This repo primarily comprises an implmentation of Machine Comprehension by Text-to-Text Neural Question Generation as used for our paper Evaluating Rewards for Question Generation Models , plus a load of other research code. It is a work in progress and almost certainly contains bugs!
Requires python 3 and TensorFlow - tested on 1.4, 1.7, 1.12
pip install -r requirements.txt
./setup.sh
./demo.shOr run the demo with docker - you'll need to mount ./models and ./data
To train a model, place SQuAD and Glove datasets in ./data/ and run train.sh. To evaluate a saved model, run eval.sh. See src/flags.py for a description of available options and hyperparameters.
If you have a saved model checkpoint, you can interact with it using the demo - run python src/demo/app.py.
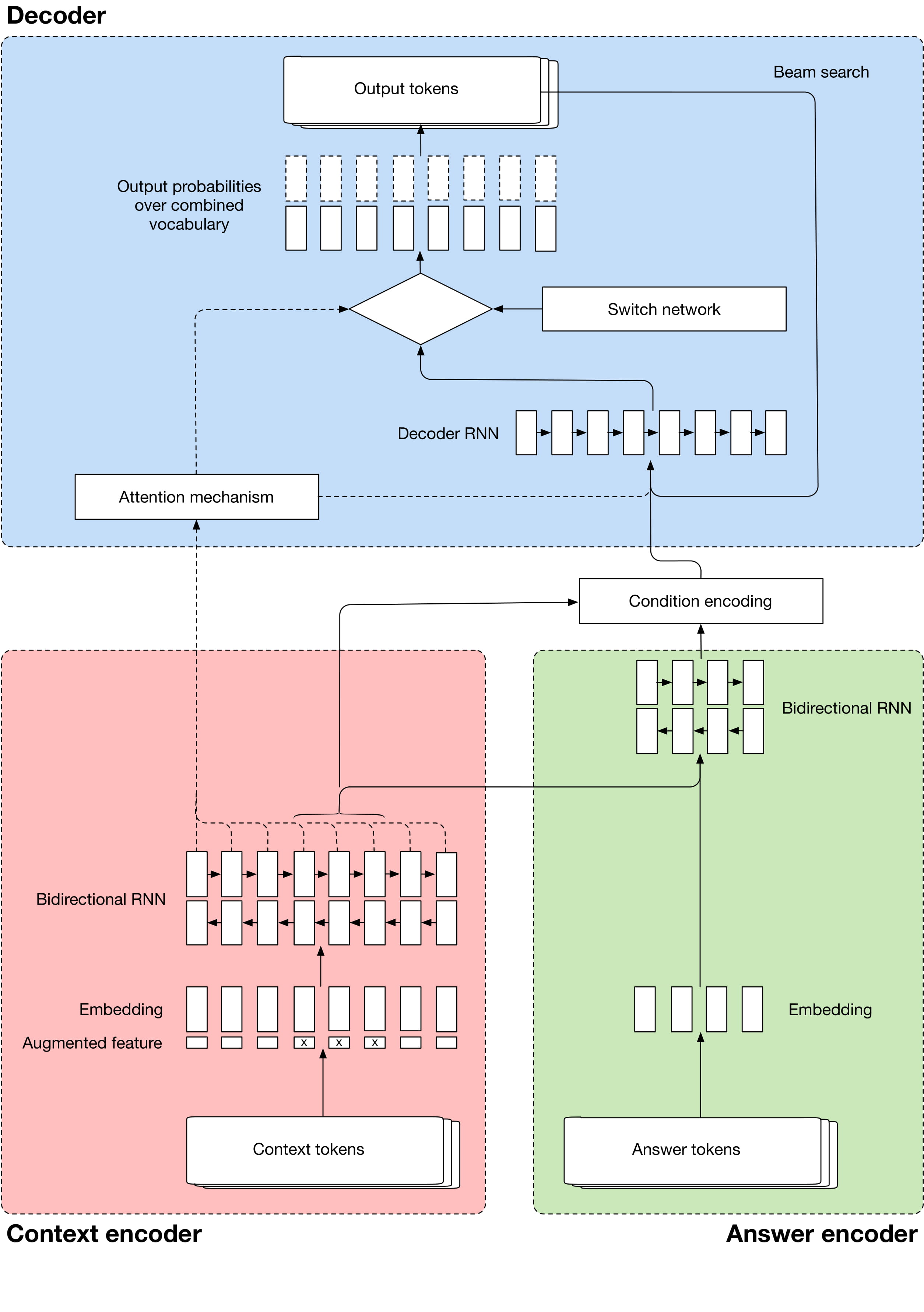
TFModel provides a basic starting point and should cover generic boilerplate TF work. Seq2SeqModel implements most of the model, including a copy mechanism, encoder/decoder architecture and so on. MaluubaModel adds the extra computations required for continued training by policy gradient.
src/datasources/squad_streamer.py provides an input pipeline using TensorFlow datasets to do all the preprocessing.
src/langmodel/lm.py implements a relatively straightforward LSTM language model.
src/qa/mpcm.py implements the Multi-Perspective Context Matching QA model referenced in the Maluuba paper. NOTE: I have yet to train this successfully beyond 55% F1, there may still be bugs hidden in there.
src/discriminator/ is a modified QANet architecture, used to predict whether a context/question/answer triple is valid or not - this could be used to distinguish between generated questions and real ones or to filter out adversarial examples (eg SQuAD v2).
If you find this code useful, please cite our paper!
@misc{hosking2019evaluating,
title={Evaluating Rewards for Question Generation Models},
author={Tom Hosking and Sebastian Riedel},
year={2019},
eprint={1902.11049},
archivePrefix={arXiv},
primaryClass={cs.CL}
}