This project provides a simple benchmarking facility for Eigen. It was developed mainly for benchmarking the Eigen MAGMA backend implementation. This project also serves as sample CMake project to use Eigen in combination with MAGMA and MKL.
You need to first install Intel MKL, Eigen, CUDA and MAGMA. It has been tested with Intel Parallel Studio 2013, Eigen 3.2.0, CUDA 5.5 and MAGMA 1.4.0.
- Clone the Eigen-Magma project: https://github.com/bravegag/eigen-magma
- Clone this project: https://github.com/bravegag/eigen-magma-benchmark
- Export the following variables
export EIGEN3_INCLUDE_DIR=<location where you cloned eigen-magma> export MAGMA_ROOT=<your magma install location>
- Create a Release build with the following command (using Intel compiler):
rm -rf build; mkdir build; cd build; cmake -DCMAKE_BUILD_TYPE=Release -DCMAKE_C_COMPILER=icc -DCMAKE_CXX_COMPILER=icpc -DCMAKE_Fortran_COMPILER=ifort ../src
- Edit the CMakeLists.txt file and enable Eigen only, MKL or MAGMA by commenting or uncommenting the following definitions:
add_definitions(-DEIGEN_USE_MKL_ALL) add_definitions(-DEIGEN_USE_MAGMA_ALL)
- Build the project executing
maketo have faster compilation with more threads e.g. 5 usemake -j5
- Execute the benchmark
./benchmarkor use./benchmark --helpfor help.
- Hardware
- ASUS Z9PE-D8 WS http://www.asus.com/Motherboards/Z9PED8_WS/
- 2x Intel Xeon E5-2690 2.9Ghz and 3.8Ghz with turbo, 20MB cache, AVX http://ark.intel.com/products/64596/
- 2x EVGA nVidia Titan GTX 6GB http://www.evga.com/products/pdf/06G-P4-2790.pdf
- 64GB DDR3 RAM Corsair Vengueance CMZ32GX3M4X1866C10 with 1866 Mhz clocked at 1600 Mhz
- Software
- Ubuntu 12.04 TS with vm.swappiness=0
- Intel Parallel Studio 2013
- CUDA 5.5
- MAGMA 1.4.0
- CMake 2.8.7
- Boost 1.53
The nVidia Titan GTX card out-of-the-box defaults to a Double-Precision (DP) performance that is only 1/24th of the Single-Precision (SP) performance. The nVidia Titan GTX is capable of reaching a DP performance of up to 1/3 of the SP performance. However, this has to be configured by changing the nVidia default driver settings using the “nvidia-settings” tool installed as part of the nVidia drivers. The CUDA-Double precision box must be checked as shown in the figure below.

The following plots where obtained by executing the currently ported Eigen MAGMA backends:




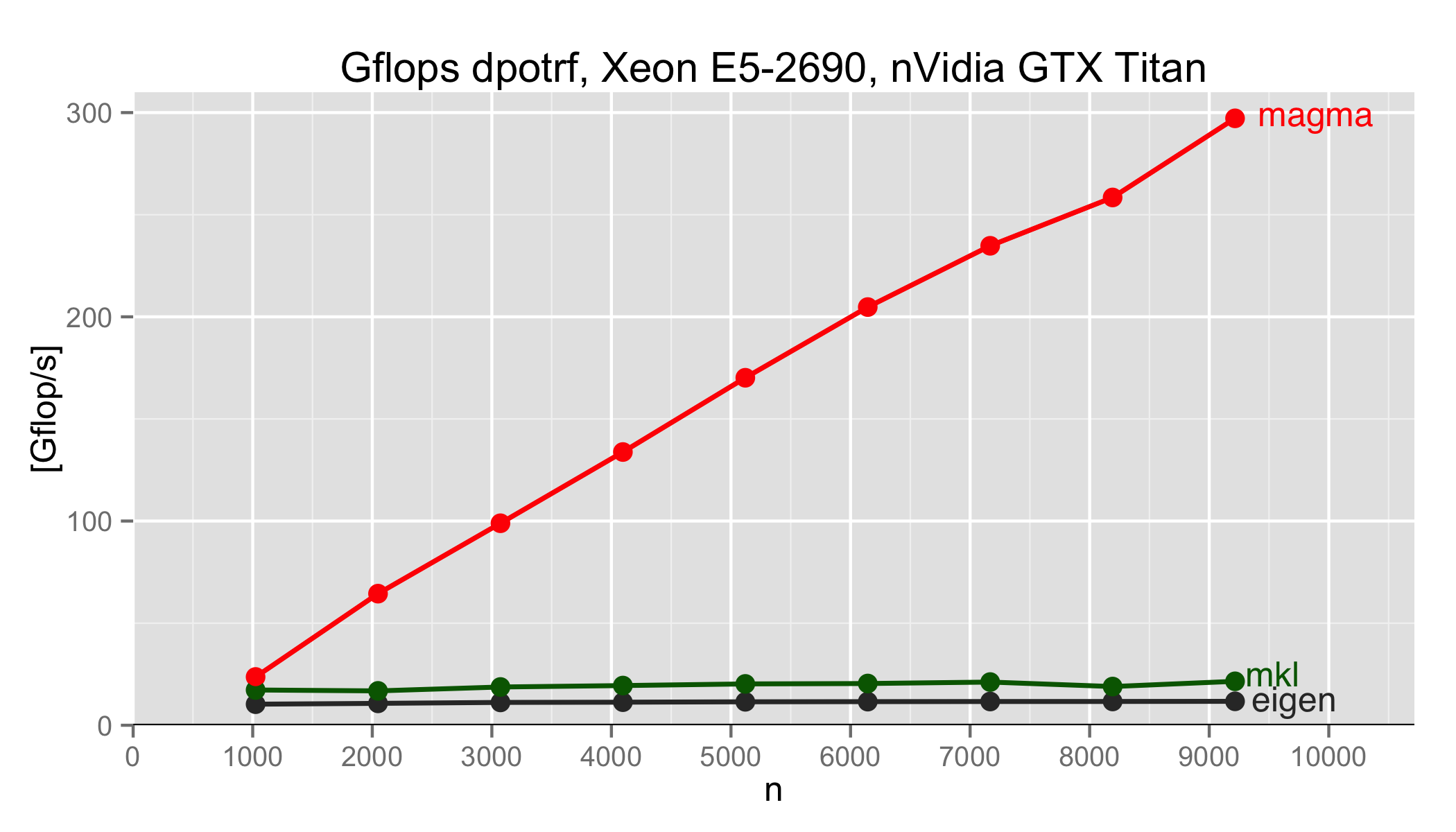


The benchmarks above were obtained using export MKL_NUM_THREADS=1 and export OMP_NUM_THREADS=1 increasing the MKL_NUM_THREADS may improve the results for both the MKL and the MAGMA versions. Furthermore, unlike the benchmarks shown in MAGMA testing implementations these benchmark results above account for the memory transfer times between Host and Device. This is the reason why the dgemv and dtrsm do not seem to perform better than the CPU versions.