{kind=link}
Cloud-Hydra is a framework for cloud applications to mitigate provider outages by providing resiliency at both the both intra- and inter-cloud levels. Intra-cloud resiliency is a topic that has been studied and practiced in depth, making it possible for pieces of applications to migrate from one server to another. Intra-cloud reliability platforms, however, are not nearly as common. We have included this in order to protect applications from several issues ranging from cyber attacks to hardware failures. If parts of AWS or GCP go down, for example, the application itself should be alive and kicking, as resources will be directed to the provider that is still up. We have implemented load balancing at both the intra- and inter-cloud levels so that all requests are serviced, as well as duplicated data throughout different cloud providers in order to ensure that application users always have access to their current data. We have tested our framework with our own application by running it on multiple cloud providers and testing its reliability when different cloud instances are turned off.
Hydra targets:
- Software Developers and Ops teams that want a resiliency framework for their applications running on Clouds
Hydra does not target:
- End users of above applications
- Cloud Administrators
Hydra features:
- Request-level load balancing and queuing between hosts across clouds.
- If the compute layer of one cloud provider goes down, the application should still function.
- Distributed writes to all database solutions.
- Ability to read from any healthy database server.
- Eventual consistency of newly spawned databases via replication.
- If the database layer of one cloud provider goes down, the application should still function.
- DNS failover so that front-end can always be served
- Resistance to & recovery from database outages
Hydra does not feature:
- More efficient use of compute resources, as many of the servers will be heartbeating and anycasting between each other to track uptime and distribute data.
- Full disaster recovery
- Database replication strategies
- Deduplication of data persisted in the DB
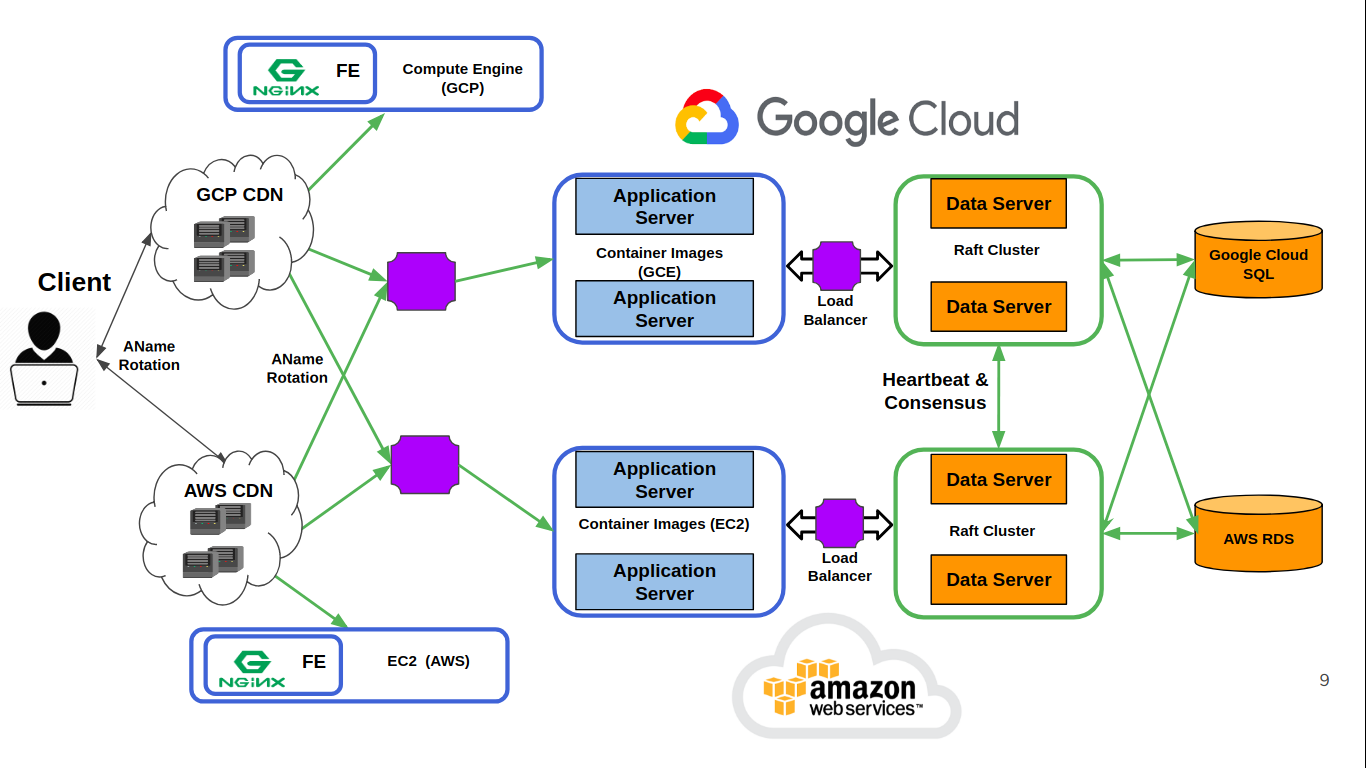
We first built a fullstack web application on both AWS and GCP so that we can test our solution. We setup the entire stack, from cloud CDNs, compute VMs, and databases and connected them together. On AWS, we use EC2 instances for our application and data golang servers, and while using Compute Engine in the Google cloud. The application layer, front-end, and load balancers all use docker contains. For our postgres databases, we use AWS RDS and Google Cloud SQL.
To use multiple database services across many clouds, Hydra also features a distributed database access layer that ensures consistency across all DBs. Hydra's aim is to ensure consistency and availability (and not necessarily partitioning), so writes are distributed across all DBs. There sits a cluster of database access servers (DAS) in all clouds that sits in between the webserver and the database service. Within each cluster we perform consensus on all writes using the Raft protocol. For this we use an open source implementation, courtesy of Hashicorp Raft. As part of the Raft algorithm, each node stores consensus information. Raft also features a leader to execute decisions for the cluster. If the leader goes down, another is elected. For each write that enters the data layer, it is forwarded to the leader and then written to all databases. This is because according to the Raft protocol, only the leader can propose changes to the Raft cluster. Read requests, on the other hand, can be executed by any node in the Raft cluster an can make use of any available database. For example, if the AWS side of the system receives a request to read from the DB, and AWS RDS is up, it will simply read from RDS. If RDS is down, however, the AWS DAS will request a read from the GCP DAS and information will be retrieved from CloudSQL and forwarded to AWS.
In our data layer, we lazily check the state of our databases at the point of every transaction. So if a database goes down, or if a database that was down comes back to life, on the next transaction our data servers will be detect this and take action. Because the data in our raft log is timestamped, and because store in our raft log the time at which we detect a database state change, we can use our raft log to help recover the database. This also requires us to make changes to our raft log, so if a non-leader node every detects a state change, it will have to notify the leader to update the db state in the raft log.
Hydra also feature an application layer in each cloud consisting of a cluster of request servers. These servers receive incoming requests, perform stateless business logic, and eventually forward the request to the load balancer interfacing the data layer. One of the benefits of having an nginx server between the application and data layers is that it not only round robin load balances requests to different data servers, but it acts as a single endpoint for the application servers to hit. Because the application layer is stateless and does not require consensus, it can be scaled up and down as much and as fast as necessary. As long as one application server is up, the system will be alive and running.
In the front end, we have CDNs set up in both clouds serving our front-end code to clients. By having the CDN endpoints map to multiple IPs, each for a different cloud, we can load balance client requests to either cloud. These IPs served by the CDN map directly to our application layer. This means that when you put app.cloud-hydra.com into your browser, that request is going to DNS and getting mapped to an IP. DNS typically maps one domain name to one IP, but we’ve mapped multiple IPs to app.cloud-hydra using ANAME rotation. The DNS will alternate serving front-end code from each cloud using round-robin, and whatever cloud it gets from the front-end, that cloud will then get hit by the front-end code.
Design Implications and Discussion:
-
Request and Database Access Servers usually don't communicate horizontally, but Hydra necessitates at least one server per cloud in the event that an entire provider goes offline.
-
Request and Database Access Servers are constantly in contact with each other to distribute data across clouds and to make decisions based on the status of their peers. This is not more efficient than a single datacenter system, as there will be a compute overhead with constantly checking status and forwarding data. This does, however, lead to great resiliency and fault-tolerance at each layer of each cloud in the system.
-
DB writes will be distributed to all Database Access Servers, meaning that each database service should have a full copy of all the data. Per the CAP theorem, Hydra prioritizes consistency and availability (naturally, as a resiliency system) over more efficient data storage and retrieval strategies afforded by data partitioning.
-
Since Hydra is meant to work on a multi cloud platform, CI/CD for each cloud will need to differ slightly in accordance with each respective API and access structure.
MVP (not in any particular order):
- Basic CRUD web app that, by nature, will exercise DB reads, writes, and possible concurrency issues as a base to apply resiliency strategies to - COMPLETED
- Request load balancing between clouds - COMPLETED
- Host level load balancing within clouds - COMPLETED
- Turning off host instances should not crash the application for an extended period of time - COMPLETED
- DNS failover in the event that the main server goes down - COMPLETED
- Turning off all compute instances of a Cloud should not kill the application - COMPLETED
- 1 Request server per Cloud - COMPLETED
- Two clouds / at least two isolated systems - COMPLETED
Stretch Goals (also not in any particular order):
- Multiple Request Servers and leadership election - COMPLETED
- Distributed DB writes - COMPLETED
- Distributed reads from any healthy database - COMPLETED
- Eventual consistency of new and recovered databases via replication and write queuing - INCOMPLETE
- Turning off database instances should not break the application - COMPLETED
- Multiple Request servers per Cloud - COMPLETED
- More than two clouds - INCOMPLETE
Sprint 1:
- Create a sample garage reservation system that mirrors a real world application
- Get a basic web server running on GCP that can connect to CloudSQL
- Get a basic web server running on AWS that can connect to RDS
- Ensure the web app can serve static content
- Ensure the web app can serve dynamic content and have will CRUD functionality as described by the mentor (garage reservation system with users and cars)
Sprint 2:
- Create a layer on top of the DBs to abstract away the DBs themselves so that the application layer doesn't need to worry about whether or not databases are up
- The machines of the data layer will coordinate via Raft to determine the global ordering of writes
- Reads can be serviced by any node
- Cluster will start out in a single cloud environment
Sprint 3:
- The point of entry to the data layer will be a load balancer that round robins the requests to the underlying nodes
- If a write arrives to a non-leader node, have the node forward the request to the leader for processing
- The cluster will deal with the fact that nodes can be located in any cloud (but will bootstrap with a known leader)
- Single Cloud DB recovery, if the cluster detects that a DB is down, it will log the time and forward all missed requests when the DB comes back up
Sprint 4:
- Clean slate DBs in GCP and AWS to test the system at a full capacity
- Enable multi-cloud DB recovery and ensure that the leader can respond correctly even if relocated to a different cloud
- Make sure the cluster does not collapse when a new leader is chosen in a different cloud (longer network latency)
- DNS ANAME Rotation
Sprint 5:
- Hook up everything together in both clouds
- Test the entire system via hitting the front end and seeing requests snaked through to the data layer
- Test ANAME rotation
- Perform stress tests and gather metrics
These steps assume that you have already deployed the necessary infrastructure in AWS and GCP. The technology stack used is these clouds was mentioned above.
To install the data servers:
cd dao_server
In dao_startup.sh, fill in all the environment variables. This means filling in the IP address of the databases, as well as their usernames and passwords. For the raft variables, if the node you are deploying is the first node in the cluster, set its LEADER variable to true. Raft node id can be any unique integer. For EXTERNAL_IP_QUERY, you must fill it with a command that returns the nodes external IP. This is different for every cloud provider. Once this is done, call:
source dao_startup.sh
go run *.go
To install the application servers:
sudo docker container run -d -e IP=<IP of Load Balancer in front of data layer> -p 80:8888 cloudhydra/appserver:1.2
Creating a Load balancer for the app or data layer:
- Set up an Ubuntu machine or GCP or AWS
- Install Docker: https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-18-04
- create a directory called nginx
- put into the nginx directory two files: default.conf and Dockerfile
Put the following into the Dockerfile:
FROM nginx
EXPOSE 80
COPY ./default.conf /etc/nginx/conf.d/default.conf
Put the following into the nginx file:
upstream <<anything>>{
server <<IP OF DAO OR APP LAYER MACHINE>>:<< port 80 for app and dao is 8888>>;
server <<IP OF DAO OR APP LAYER MACHINE>>:<< port 80 for app and dao is 8888>>;
server <<IP OF DAO OR APP LAYER MACHINE>>:<< port 80 for app and dao is 8888>>;
}
server {
listen 80;
location / {
proxy_pass http://<<same anything as above>>;
}
}
Run docker build -t cloudhydra-loadbalancer .
After it gets build just run docker run -d -p 80:80 cloudhydra-loadbalancer
Now your load balancer should be running as a daemon background process.
Setting up Front End server
- Set up an Ubuntu machine or GCP or AWS
- Install Docker: https://www.digitalocean.com/community/tutorials/how-to-install-and-use-docker-on-ubuntu-18-04
- Run the following command: sudo docker container run -d -p 80:80 cloudhydra/lbfeserver:1.2
Adding Cloud CDN to the feserver:
- Now instead of just a single VM, we’ll need a managed instance group (GCP) or an auto scaling group on AWS
- Let’s take GCP: create a managed instance group with the instance template using the following container image as the instance template: cloudhydra/lbfeserver:1.2
- Create a default load balancer that's solely used for this MIG, and enable Cloud CDN on it
Julian Julian Julian Filip Filip Filip Rachid Rachid Rachid