This is a sequence to sequence (seq2seq) model written in Tensorflow that predicts a word's pronunciation from its spelling. It is designed around the CMU Pronouncing Dictionary which represents phonetics using ARPAbet sybmols.
e.g. TELEPHONE —> T EH1 L AH0 F OW2 N
When properly trained, this model should not only learn the pronunciations contained within the dataset but also be able to generalize the rules of pronunciation when making predictions on words not contained within the dataset
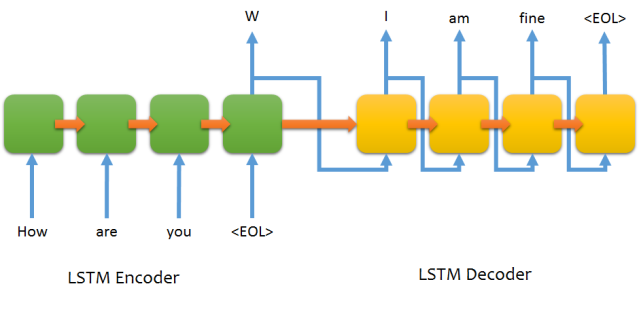
(Image source: jeddy92)
This repository is meant to be an intermediate level exemplar of a seq2seq model, a class of models designed to be able to read in and then output variable length sequences. Instead of tackling the task of Machine Translation, which such models have proven to be excellent at (See this Google blog post), this model focuses on the less complex and resource intensive task of learning to pronounce words so as to help the user gain intuition into how these models work and how they are implemented.
The code is aimed at those who want more control over the implementation than Keras can offer but are not yet ready for the full complexity of the Tensorflow NMT model. It is commented and factored to emphasize readability and interpretability.
There already exist many machine readable pronunciation datasets but without a pronunciation model, these can only be used either as a kind of lookup table or reference material. Seq2seq models offer NLP practitioners one way of generalizing such data so that predictions can be made on words or phrases that are not found in these (often hand collated) sources.
This model also employs a character level approach which has proven to be surprisingly effective in many different NLP tasks such as language modeling and machine translation. In the context of pronunciation prediction, the model is fed one alphabetic character at a time before it predicts the pronunciation one phonetic symbol at a time.
The modern neural network architectures are related to the computational models used by Pscyholinguists of the Connectionist school. Prior to their work, reading was conceived of as a dual process whereby a written word is either regularly and formulaicly converted into a pronunciation (e.g. gave, save and pave) while certain words are irregular and therefore memorized (e.g. have). Connectionists sought to integrate both these processes into the one model and capture the "quasi regularities" of language. It is worth asking whether the learning dynamics of these latest neural network architectures still parallel the ways in which humans learn.
Also of interest to me is whether the learned spelling and pronunciation embeddings bear any resemblence to their classification by linguists. In their respective vector spaces, will we see vowels and consonants cluster together? Are there regions which correspond to certain phonological features (e.g. voice or place of articulation)?
- Variable cell types (LSTM)
- Bidirectional encoder
- Attention mechanism
- Dropout
- Gradient clipping
- Learning rate annealing
Clone the repository. Then, in your python3 environment, install dependencies using
pip install -r requirements.txt
Go to the data folder and download the CMU Pronouncing dictionary
cd data
wget http://svn.code.sf.net/p/cmusphinx/code/trunk/cmudict/cmudict-0.7b
or
cd data
curl http://svn.code.sf.net/p/cmusphinx/code/trunk/cmudict/cmudict-0.7b > cmudict-0.7b
Split the data into train, dev and test sets
python preprocessing.py
Train the model, perform validation and test its performance
python main.py
Perform just one of these three actions using the --train, --validation or --test flags. Adjust hyperparameters by editing main.py
Use a saved model located in MODEL_DIR to perform inference on words that you type in
python interative.py --dir MODEL_DIR
After validating, training and testing, model checkpoints are found in save_dir (defined in main.py). Within save_dir there is also a results folder which contains:
hyperparameters.json- stores model hyperparameters that can be used to initialize a new CharToPhonModelloss_track.pkl- when unpickled, it returns a list of loss values for each batch of trainingtrain_sample.txtanddev_sample.txt- prediction is performed on the sample data set with each model checkpoint. The inputs and outputs are written to these files. The predictions intrain_sample.txtare generated using a training decoder (c.f.tf.contrib.seq2seq.TrainingHelper), meaning that at each timestep, the input is an ARPA symbol embedding from the gold standard label. By contrast, the predictions indev_sample.txtare generated using a greedy decoder (c.f.tf.contrib.seq2seq.GreedyEmbeddingHelper) such that the input at each timestep is chosen via the ARGMAX of the previous timestep's output.metrics.txt- contains performance metrics of each model checkpoint on the dev data set and a slice of the train data set of the same size as the dev set. Accuracy is calculated based on how many words are predicted entirely correctly. Similarity is calculated using Python's difflib.SequenceMatcher and is the average similarity between the predicted pronunciation and the gold standard label.test.txt- contains the model's performance on the test setgraph.png- shows training loss, train accuracy and similarity, dev accuracy and similiarty