This work uses deep convolutional neural networks and other ML and computer vision techniques to extract player detection and mapping data from NHL broadcasts.
To make an open source platform that can injest broadcast footage of hockey games and output player mappings as well as other useful information harvested from these frames. This is an ongoing project. Failing fast, learning new techniques/architectures/libraries and proving concepts are prioritized over designing highly accurate networks.
This project consists of 3 main stages: data collection, object detection and homography generation.
Training was done on 2 seperate AWS ML AMI p2 XL instances.
Generating labelled data for the training of the relevant networks meant finding/designing labelling tools as well as an efficient data pipeline for storing and updating these pieces of data in a distributed manner.
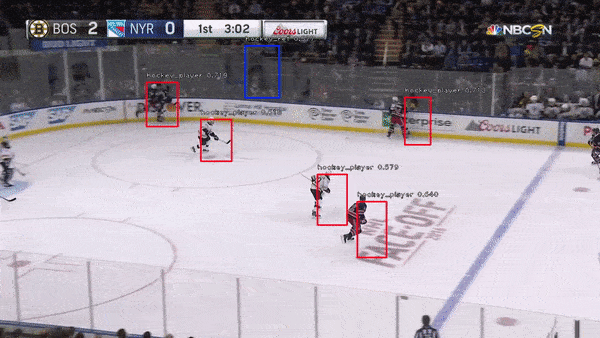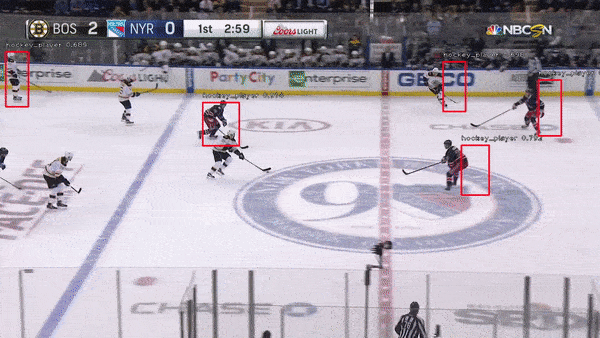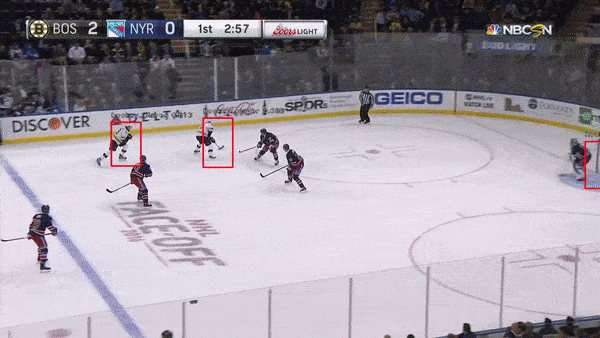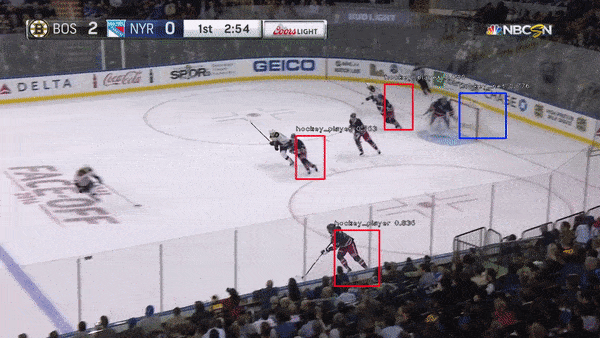
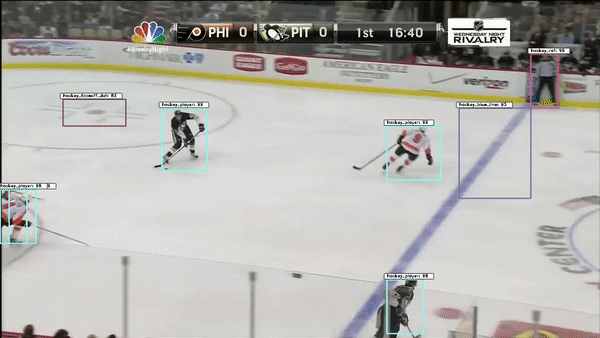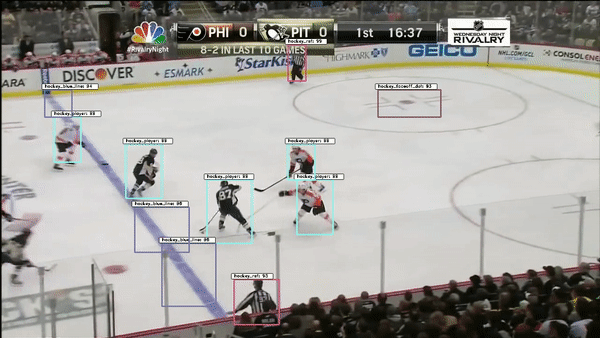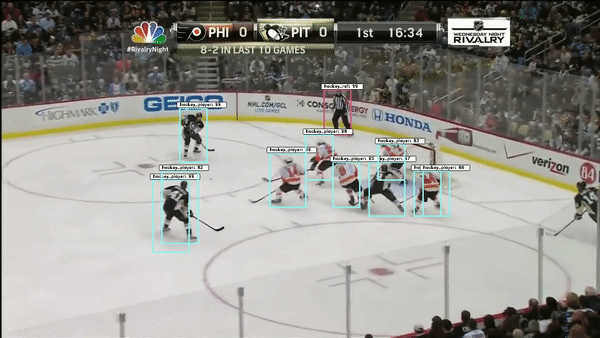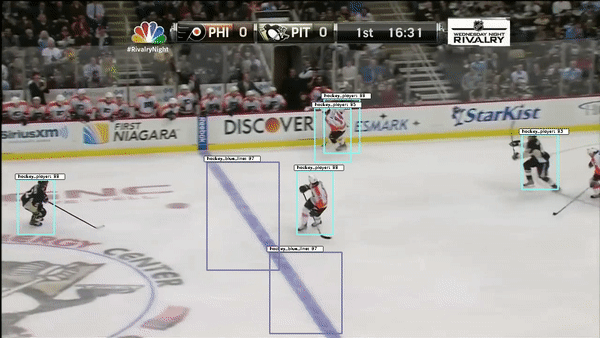
The object detection network requires bounding boxes and labels for relevant hockey objects. For our purposes, these objects were: hockey_player, hockey_ref, hockey_goalie, hockey_blue_line, hockey_middle_line, hockey_end_line, hockey_goal and hockey_scorebug. For generating these labels and boxes, labelImg was used. This made it simpler to drag the boxes, but the annotation files it generated were in XML (so I converted them to JSON). Then, in order to decrease the work it took to generate labelled data from consecutive frames, a custom python script was written. This script takes 1-3 seconds worth of input frames and interpolates the position of bounding boxes based on the bounding boxes of the first and last frame. Hockey players change pose relatively quickly, so this approach helped to generate labels on these many different poses.
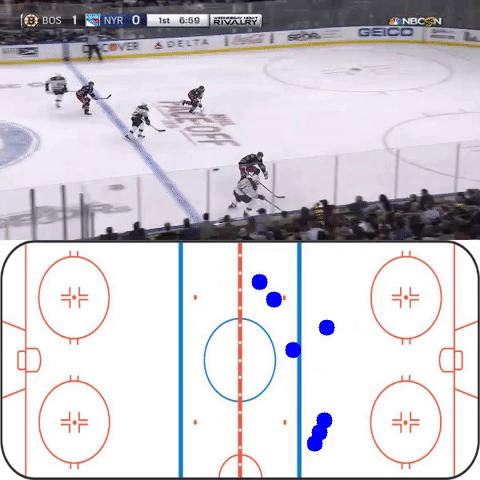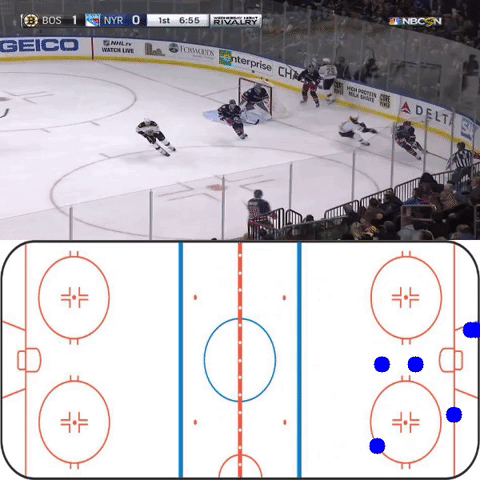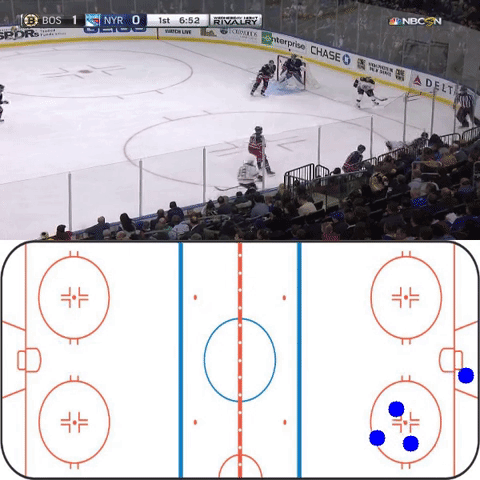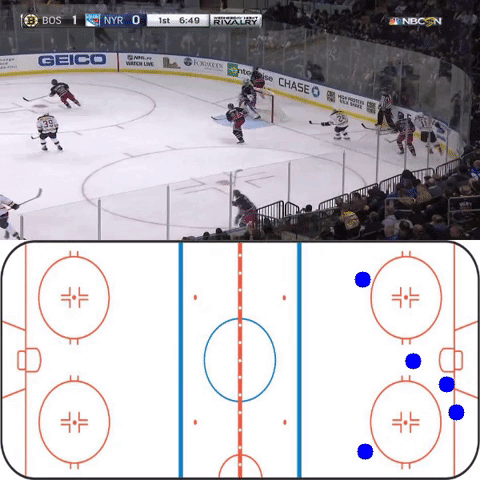
In order to address the challenge of predicting homography matrices when given a frame, I collected frames portraying a range of camera angles and hockey scenes. These were labelled with a 9-wide homography vector which was generated using a custom built python tool which allowed to drag lines between corresponding points (see below).
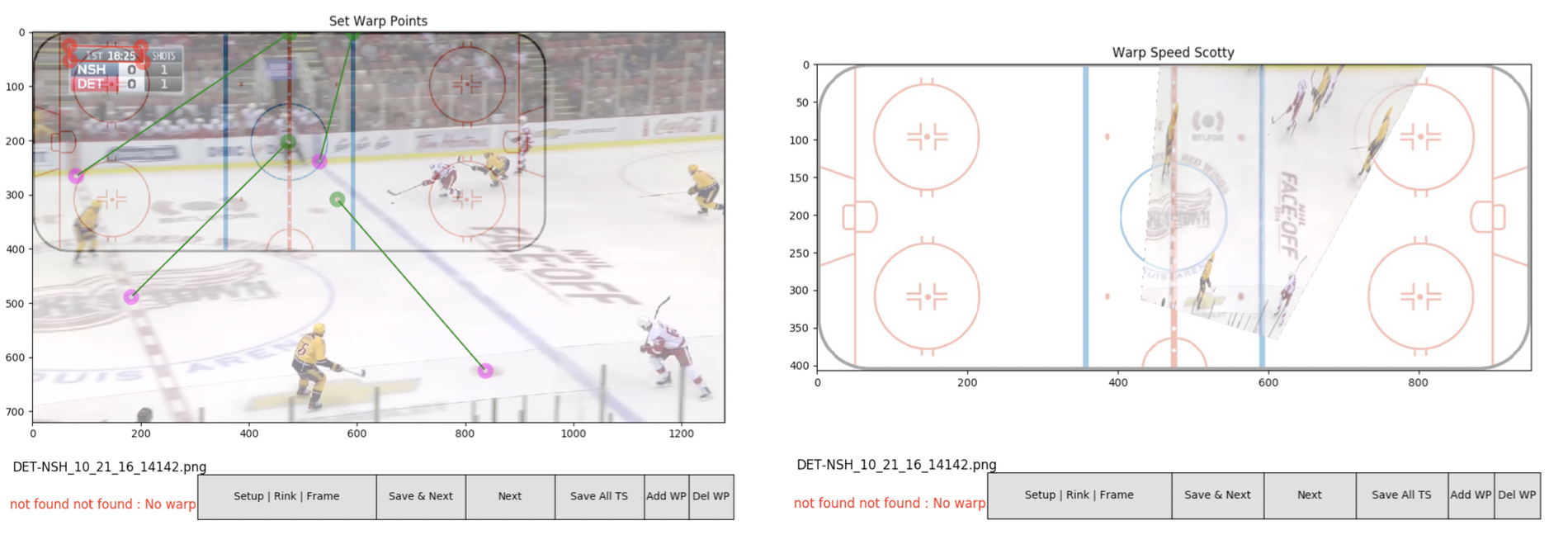
The data pipeline was built using AWS S3 service.
Object detection is accomplished using a retinanet architechture with a ResNet backbone. Transfer learning was performed starting from Imagenet weights.
A second object detection network was trained with improved results. This network used a Faster RCNN architecture with the same resnet backbone. The improvement in results could be due to differences in the network architectures, though retinanet should match or exceed the accuracy of FRCNN. More likely, the difference in performance could be attributed to a more effective image augmentation pipeline in the FRCNN training.
Multiple attempts have been made at predicting homography matrices from broadcast frames and many have suffered from severe overfitting problems. First, an InceptionV3 image classification network was chosen. The top was removed and replaced with a 9-d fully connected regression layer. This simplistic attempt suffered from significant overfitting. This overfitting is no doubt due in large part to the size of the data set. The process of labelling homography matrices is time intensive and thus, with limited time and funds, the dataset grew slowly. While a small dataset can be used when transfering from imagenet towards identifying hockey players, the problem of predicting homography matrices is not as similar to the imagenet classification challenge; the learned filters do not transfer as readily and thus more training data is necessary in order to get meaningful results.
Dropout layers were introduced, but little improvement occured. The deeper Inception layers were removed with the hope that a less complex network would be less prone to overfitting but this also did not help very much. The network was trimmed down to become simpler and simpler, but with little effect.
More efforts were made to improve on this overfitting problem. While incresaing the size of the dataset takes tremendous time and effort, efforts can be made to overcome other sources of overfitting. It was assumed that features of the on-screen players could be influencing the decision of the homography network. Since this network is meant to generate a translation between the on screen 2D ice surface and a map of hockey rink, the position of these players would ideally be ignored. Thus, a network was retrained using a color filtered version of the database. This filtering attempted to highlight the standard markings of a hockey rink, and, in so doing, ignore some of the features of the hockey players. Alas, this approach still did little to improve upon the overfitting issue.

On certain cherry-picked scenes where features line up well with the features of the training data, the homography network performs as intended (though it is more jittery than would be preferred). (Video is downsampled)
Future improvements for this project include
- Developing a working system for generating homography matrices for arbitrary broadcast frames
- Ideas include: using intermediate images to find correct homography. Perform a Random Sample Consensus algorithm between a new image and a labelled image. RANSAC will allow us to find a homography between these two, and to translate player locations to this frame's space. Then the homography matrix of that image can be used to convert to map-space.
Contributions, ideas, feedback all appreciated.