Natural Language Processing
by: Alexander L. Hayes
Natural language processing is generally a hard task for methods which ignore the relations between sentences and words, and require careful feature construction to work effectively. We focus on preserving these relations while using BoostSRL as the learning and inference engine.
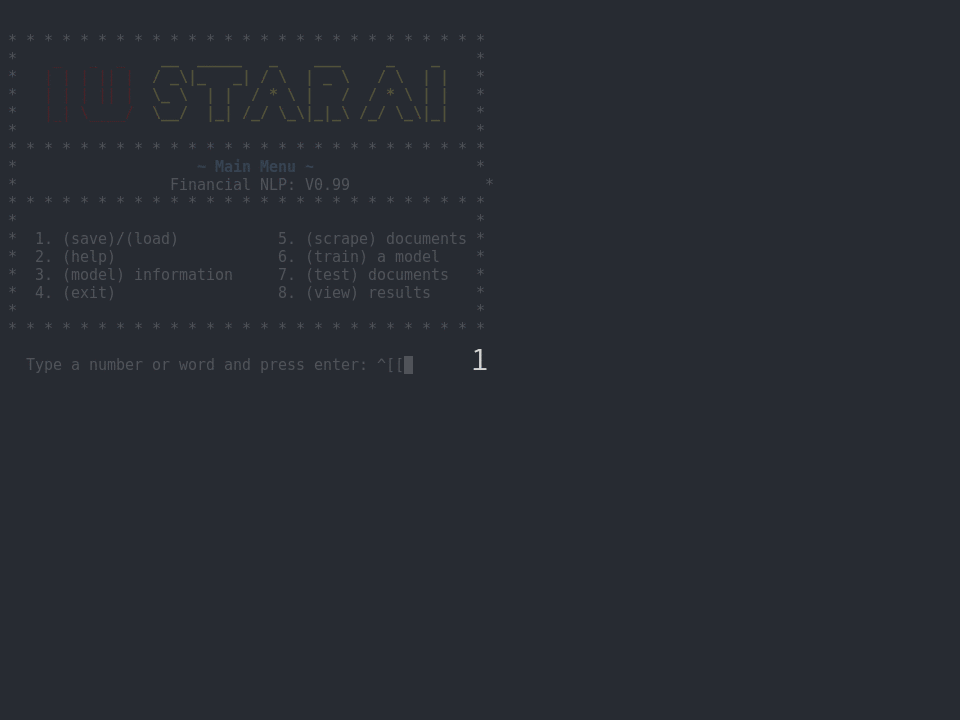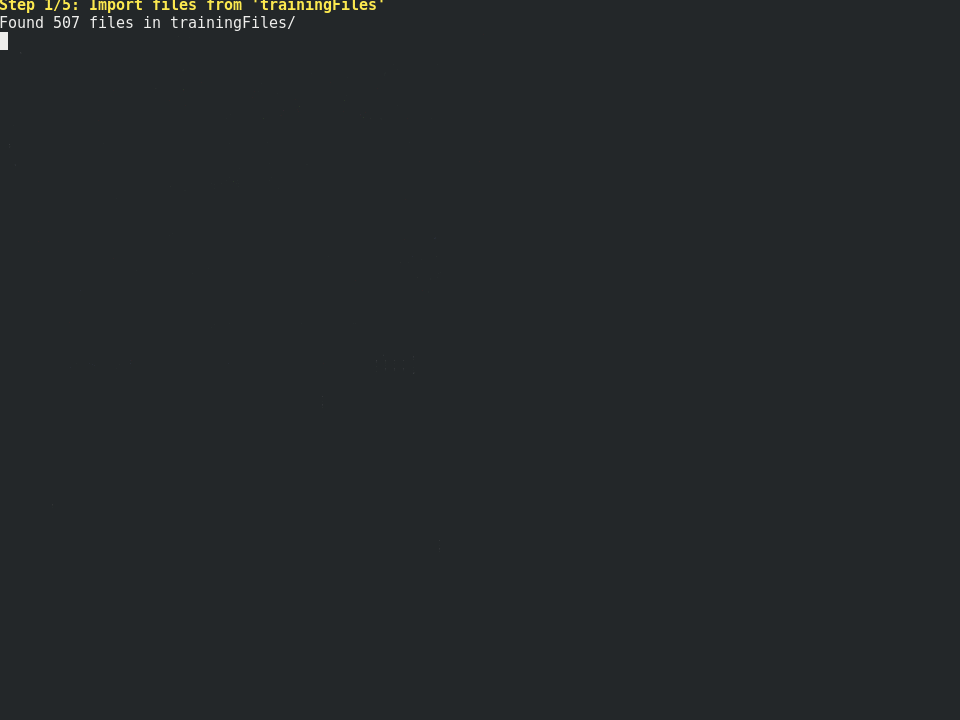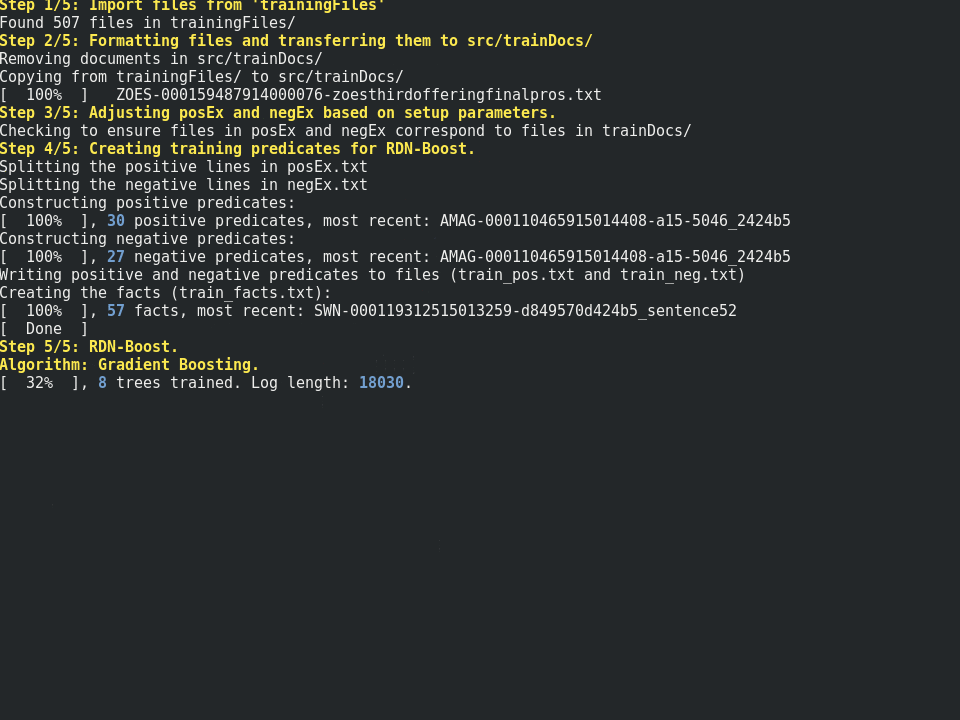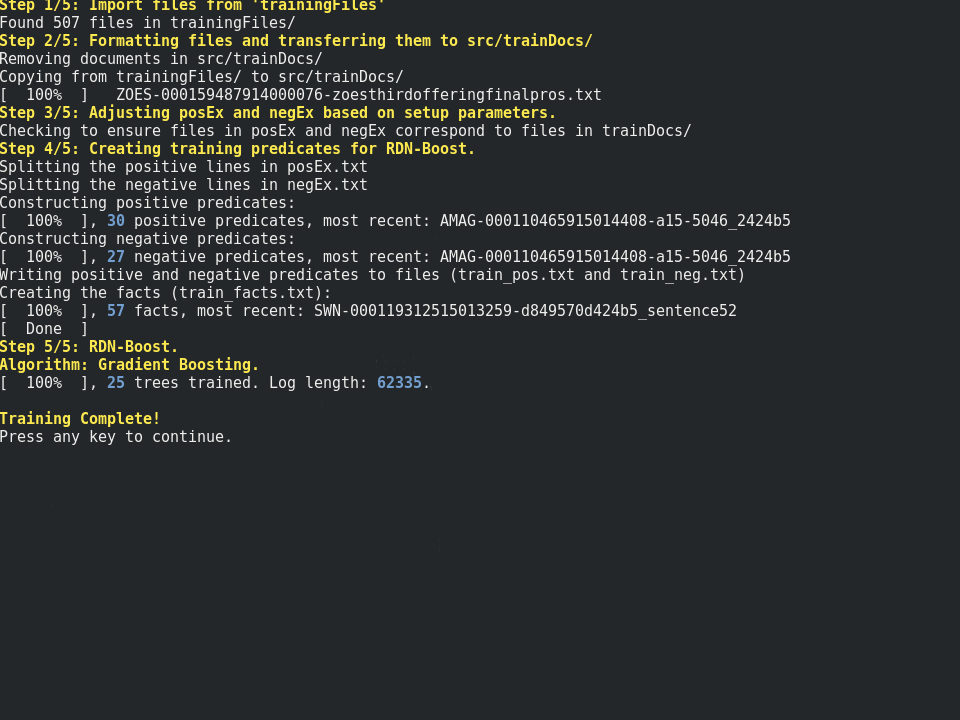
"Financial NLP" is an information extraction project for finding three features in SEC Form S-1 documents, notably the number of primary shares, secondary shares, and overallotments. This project is split into two parts: the information extraction package and the terminal interface to make it easier to interact with. Furthermore, it is a testbed for providing advice to the algorithms through markov logic networks.
- Sriraam Natarajan, Ameet Soni, Anurag Wazalwar, Dileep Viswanathan, and Kristian Kersting, Deep Distant Supervision: Learning Statistical Relational Models for Weak Supervision in Natural Language Extraction, Morik Festschrift, LNAI 9580 2016.
- Sriraam Natarajan, Vishal Bangera, Tushar Khot, Jose Picado, Anurag Wazalwar, Vitor Santos Costa, David Page, and Michael Caldwell, Markov Logic Networks for Adverse Drug Event Extraction from Text, Knowledge and Information Systems (KAIS), 2016.
- Ameet Soni, Dileep Viswanathan, Jude Shavlik, and Sriraam Natarajan, Learning Relational Dependency Networks for Relation Extraction, Internation Conference on Inductive Logic Programming (ILP), 2016.