
A simple toolkit to generate decision trees for word classification based on minimum suffix match.
This project requires:
- CMake 2.8 or above
- C++11 compiler (tested with GNU C++ 4.8.4)
Use the following commands to build the programs:
# mkdir build
# cd build
# cmake .. && make
-
Use the program
gentreeto generate the decision tree from a corpus:# ./gentree ../corpus/names.txt exampleThis program also enable you to choose the default response when no match is found. By default, the default response is -1.
# ./gentree ../corpus/names.txt 0 exampleThe advantage of choosing a default response as one of responses in the corpus is to reduce the decison tree size, since decision nodes for that response are not generated.
-
Use the program
gencodeto generate C source code from a decision tree:# ./gencode example.tree generated.c -
The program
evaluateenable you to test the classifier. Just replace the filegenerated.cin thesourcedirectory and recompile the program:# cp generated.c ../source/generated.c # make evaluateYou can evaluate interactively (providing words through keyboard)
# evaluateor using a input labeled file
# evaluate ../corpus/names.txt # evaluate ../corpus/test.txt
To perform the training, we need a corpus composed by words and its classification (correct response).
- You can have 2 or more classes in your corpus, but only one class per word;
- Words can include latin1 alphabetic characters (a-z, A-Z and vowels with diacritic). The text must be encoded as ISO-8859-1;
- Classes must be positive integral values.
The first step is to create a word tree. The program gentree will create this tree with all words in the corpus, in reverse order (e.g. from the root you have 'rasec' instead of 'cesar'). Words with similar suffixes follow the same path in the tree until some letter makes them different. To illustrate, consider the following corpus which enable us to classify the gender of people names with the classes 0 (female) and 1 (male).
Our corpus is small for the sake of simplicity. A real world corpus must have much more samples.
Melissa 0
Alice 0
Adele 0
Hayden 0
Robert 1
Cesar 1
Jayden 1
Tim 1
The word tree of the above corpus will look like this:
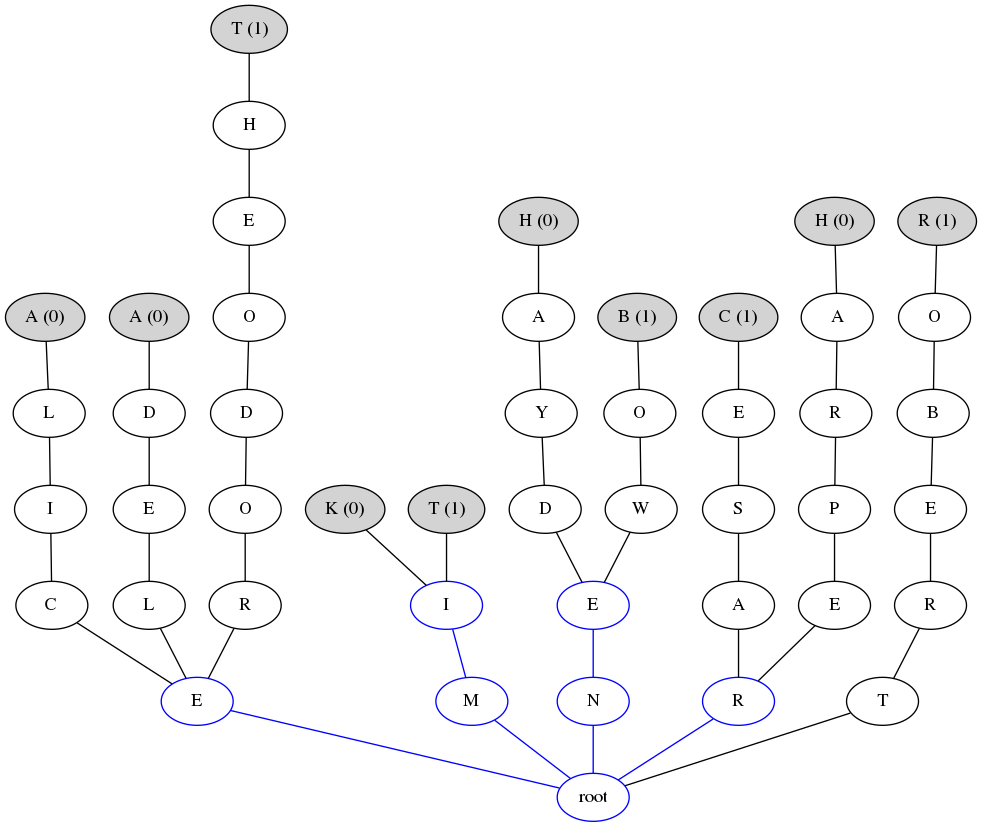
In the image above, every node (except the root) represents letters in the words of the corpus. Gray node are terminals (the first letter of the word) and include the word classification between parenthesis. Blue nodes are points of decision or nodes between the root and points of decision. Points of decision are:
- nominal nodes that have child nodes with more than one classification;
- terminal nodes that have different classification than some of its child nodes;
Notice that intermediary nodes between decision points and the root are also marked to simplify the tree transversal (this enable us to visit only the relevant paths).
The next step is to generate the decision tree. The program gentree transverse the word tree and create one or more decision nodes (decision tree nodes) for each decision point in the word tree.
Our decision tree is presented below (using 0 as default response). Nodes in gray represents the classification at that point.
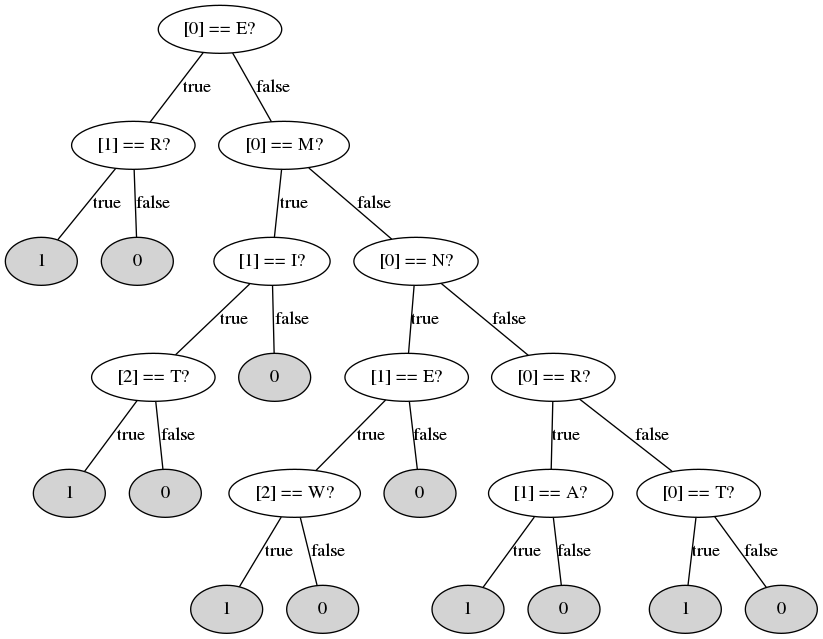
To predict a classification for a word using the decision tree, one need just to reverse the input word and tranverse the decision tree through the decisions.