{kind=link}

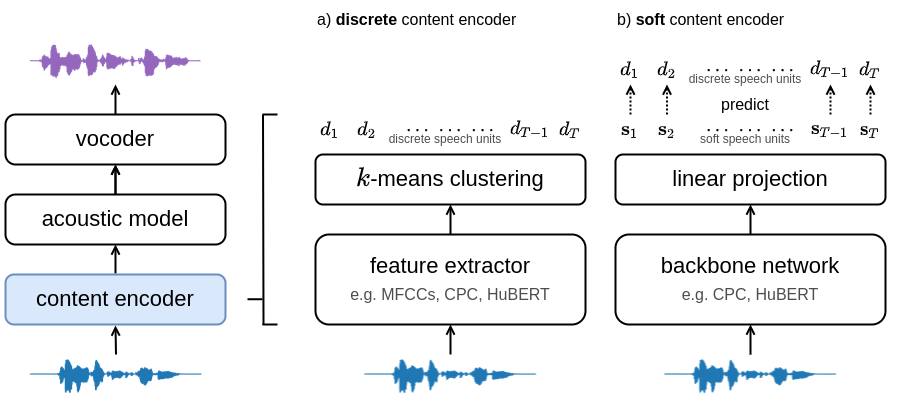
Training and inference scripts for the HuBERT content encoders in A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion. For more details see soft-vc. Audio samples can be found here. Colab demo can be found here.
import torch, torchaudio
# Load checkpoint (either hubert_soft or hubert_discrete)
hubert = torch.hub.load("bshall/hubert:main", "hubert_soft", trust_repo=True).cuda()
# Load audio
wav, sr = torchaudio.load("path/to/wav")
assert sr == 16000
wav = wav.unsqueeze(0).cuda()
# Extract speech units
units = hubert.units(x)usage: encode.py [-h] [--extension EXTENSION] {soft,discrete} in-dir out-dir
Encode an audio dataset.
positional arguments:
{soft,discrete} available models (HuBERT-Soft or HuBERT-Discrete)
in-dir path to the dataset directory.
out-dir path to the output directory.
optional arguments:
-h, --help show this help message and exit
--extension EXTENSION
extension of the audio files (defaults to .flac).
Download and extract the LibriSpeech corpus. The training script expects the following tree structure for the dataset directory:
│ lengths.json
│
└───wavs
├───dev-*
│ ├───84
│ ├───...
│ └───8842
└───train-*
├───19
├───...
└───8975
The train-* and dev-* directories should contain the training and validation splits respectively. Note that there can be multiple train and dev folders e.g., train-clean-100, train-other-500, etc. Finally, the lengths.json file should contain key-value pairs with the file path and number of samples:
{
"dev-clean/1272/128104/1272-128104-0000": 93680,
"dev-clean/1272/128104/1272-128104-0001": 77040,
}Encode LibriSpeech using the HuBERT-Discrete model and encode.py script:
usage: encode.py [-h] [--extension EXTENSION] {soft,discrete} in-dir out-dir
Encode an audio dataset.
positional arguments:
{soft,discrete} available models (HuBERT-Soft or HuBERT-Discrete)
in-dir path to the dataset directory.
out-dir path to the output directory.
optional arguments:
-h, --help show this help message and exit
--extension EXTENSION
extension of the audio files (defaults to .flac).
for example:
python encode.py discrete path/to/LibriSpeech/wavs path/to/LibriSpeech/discrete
At this point the directory tree should look like:
│ lengths.json
│
├───discrete
│ ├───...
└───wavs
├───...
usage: train.py [-h] [--resume RESUME] [--warmstart] [--mask] [--alpha ALPHA] dataset-dir checkpoint-dir
Train HuBERT soft content encoder.
positional arguments:
dataset-dir path to the data directory.
checkpoint-dir path to the checkpoint directory.
optional arguments:
-h, --help show this help message and exit
--resume RESUME path to the checkpoint to resume from.
--warmstart whether to initialize from the fairseq HuBERT checkpoint.
--mask whether to use input masking.
--alpha ALPHA weight for the masked loss.
If you found this work helpful please consider citing our paper:
@inproceedings{
soft-vc-2022,
author={van Niekerk, Benjamin and Carbonneau, Marc-André and Zaïdi, Julian and Baas, Matthew and Seuté, Hugo and Kamper, Herman},
booktitle={ICASSP},
title={A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion},
year={2022}
}