flatMap and flow-based programming in Highland #371
Comments
|
You can't loop streams like that. In general, you can only directly write to streams that were created with no source (i.e., I'm not sure exactly what you want to do, but here's a way to do recursion on the stream. It acts a lot like rewrite rules in a context free grammar. For each item, you decide whether or not to replace it with one or more values until you reach the terminal value. function rec(x, count) {
if (x % 2 == 1 || count > 8) {
return _([x]); // terminal case
} else {
// rewrite rule.
return _([x - 1, x * 2, x - 1]).flatMap(function (y) {
return rec(y, count + 1);
});
}
}
rec(2, 1).each(_.log);This outputs I might be of more help if you give a little more detail about what you're trying to do. |
|
Victor, thanks for your response. That makes sense. It seemed intuitively dirty. A little more on what I'm trying to do. There is a programming paradigm called Flow Based Programming where you build functionality with graphs. This is perfect for Big Data scenarios for stream processing, ETL, and cloud automation. NoFlo is a Node.js implementation that inspired me. Nifi is a similar Apache Incubator proejct. As an example, NoFlo implemented Jekyll, a static site generator, using this approach. Image below. It's interesting to see how they implement a recursive directory reader. The list of files that come out of the directory reader simply get filtered for directories and piped back into the directory reader. In my quest to implement this simple recursive reader, I found it challenging to pipe data back into itself. The big question I have is whether or not Highland is a good fit? I feel that it is because it handles back pressure well.. The code below actually works but being a Type-A developer, I get obsessed with doing things right since I plan to build upon this concept. |
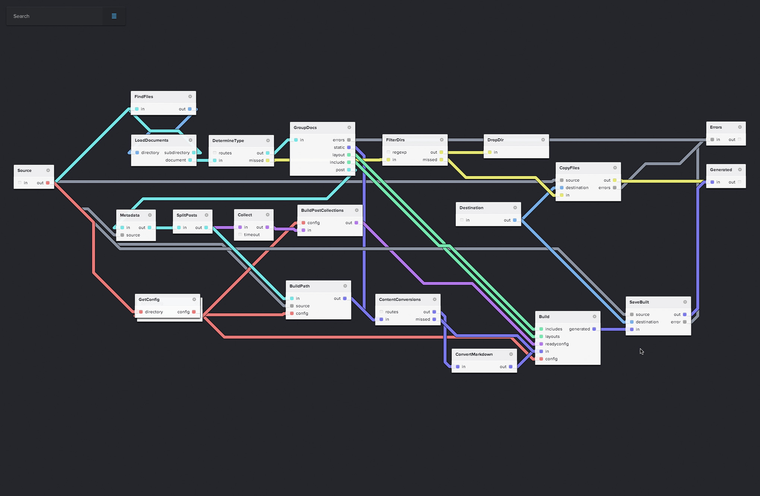
|
I got this to work without var directory = _(['/home/vqvu/Desktop']);
var mergePoint = _();
var dirFilesStream = mergePoint
.merge()
.flatMap(function (parentPath) {
return _.wrapCallback(fs.readdir)(parentPath)
.sequence()
.map(function (path) {
return fsPath.join(parentPath, path);
});
});
var out = dirFilesStream;
// Create the return pipe without using pipe! See below for why.
var returnPipe = dirFilesStream
.observe()
.flatFilter(function (path) {
return _.wrapCallback(fs.stat)(path)
.map(function (v) {
return v.isDirectory();
});
});
// Connect up the merge point now that we have all of our streams.
mergePoint.write(directory);
mergePoint.write(returnPipe);
mergePoint.end();
// Release backpressure.
out.each(_.log);Note that I'm not using I'm not using You have to use
Hence, a deadlock. Backpressure is working against you here. The reason why your code worked only when you call It may seem like using The only non-ideal behavior relates to What you really need is a custom I think this is a cool and novel use case (novel to me anyway) for Highland, so I'm interested in hearing what general functionality we can add, beyond those mentioned in this post, to make it easier. Why we can't use
Most of the time this is OK, since the method returns a different stream that you can consume. In this case, however, you want to pipe to Edit: |
|
Wow, that was an impressive response, I had to read through it a few times. Thank you so much for taking the time Victor. I think Highland needs a litany of examples like this to help people better understand how it works. There are several important concepts that I learned just by reading through your code. I'm hoping that once I have a small arsenal of these concepts that I can build out the flow models. |
|
Oh, no problem. It was a really interesting exercise for me. I've never considered routing a stream back on itself like this before. So I learned something too. I hope you get to where you want with the flow models. If you find some general feature that would help reduce boilerplate/improve functionality, let us know. I think this is quite a powerful concept, so having some direct support in the library for the paradigm would be good. I totally agree with you about the examples. We've always talked about having a Highland "cookbook", but I've personally never had the time or motivation to sit down and actually do it. Answering targeted questions like these are much more fun. Though, I bet if someone were to go through all of the old issues and extract the code samples from them, we'd be most of the way there. |
Ditto. One thing that constantly comes up in issues is people not getting the usefulness of |
|
Heys, guys. Is there a simpler way to solve this? The script I'm working on has to request data from an API in pages, hence the need for recursion i.e. repeated requests until completion. Simplicity (or readability) is precisely what I was longing for with highland, but doing this with promises and recursion seems much simpler. Thank you very much for your time. |
|
It depends on what exactly you're trying to do. If all you're doing is requesting for data and feeding the result to some processing code, then promises may indeed be simpler. function query(url, page) {
// Assuming doRequest returns a promise.
return doRequest(url, page)
.then(result => {
var res = process(result);
if (result.nextPage) {
res = res.then(ignore => query(url, result.nextPage));
}
return res;
});
}
// Use like this.
query(url, 1)
.then(arg => console.log("I'm done!"));If you want a stream of pages that you'll then perform stream operations on, you can do it... iteratively: function query(url) {
var page = 1;
return _((push, next) => {
if (page != null) {
// Assuming doRequest is a node-style callback function.
doRequest(url, page, (err, res) => {
push(err, res);
if (!err) {
page = res.nextPage;
next();
} else {
page = null;
}
} else {
push(null, _.nil);
}
});
}
// Use like this
query(url)
.map(...)
.otherTransform(...);or recursively: function query(url, page) {
return _((push, next) => {
// Assuming doRequest is a node-style callback function.
doRequest(url, page, (err, res) => {
push(err, res);
if (!err && res.nextPage) {
// next(stream) basically delegates to the specified stream.
// It emits what the specified stream emits.
next(query(url, res.nextPage));
} else {
push(null, _.nil);
}
}
});
}
// Use like this
query(url)
.map(...)
.otherTransform(...);There's no one-liner for doing it though. |
|
@vqvu thank you very much. I thought "Flow-style" was the only way to use recursion in streams and I got scared LOL. This issue got me interested and I've made a programming exercise out of it: Comparing multiple ways to solve the recursive directory listing problem. You can check it in this gist. There are three solutions using streams, and of course there are still infinite more. It'd be AWESOME to get feedback, folks :) Avoiding Stream-forks makes up for less code, not sure if more readable though. Thank you. |
|
@vqvu thank you for the detailed explanation and example. I have a question regarding the end of those streams. When I change the last line to the following, it doesn't print the 'done'. I am working on a code based on the snippet above that has a more complex dirFilesStream (with batching etc.) and am running into the problem that my process does not terminate even after all the streams stop producing data. |
|
I know what the problem is, but I don't know how to fix it. Here's the problem:
The problem is essentially that the recursion can't detect the base case (i.e., when there are no more directories). Because of asynchrony, it's difficult to tell the difference between "no more data" and "no more data right now, but more data is being produced". I don't know enough about flow-based programming to be able to tell you if this is an inherent issue with recursive networks or if it is simply a problem with this particular construction. You may be better off implementing the directory walk recursively as a single transfrom rather than via the flow-based approach. |
|
Thank you, I had an idea it is something like that. Unfortunately my problem is not a directory walk. It is closer to the web request example above, but it needs batching and rate limiting, so the returnPipe approach would have been more elegant. |
|
I thought about it some more, and there's a way to do recursion while still maintaining the It doesn't look like a flow network but accomplishes the same thing. // Applies a transform to the stream if it is not empty.
// The reverse of `otherwise`.
function ifNotEmpty(transform) {
return function (stream) {
return _(function (push, next) {
stream.pull(function (err, x) {
if (err) {
push(err);
next();
} else if (x === _.nil) {
push(null, x);
} else {
var nextStream = _([x])
.concat(stream)
.through(transform);
next(nextStream);
}
});
});
}
}
// Recursion transform.
// transform - The main transform.
// computeReturnPipe - A transform that computes what data to feed back
// into the recursive system. It is provided with the result of the
// main transform.
function recurse(transform, computeReturnPipe) {
return function (stream) {
return stream.through(recurse2)
.flatten();
};
function recurse2(stream) {
var output = transform(stream);
var moreData = output.observe()
.through(computeReturnPipe)
.through(ifNotEmpty(recurse2));
return _([output, moreData]);
}
}
function readDir(stream) {
return stream
.flatMap(function (parentPath) {
return _.wrapCallback(fs.readdir)(parentPath)
.sequence()
.map(function (path) {
return fsPath.join(parentPath, path);
});
});
}
function filterDir(stream) {
return stream
.flatFilter(function (path) {
return _.wrapCallback(fs.stat)(path)
.map(function (v) {
return v.isDirectory();
});
});
}
_(['/home/vqvu/Desktop'])
.through(recurse(readDir, filterDir))
.each(_.log)
.done(function () {
console.log('done');
});Edit: |
|
The above assumes that the base-case is an empty stream, so it is perhaps not quite as general as the flow-based approach. Specifically, it doesn't work if the This assumption is what allows the stream to detect when there is no more data. |
|
Thank you! I will have a closer look at this, will take me a few days to implement with my specific problem. |
|
This works great! Definitely cookbook worthy :-) One minor detail (just to not confuse anyone looking at the code above): In the comment under "Recursion transform" you call the first argument transform but in the code it is called process |
Oops! Fixed. |
In this contrived example, I loop the output stream of the input back into itself creating a recursion-like behavior. It produces 1, 2, 4, 8, 16, 32, 64, 128, 256, 512.
This doesn't seem to work if I use a flatMap. It will only print out the first value, 1. My goal here is that I would like to return multiple values for each input value.
Is this a bug or is there something I need to do differently when using a flatMap?
The text was updated successfully, but these errors were encountered: