2dUniform in arrays in GPU buffers rather than each one being at a dynamic offset in a uniform buffer. This is the same optimisation that was made for 3D not long ago.PhaseItem, adding API for getting or mutating the range. This is more flexible than a size as the length of the range can be used in place of the size, but the start and end can be otherwise whatever is needed.PhaseItem. This avoids having to do a massive table move just to insertGpuArrayBufferIndexcomponents.Benchmarks
All tests have been run on an M1 Max on AC power.
bevymarkandmany_cubeswere modified to use 1920x1080 with a scale factor of 1. I run a script that runs a separate Tracy capture process, and then runs the bevy example with--features bevy_ci_testing,trace_tracyandCI_TESTING_CONFIG=../benchmark.ronwith the contents of../benchmark.ron:...in order to run each test for 1500 frames.
The recent changes to
many_cubesandbevymarkadded reproducible random number generation so that with the same settings, the same rng will occur. They also added benchmark modes that use a fixed delta time for animations. Combined this means that the same frames should be rendered both on main and on the branch.The graphs compare main (yellow) to this PR (red).
3D Mesh
many_cubes --benchmarkThe 1000th frame is identical using the flip tool:
3D Mesh
many_cubes --benchmark --material-texture-count 10The 1000th frame is identical in flip:
3D Mesh
many_cubes --benchmark --vary-per-instanceThe 1000th frame is identical according to flip:
2D Mesh
bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2dCapturing a screenshot of the 1000th frame main vs PR gives:
So they seem to produce the same results. I also double-checked the number of draws.
maindoes 160000 draws, and the PR does 160, as expected.2D Mesh
bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --material-texture-count 102D Mesh
bevymark --benchmark --waves 160 --per-wave 1000 --mode mesh2d --vary-per-instanceThe 1000th frame is the same:
2D Sprite
bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite2D Sprite
bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --material-texture-count 102D Sprite
bevymark --benchmark --waves 160 --per-wave 1000 --mode sprite --vary-per-instanceSummary
Changelog