{kind=link}
{kind=link}
{kind=link}
{kind=link}
Given a dictionary file with term frequency/probability like:
the 23135851162
of 13151942776
and 12997637966
to 12136980858
...
(or even just one column, such as the SOWPODS scrabble dictionary), you just "compile" a dictionary with:
suggest update -d2 -iMY_DICT_FILE -p/tmp/p
(suggest.update is also pretty simple if you want to write your own..) and
then do something like suggest q -p/tmp/p myMispelling anotherWord.. from
the command-line. From Nim code, it would look more like:
import suggest
proc maybe(prefix="/tmp/p", badWord="slugde", dmax=2,
kind=osa, matches=6): seq[string] =
var s = suggest.open(prefix)
result = s.suggestions(badWord, dmax, kind, matches)
s.close
echo maybe() # @["sludge", "slide", ..]In light of subsequent analysis, you may also just want to import suggest,
scan a dictionary "however" & use myersCompile, levenshtein|optimStrAlign.
That is likely "fast enough" with no preprocessed/compiled dictionary and is
easily parallelized (just segment your file into N threads chunks with, e.g.
cligen/mslice.nSplit & handle each, not unlike adix/tests/wf.nim). There
are also other notions in cligen/textUt.distDamerau and hldiff/edits.
This is a from-scratch implementation in Nim of Wolf Garbe's Symmetric Delete Algorithm for correct spelling suggestions. It is identical, in essence, to Variation 1 of Mor & Fraenkel 1982 "A Hash Code Method for Detecting and Correcting Spelling Errors" (DOI 10.1145/358728.358752).
The basic idea is easy: corpus words within edit distance N of a query can only be at most N units longer or N units shorter and the shorter must be derived from deletes of longer strings. So, build a map from all shortenings to all corpus words which generate them. When queried with a string, we can then lookup all possible edits lengthening the query into a corpus word. We also on-the-fly compute all shortenings of a query (& shortenings of lengthenings, though Mor & Fraenkel neglects mentioning this). From the union of all sets, we filter "maybe within N edits of a corpus word" to "actually within N edits". The filter can be any "distance" successfully bounded by N-indels.
If it helps your mental model/image, this idea is like Monte Carlo numerical integration of shapes within easy bounding boxes (but this is deterministic & points which pass are reported, not just counted) or importance sampling in statistics.
While this can allow for fast queries, it takes takes a long time and a lot of space to make a lengthenings table - comparable to thousands of linear scans of a large-ish correct word corpus. So, it is a useful strategy if you A) can save the big map to disk and very efficiently load it and/or B) have many queries to amortize build costs over. Rebuilding is lame (though what almost every other SymSpell impl does) while "real" DB query latency is hostile. So, this module does an efficient external file format with five files to "mmap & go":
A .tabl pointing to (keyIx->varlen.keys, .sugg=varlen[array[CNo]])
and a .meta(ix,cnt) file pointing to varlen .corp.
varlen[arr[CNo]] is an typical allocation arena with early entries the heads
of per-list-size free lists. The reason for 5 files not 1 is mostly just for
dynamic updating convenience, letting the file system allocate/grow each file
as needed.
I originally wrote this to understand and perhaps debunk SymSpell, though the
work has (sort of) validated it. Or not. Let you, dear reader, be the judge.
I think that I have at least found information I didn't see elsewhere that
brackets its applicability which is worth letting people know about. In
particular, SymSpell offers only modest speed-up vs-linear scan at large
(4,5,..) edit distances of a medium-sized (40 kWord) corpus, as shown in 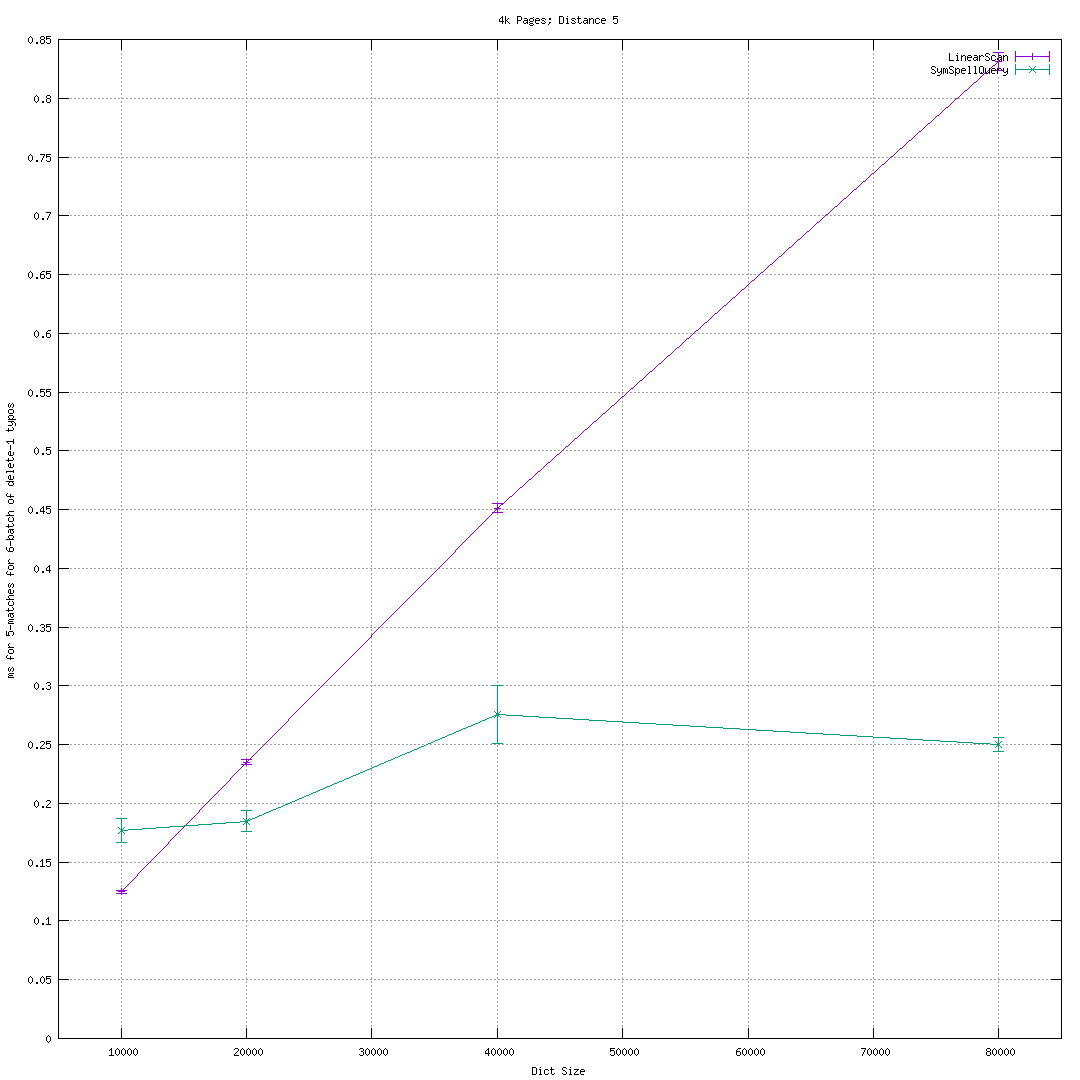 This does roughly contradict Garbe's "large distance, large dictionary" sales
pitch. False positive rates for d>3 probably makes that regime less interesting
in natural language settings. Still, SymSpell benefit remains only 7.3x-ish
for 80 kWord @d=3 which is not great. Indeed, parallel storage &
processing optimizations on both linear scan and SymSpell querying might even
nullify such a small advantage (the linear case has easily ensured work
independence while SymSpell has plausibly high L3 cache competition.)
This does roughly contradict Garbe's "large distance, large dictionary" sales
pitch. False positive rates for d>3 probably makes that regime less interesting
in natural language settings. Still, SymSpell benefit remains only 7.3x-ish
for 80 kWord @d=3 which is not great. Indeed, parallel storage &
processing optimizations on both linear scan and SymSpell querying might even
nullify such a small advantage (the linear case has easily ensured work
independence while SymSpell has plausibly high L3 cache competition.)
The basic experimental set up is to use "frequency_dictionary_en_82_765.txt" from the SymSpell repository as our input. We create synthetic "batches of typos" by sampling words from that very same distribution and then deleting one or more random characters. Create 2000 synthetic batches and feed these into a 'compare' mode of 'suggest' that times both a linear scan approach and an mmap & query SymSpell approach. The averages should thus be pretty representative. Batch size of 6 typos per document/user interaction felt about right, but typo rates probably vary a lot. The script is provided for users wanting to study how things vary. The error bars are the standard deviation of the mean. The distribution is wide with 95th percentile times often 4X the 5th percentile.
Both linear scanning and SymSpell querying have an additional optimization of shrinking the max distance passed to optimized edit distance calculators once "enough" correct suggestions have been found at lesser distances. This can speed up such distance computations somewhat, especially for linear scans of short words near popular portions of word-space or when very few matches are requested.
You can see the general scaling of SymSpell costs with max distance and
vocabulary size from 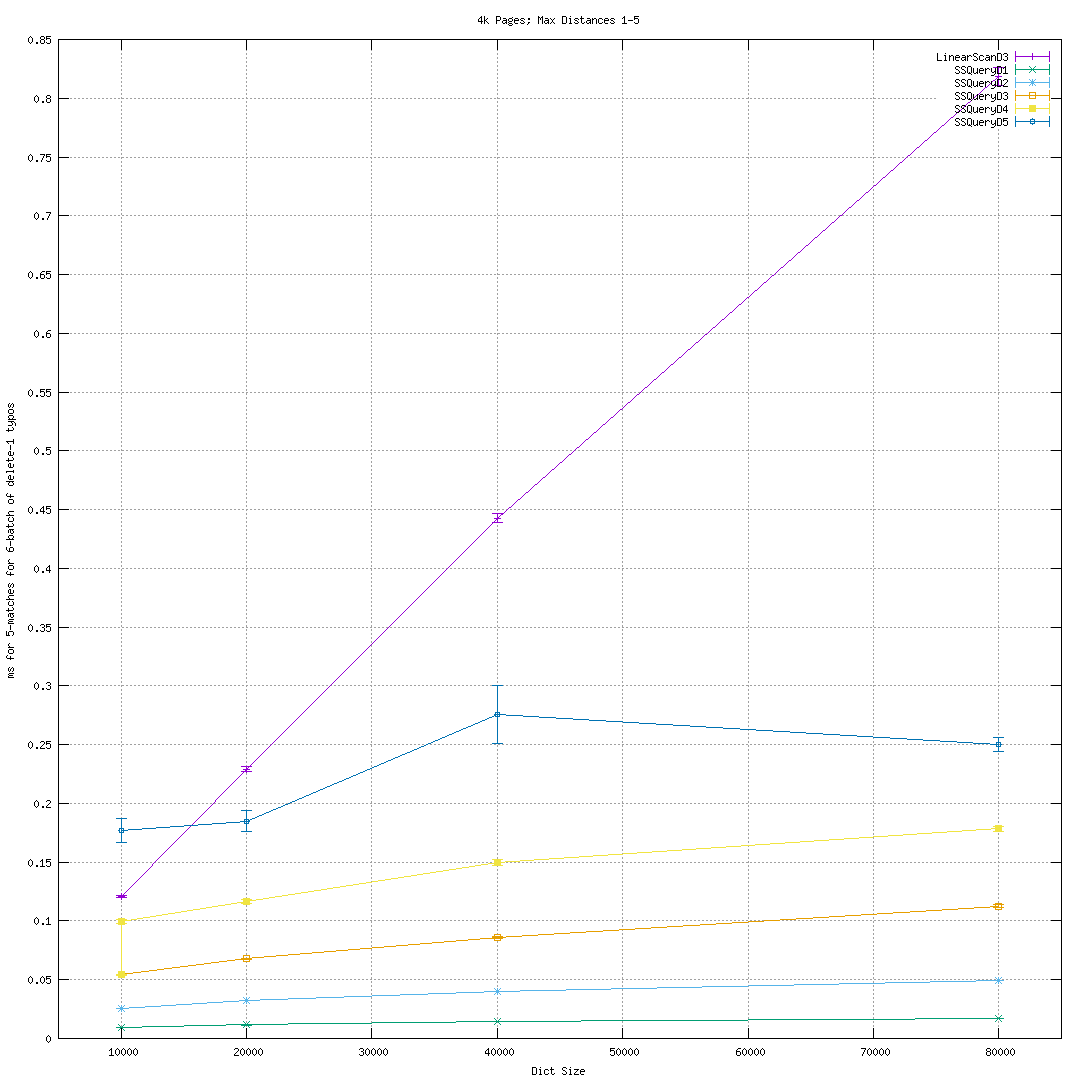
Along the way, I also found that SymSpell is a pretty good stress test for a some system-layer functionality - in particular memory allocators, string hash functions, and even virtual memory operation. Indeed, unless you really need that last 10x-50x speed boost from 100s of microseconds to 10s of microseconds, it is likely not advisable to try to implement SymSpell (at least without the systems layer warnings in this README). A simple linear scan of a corpus which has been pre-sorted by descending recommendation order is fast enough and very simple - you needn't even sort results. You simply bin them by edit distance.
For the curious about the systems layer problems, sensitivity to string hash functions is perhaps the most obvious. Because each key in the main table is formed by 1-deletions (and more) of other keys the amount of key similarity is an almost hash-attack level end-point. One doesn't quite need cryptographically secure hash functions, but almost any "weak but fast" will be defeated. The symptom is the usual one - long collision chains and slow operations on what is usually a gigantic table. My timing results use a variant of the late Robert Uzgalis' BuzHash that runs in (1.75 cycles + 0.63 cycles/byte). The default Nim hash also works all right, but will have not quite as good numbers. (For one, it's 4.3cyc+4.2 cyc/byte, but also not quite as randomizing.) I tried hard to have SymSpell be cast in the best light possible here, and that meant using the best hash. Similarly, I did not try to implement the prefix optimization that https://github.com/wolfgarbe/symspell discusses which slows things down a little at some significant memory savings. { In the years since I first wrote this, the default Nim hash has been updated to a faster, higher output entropy 32-bit murmur hash. }
The memory allocator problem comes from a long-tailed distribution of how many "correct suggestions" any given typo has. The distribution shape defeats most attempts to "speed-up" memory allocators with, say, "power of two" spaced region sizes. Almost any spacing besides the minimal one results in very low space utilization by suggestion lists. Indeed, an early non-persistent version of the code blew up most GCs that Nim offers. Only the Boehm-Demers-Weiser garbage collector actually allowing completion of a table build in reasonable time. Thankfully, minimal spacing is fast enough and we get 70% utilization or so.
Finally, while 4096 byte virtual memory pages are rarely a performance obstacle,
the size and access pattern of SymSpell queries is particularly hostile to use
from a fresh mmap. For larger dictionaries and distances <=~ 3, using 2M pages
so-called "huge TLB" pages resulted in >2x speed-ups for a "fresh mapping", as
can be seen in 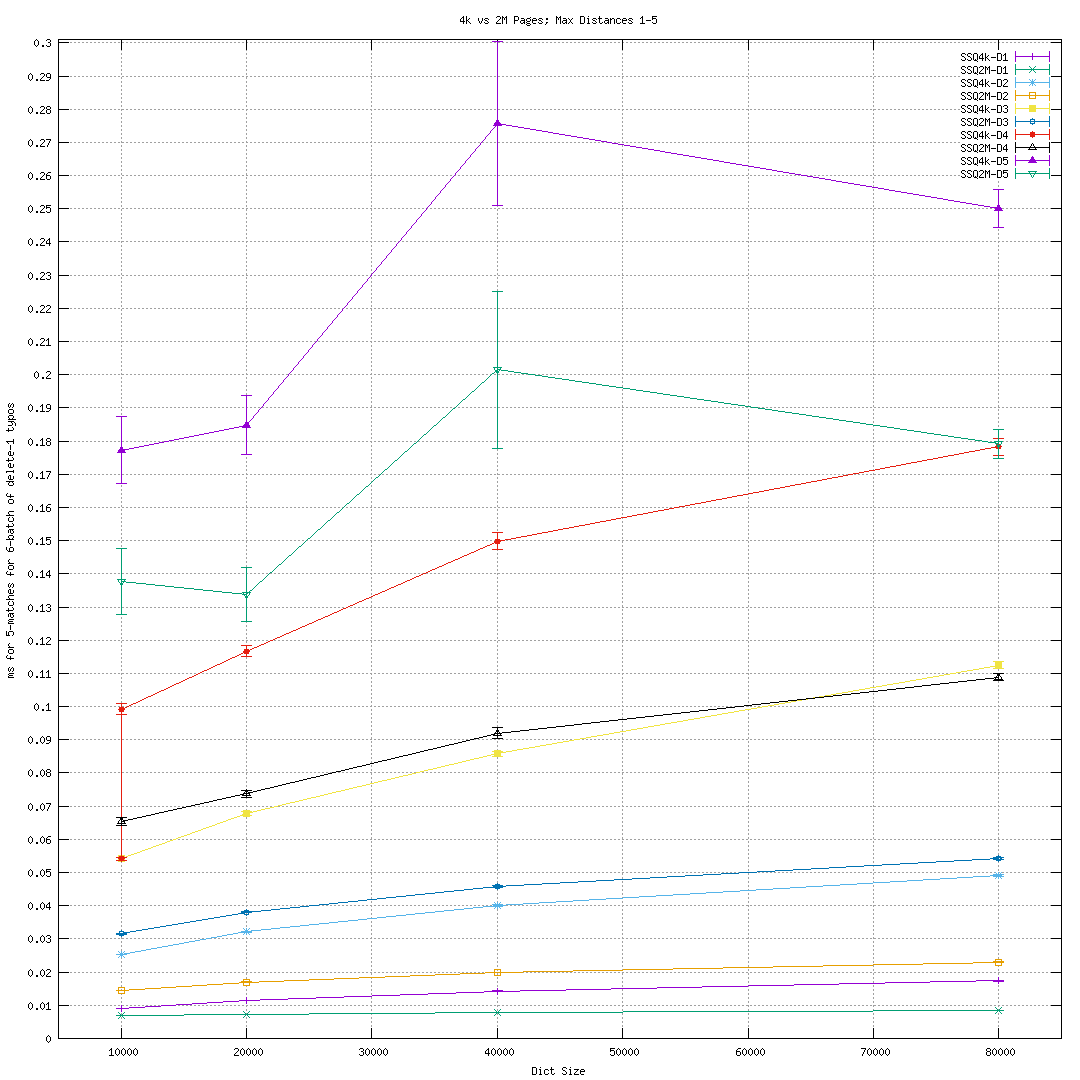 That relative speed-up of large pages does owe to the small absolute time
SymSpell queries take, of course, but still indicates many non-local 4k page
accesses (which will become relevant in later discussion).
That relative speed-up of large pages does owe to the small absolute time
SymSpell queries take, of course, but still indicates many non-local 4k page
accesses (which will become relevant in later discussion).
It also bears mentioning that table building time is still costly in this fairly optimized implementation. When using a Linux tmpfs RAM filesystem the resource usage looks like this:
maxDist dt(sec) size(bytes) Misspells dt(sec)Presized
1 0.182 19,456,529 647786 0.141
2 0.957 76,853,412 2562636 0.710
3 3.203 175,542,825 6852017 2.589
4 8.127 364,447,609 13981420 6.654
5 17.034 694,357,352 23487763 13.891
The final column is for when the table is clairvoyantly pre-sized perfectly to avoid hash table resizes. Some reasonably precise formula for the number of delete misspellings for a given (corpus, distance) might be able to provide this modest speed-up systematically. It is also unlikely that "less persistent" implementations can achieve much better build times.
Garbe claims significant space reduction for modest slow downs which might also help build times. About a 10x space reduction seems available using ideas from Karch, Luxen, & Sanders 2008 (https://arxiv.org/abs/1008.1191v2) following the work of Bocek, Hunt, & Stiller 2007 (https://fastss.csg.uzh.ch/ifi-2007.02.pdf).
The main take-away though, is just making concrete my "long time and a lot of space" from the introductory paragraphs. This puts real pressure on saving the answer of this build, especially for larger dictionaries with longer words. One really does need thousands of future queries before the investment in build time pays off in query performance. This natural "save the answer on disk" response to slow builds begs the question of cold-cache performance (say after a reboot), though folks familiar with systems under load might have lept to it.
To clarify the sense of "coldness" here, I mean only worst case run-times for queries on efficiently constructed tables. The "complexity theory" worst case (with, e.g., an attack on the hash) is so slow as to invalidate the entire table approach if it a real concern.
For a linear scan of just the corpus file, it is only 752,702 bytes and can be
scanned in 100..400 microseconds on modern NVMe storage fully cold-cache.
Cold-cache times for SymSpell, meanwhile, are bound by latency not throughput.
So they degrade dramatically on high latency storage like Winchester drives.
Every corrections query involves at least one, but sometimes hundreds or even in
rarer cases thousands of random accesses to the .tabl file for weakly related
keys. Arranging for locality to such accesses is challenging if not impossible.
For example, Cold-cache scanning on a 10 ms + 1e-5 ms/MB (aka 10 ms, 100 MB/s) Winchester drive or network storage unit would be approximately 10 + 1e-5*750e3 or about 17.5 ms - not great but under 100X slower than a fast NVMe time. Getting suggestions for multiple words can easily share that IO as well, making amortized per-word time for batch-of-6-typos more like 3 ms. Meanwhile, just one cold-cache SymSpell query on freshly opened data files could take 100s of random accesses or seconds (at 10 ms latencies).
We can measure this cost directly via getrusage instrumentation to measure
minor page faults. suggest iquery does this. In a cold cache scenario,
these would all be major 10 ms-ish faults with very little locality. Results
for a sample of 10,000 typos at various distances are 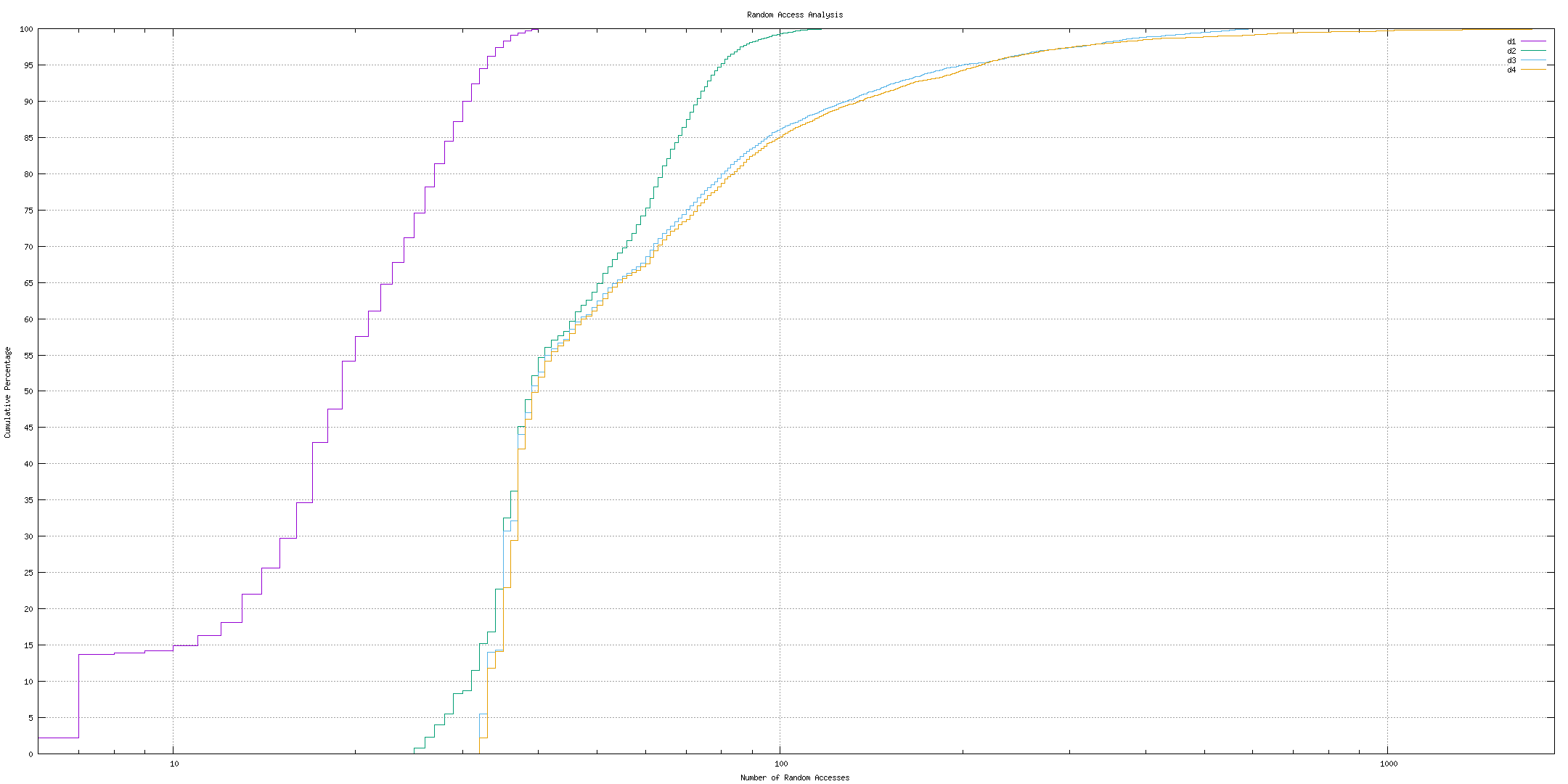 We see that for the fairly relevant d=3, 5% of the time there are 200+ accesses
and 1% of the time there are 373 accesses which translate to 2..4 seconds at 10
ms / access, 100..200x the 17.5 ms of a cold-cache linear scan. Running this
measurement against an actual 10 ms-slow device would be quite slow. This 10,000
sample case did 2870453 faults, which would be 287045 seconds which is 80 hours.
Even a 1000 sample case would take a good fraction of a day.
We see that for the fairly relevant d=3, 5% of the time there are 200+ accesses
and 1% of the time there are 373 accesses which translate to 2..4 seconds at 10
ms / access, 100..200x the 17.5 ms of a cold-cache linear scan. Running this
measurement against an actual 10 ms-slow device would be quite slow. This 10,000
sample case did 2870453 faults, which would be 287045 seconds which is 80 hours.
Even a 1000 sample case would take a good fraction of a day.
While multiple words in a linear scan share IO perfectly, this is not the case for the random access pattern of SymSpell IO. For the first batch of 6 off a cold cache, a fraction of a minute is conceivable for SymSpell and not very conceivable for a linear scan. Indeed, if multiple words are expected, the wisest SymSpell IO strategy is to get all the data paged into RAM via streaming IO (only 1.75 sec for the d=3 case @100 MB/s) before running queries.
This cold-cache scenario is yet another "system layer performance fragility" of SymSpell. Notice that linear scan's order 10s of ms cold-cache can now be 100x faster than SymSpell's seconds. Indeed the probability is order 50% that the first typo query will be 25x slower or worse than a linear scan as well as this time being in end-user noticeable regimes. Faster storage than 10 ms + 1e-5 ms/MB storage like SSDs and NVMe is more common these days, but even so..to keep SymSpell a performance winner in deployment, one must ensure cached pages.
Of course, the above commentary also applies to non-persistent SymSpell implementations in execution environments where swap/page files are possible. Competition for memory is usually beyond the control of the authors of any single components. Pre-paging non-persistent data can be more involved than "cat spell.* > /dev/null" as in a persistent variant. SymSpell's large memory requirements make it likely one of the fiercer memory competitors.
There are of course system facilities to help with this problem such as mlock
and MAP_LOCKED and such (also a bit easier to use with persistent files than
volatile "language runtime" data structures), if the developer even thinks to
use them. [ They may also require CAP_IPC_LOCK or superuser privileges. ]
The TL;DR? While a well-implemented SymSpell with a well guarded deployment environment can indeed be always faster on average than a similarly well done linear scan, it is far more "performance risky" without a variety of cautions. It may be 10-100x faster than a linear scan in some hot cache circumstances or 10-100x slower in cold-cache/worst case circumstances. Meanwhile, a cold-cache linear scan might be only about 20x worse than a hot-cache linear scan while for SymSpell cold vs hot could be 10000x different. In those terms, SymSpell is 500x more performance risky than a linear scan, not even considering things like allocator and hash function implementation risk and parallelization.
The TL;DR;DR? "YMMV from hell". ;-)