We develop an efficient verification algorithm that can give tight lower bounds on robustness for decision tree ensembles (specifically, gradient boosted decision trees). Our algorithm can be hundreds of times faster than the previous approach that requires solving mixed integer linear programming (MILP), and is able to give tight robustness verification bounds that are close to MILP results (the gap is commonly less than 30%) on large GBDTs with hundreds of deep trees. Additionally, our algorithm allows iterative improvement to get tighter bounds, and can converge to the optimal MILP solution eventually.
Our verification tool is compatible with XGBoost. You can use our tool to verify the robustness of any XGBoost models, including those trained using robust GBDT training method proposed by Chen et al.
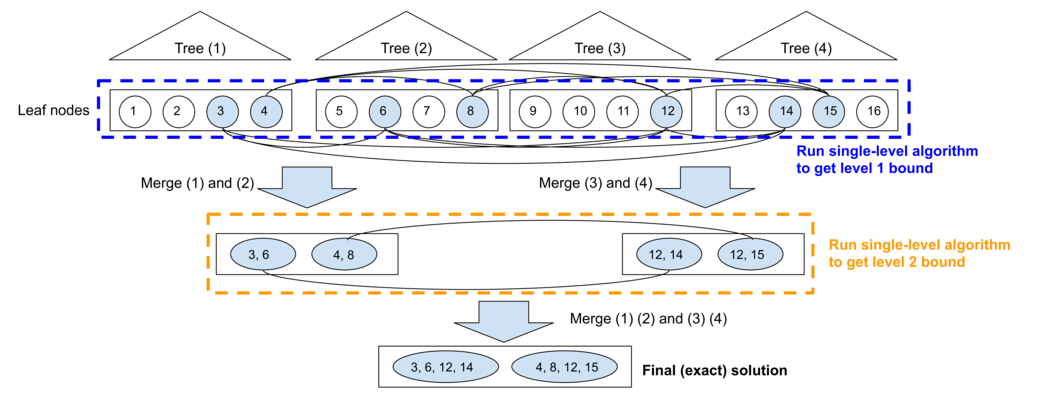
At a high level, we formulate robustness verification problem of tree based models into a max-clique enumeration problem on a multipartite graph with bounded boxicity. We develop a hierarchical scheme such that the max-cliques are enumerated in a level-by-level manner, which allows us to quickly find lower bounds of the robustness verification problem.
git clone --recurse-submodules https://github.com/chenhongge/treeVerification.git
cd treeVerification
# install dependencies (requires libuv and libboost)
sudo apt install libuv1-dev libboost-all-dev
./compile.shAn executable treeVerify will be created.
First, you need to dump a XGBoost model into JSON format. This can be done
using the dump_model function in XGBoost and set dump_format='json'.
See XGBoost documentation here.
Then, you need to provide a LIBSVM format dataset that is used for robustness evaluation. Typically, we use the test set to evaluate model robustness.
Now setup a configuration file. example.json provides a basic example for a 8-tree
GBDT model trained on the breast_cancer dataset (included in this repository).
We also include the dataset in the repository so you can start playing with our code
immediately. See next section for details of each
option in configuration file.
Lastly, run ./treeVerify example.json to evaluate model robustness. At the end of
program output, you will find verification results:
clique method average bound:0.39518
verified error at epsilon 0.3 = 0.13
The "verified error" is the upper bound of error under any attacks. In this example, we can guarantee that within a L infinity distortion norm of 0.3, no attacks can achieve over 13% error on test sets. The "average bound" is the lower bound of minimum adversarial distortion averaged over all test examples. A larger value typically indicates better overall robustness of the model.
The configuration file has the following parameters:
-
inputs: LIBSVM file of the input points for verification. Typically the test set. -
model: A JSON file produced by XGBoost, representing a decision tree or GBDT model. -
start_idx: index of the first point to evaluate. -
num_attack: number of point to be evaluated. We evaluatenum_attackdata points starting fromstart_idxin theinputLIBSVM file. -
eps_init: the first epsilon in the binary search. This epsilon is also use to compute verified error. If you only need to get the verified error at a certain epsilon, you can disable binary search by settingmax_searchto 1. -
max_clique: maximum number of nodes in a clique, usually set to 2 to 4. -
max_search: maximum number of binary search for searching the largest epsilon that our algorithm can verify. Usually set to 10. If you only need to get the verified error at a certain epsilon, you can disable binary search by settingmax_searchto 1, and seteps_initto the epsilon you want to evaluate. -
max_level: maximum number of levels of clique search. A larger number will produce better quality bounds but the verification process becomes much slower. Usually set to 1 to 2. -
num_classes: number of classes in dataset. -
dp: use dynamic programming to sum up nodes on the last level. Optional. Default is 0, which means DP is not used, and a simple summation is used instead. -
one_attr: the only feature allowed to be perturbed (used to reproduce our experience in Figure 4). Optional. Default is -100, which disables this setting and assumes all features are perturbed. -
feature_start: the index of the first feature. Optional. Default is 1. Some LIBSVM files might have a different starting index, for example, 0. In this case, you need to correctly set this configuration for correct verification.
We provide all GBDT models used in our paper at the following link:
wget http://download.huan-zhang.com/models/tree-verify/tree_verification_models.tar.bz2
tar jxvf tree_verification_models.tar.bz2where you can find all the JSON model files (dumped from XGBoost) used in our
experiments inside the tree_verification_models folder. Subdirectories named
with "robust" include models trained using the robust GBDT
training method by Chen et al., and
"unrobust" models are trained using regular XGBoost.