Mozsearch is the backend for the Searchfox code indexing tool. Searchfox runs inside AWS, but you can develop on Searchfox locally using Vagrant.
First, install Vagrant by following the instructions for your OS. Then clone Mozsearch and provision a Vagrant instance:
git clone https://github.com/bill-mccloskey/mozsearch
cd mozsearch
vagrant up
The last step will take some time (10 or 15 minutes on a fast laptop) to download a lot of dependencies and build some tools locally. After the command completes, ssh into the VM as follows. From this point onward, all commands should be executed inside the VM.
vagrant ssh
At this point, your Mozsearch git directory has been mounted into a
shared folder at /vagrant in the VM. Any changes made from inside or
outside the VM will be mirrored to the other side. Generally I find it
best to edit code outside the VM, but any commands to build or run
scripts must run inside the VM.
The first step is to build all the statically compiled parts of Mozsearch:
# This clang plugin analyzes C++ code and is written in C++.
cd /vagrant/clang-plugin
make
# The Rust code is stored here. We do a release build since our scripts
# look in tools/target/release to find binaries.
cd /vagrant/tools
cargo build --release
Mozsearch chooses what to index using a set of configuration
files. There is a test configuration inside the Mozsearch tests
directory. We'll use this configuration for testing. However, Mozilla
code indexing is done using the
mozsearch-mozilla
repository.
The config.json file is the most important part of the
configuration. It contains metadata about the trees to be indexed. For
example, it describes where the files are stored, whether there is a
git repository that backs the files to be indexed, and whether there
is blame information available.
Mozsearch stores all the indexed information in a directory called the index. This directory contains a full-text search index, a map from symbol names to where they appear, a list of all files, and symbol information for each file.
The first step in indexing is to run the indexer-setup.sh
script. This script sets up the directory structure for the index. In
some cases, it will also download the repositories that will be
indexed. In the case of the test repository, though, all the files are
already available. From the VM, run the following command to create
the index directory at ~/index.
mkdir ~/index
/vagrant/infrastructure/indexer-setup.sh /vagrant/tests ~/index
Now it's time to index! To do that, run the indexer-run.sh
script. It will compile and index all the C++ files and also do
whatever indexing is needed on JS, IDL, and IPDL files.
/vagrant/infrastructure/indexer-run.sh /vagrant/tests ~/index
Now is a good time to look through the ~/index/tests directory to
look at all the index files that were generated. To begin serving web
requests, we can start the server as follows:
# Creates a configuration file for nginx.
/vagrant/infrastructure/web-server-setup.sh /vagrant/tests ~/index
# Starts the Python and Rust servers needed for Mozsearch.
/vagrant/infrastructure/web-server-run.sh ~/index
At this point, you should be able to visit the server, which is
running on port 80 inside the VM and port 8000 outside the VM. Visit
http://localhost:8000/ to do so.
Although it can take a long time, it's sometimes necessary to index the Mozilla codebase. Here's how to do that:
# Clone the Mozilla configuration into ~/config.
git clone https://github.com/bill-mccloskey/mozsearch-mozilla ~/mozilla-config
# Manually edit the ~/mozilla-config/config.json to remove trees you don't
# care about (probably NSS and comm-central).
vi ~/mozilla-config/config.json
# Make a new index directory.
mkdir ~/mozilla-index
# This step will download copies of the Mozilla code and blame information, so it may be slow.
/vagrant/infrastructure/indexer-setup.sh ~/mozilla-config ~/mozilla-index
# This step involves compiling Gecko and indexing a lot of code, so it will be slow!
/vagrant/infrastructure/indexer-run.sh ~/mozilla-config ~/mozilla-index
The Mozsearch indexing process has three main steps, depicted here:
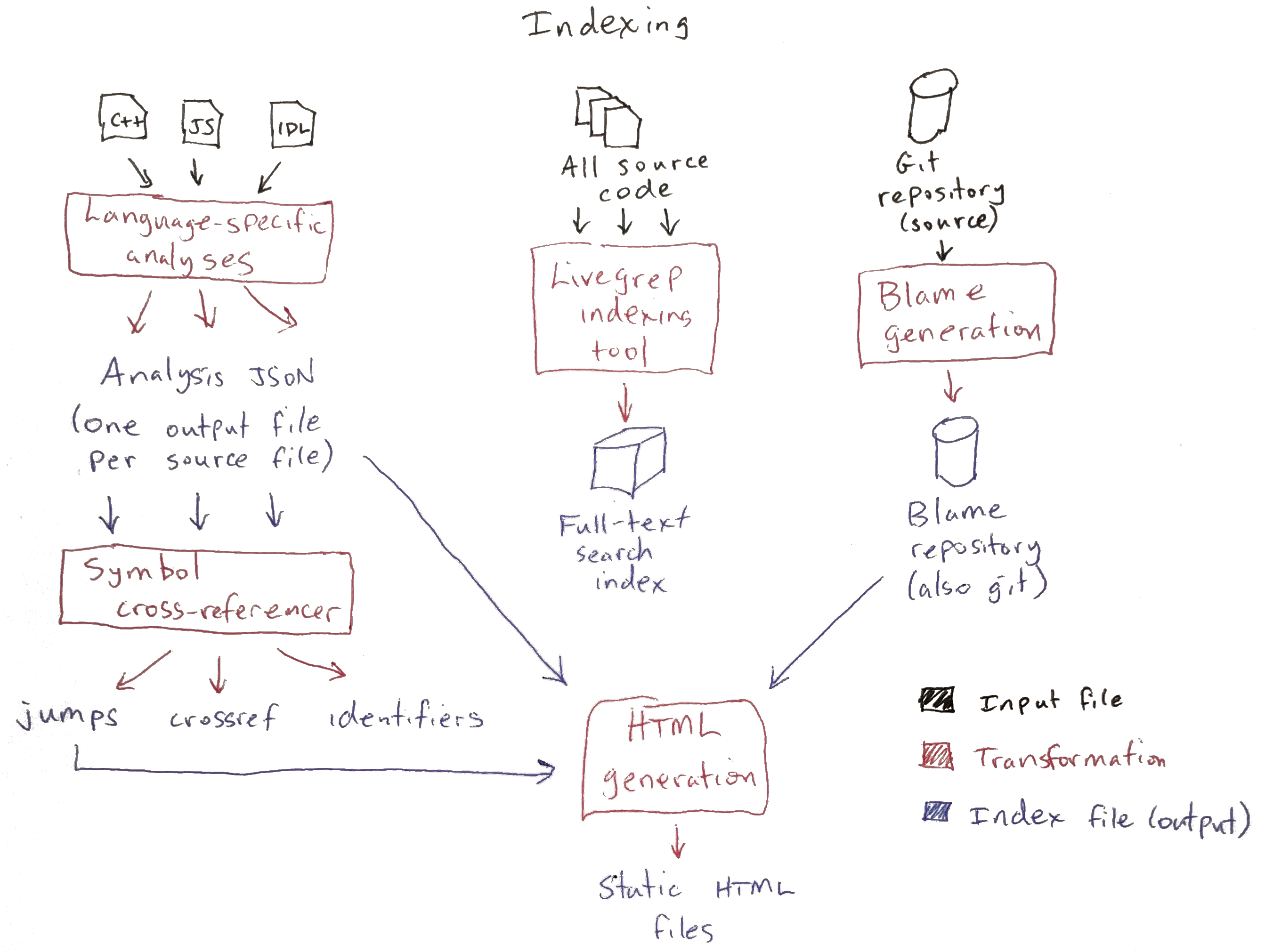
Here are these steps in more detail:
-
A language-specific analysis step. This step processes C++, JavaScript, and IDL files. For each input file, it generates a line-delimited JSON file as output. Each line of the output file corresponds to an identifier in the input file. The line contains a JSON object describing the identifier (the symbol that it refers to, whether it's a use or a def, etc.). More information on the analysis format can be found in the analysis documentation.
-
Full-text index generation. This step generates a single large index file,
livegrep.idx. This self-contained file can be used to do regular expression searches on every text file in the input. The index is generated by thecodesearchtool, which is part of Livegrep. The samecodesearchtool is used by the web server to search the index. -
Blame generation. This step takes a git repository as input and generates a "blame repository" as output. Every revision in the original repository has a corresponding blame revision. The blame version of the file will have one line for every line in the original file. This line will contain the revision ID of the revision in the original repository that introduced that line. This format makes it very fast to look up the blame for an arbitrary line at an arbitrary revision. More information is available on blame caching.
Once all these intermediate files have been generated, a
cross-referencing step merges all of the symbol information into a set
of summary files: crossref, jumps, and identifiers. These files
are used for answering symbol lookup queries in the web server and for
generating static HTML pages. More detail is available on
cross-referencing.
After all the steps above, Mozsearch generates one static HTML file
for every source file. These static HTML pages are served in response
to URLs like
https://searchfox.org/mozilla-central/source/dir/foobar.cpp. Most
requests are for URLs of this type. Generating the HTML statically
makes it very quick for the web server frontend (nginx) to serve these
requests.
HTML generation takes as input the analysis JSON. It uses this data to
syntax highlight the code more effectively (so that it can color types
differently from variables, and definitions differently from uses). It
also uses the analysis JSON, as well as the jumps file, to generate
the context menu information for each identifier. In addition, the
blame repository is used to generate HTML for the blame strip.