带有舒适的 “发送请求” 以及 “代码生成” 功能(能生成 scrapy 或 requests 的请求标准代码)
1) 【工具发请求】 可以在工具内直接执行请求,请求后可以快速检查数据。
2) 【代码标准化】 启用代码的标准化,让请求能够在请求时规避掉一定程度上的异常,让新手更加容易生成代码
将代码标准化可以显著减少每次手写代码可能存在的风险。
另外工具生成的代码中还能自动解决部分新手或老手一时间无法理解的几个问题。
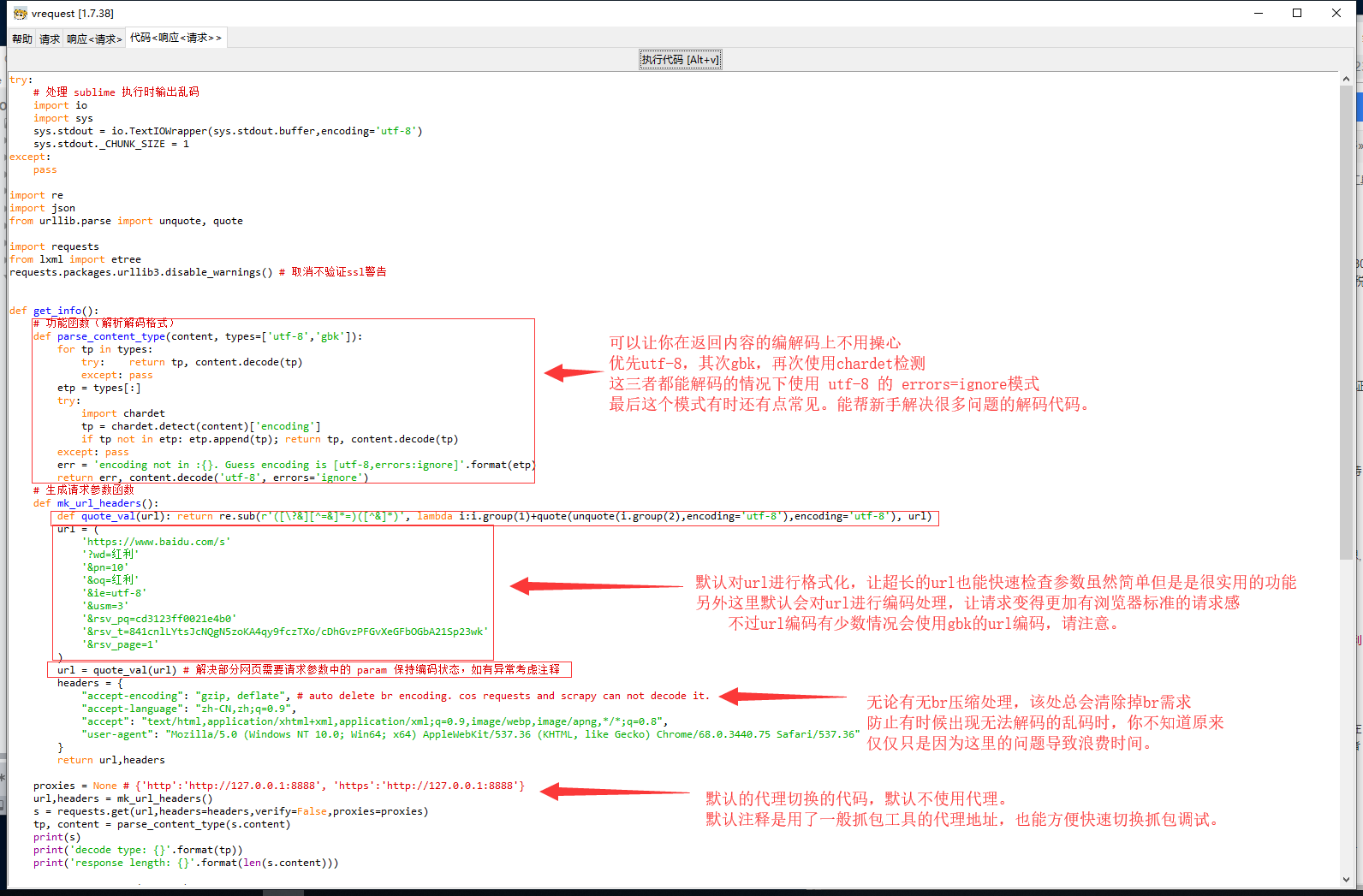
(1) 自动对 url 进行编解码的处理,防止一些网站一定需要 url 编码后才能请求到数据的异常。
(2) 自动处理 scrapy,requests 代码无法直接解析 br 压缩格式,会在自动清除 br 压缩要求
(3) 自动处理古老服务器加密标准中禁止ssl验证仍抛出 ssl(dh key too small) 异常的补丁代码
(4) 生成代码自动增加 twisted 在非标准返回头信息的处理上出现异常的补丁代码
...
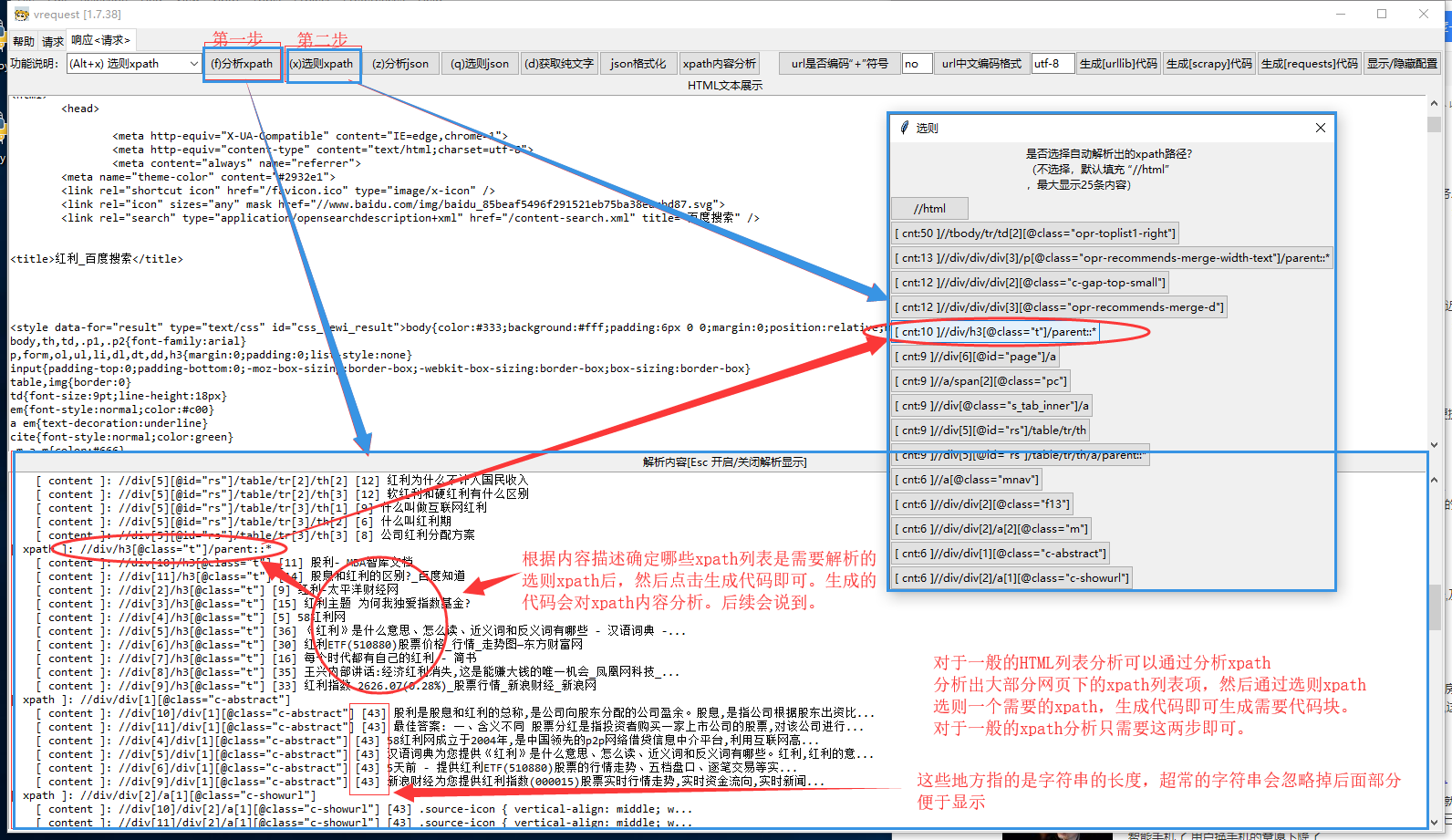
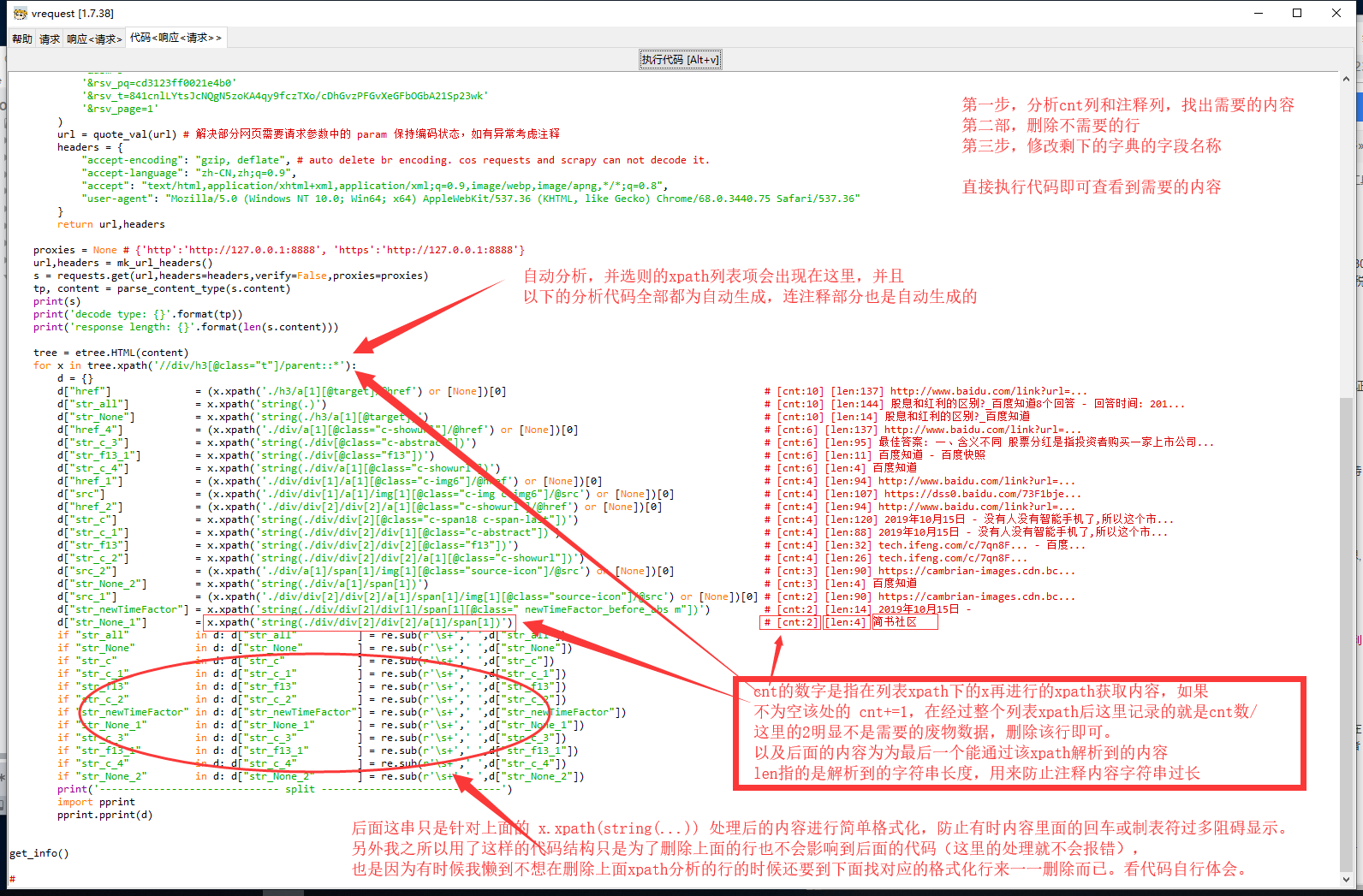
3) 【自动解析器】 工具内发出请求之后可以通过工具自带的分析器,直接对 xpath 解析
通常情况下,爬虫绝大多数的请求分析都出现在列表分析上面,
所以该工具为了更加方便增加了自动 xpath 列表解析以及 json 列表解析的功能。
分析后的结果在生成代码的时候会保留在代码里面!!!
(1) 快速处理 HTML 文本的 xpath 解析,并且分析后的结果会呈现在代码里!!!
(2) 快速处理 json 结构的列表路径解析,分析后的结果在生成代码时能呈现在代码里!!!
(3) 快速处理纯文本,大约是先清除掉 script 等非目标文本结构后再进行 xpath 语法中的 string 函数
同样在使用该功能后能呈现在代码里!!!
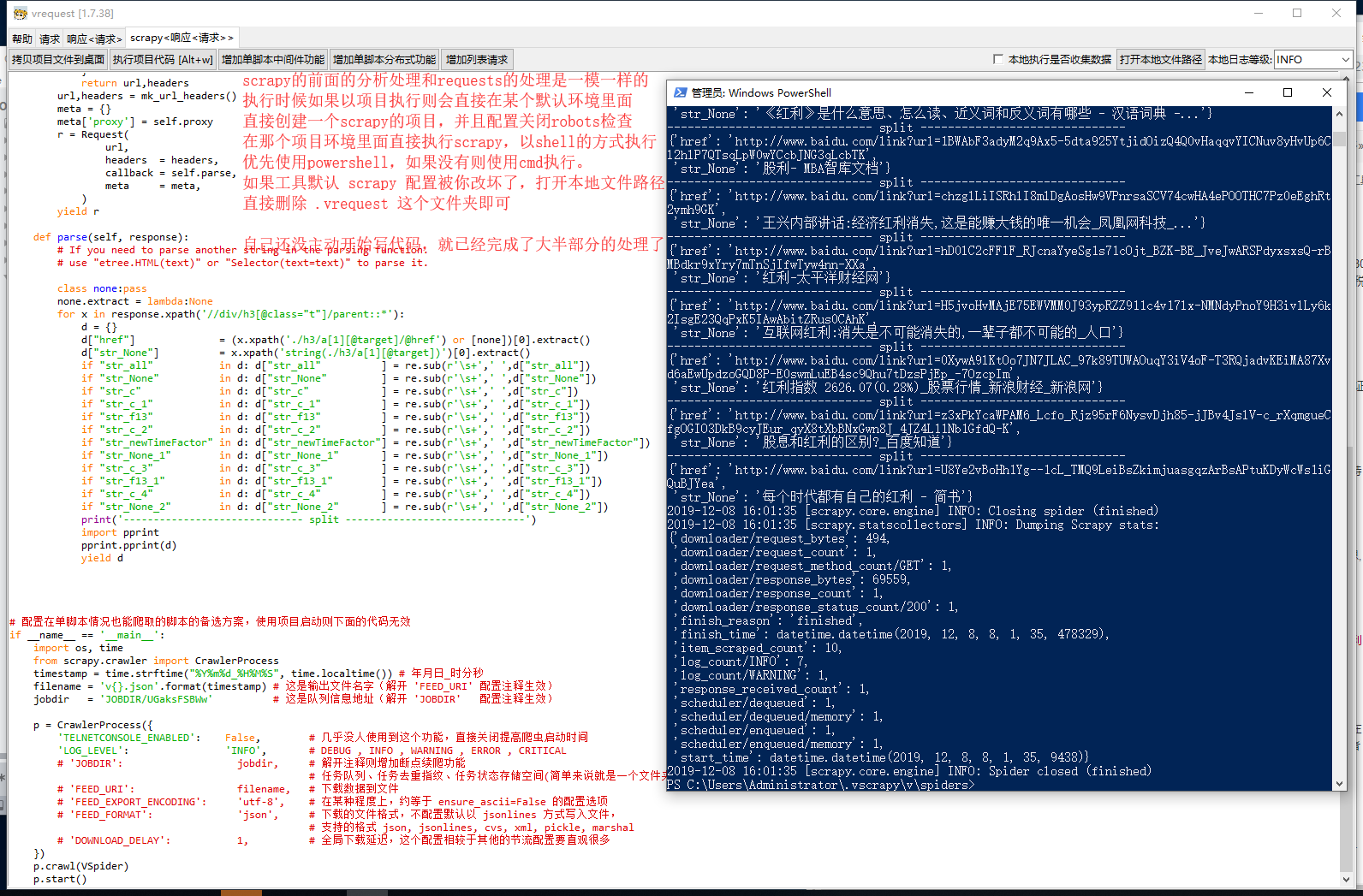
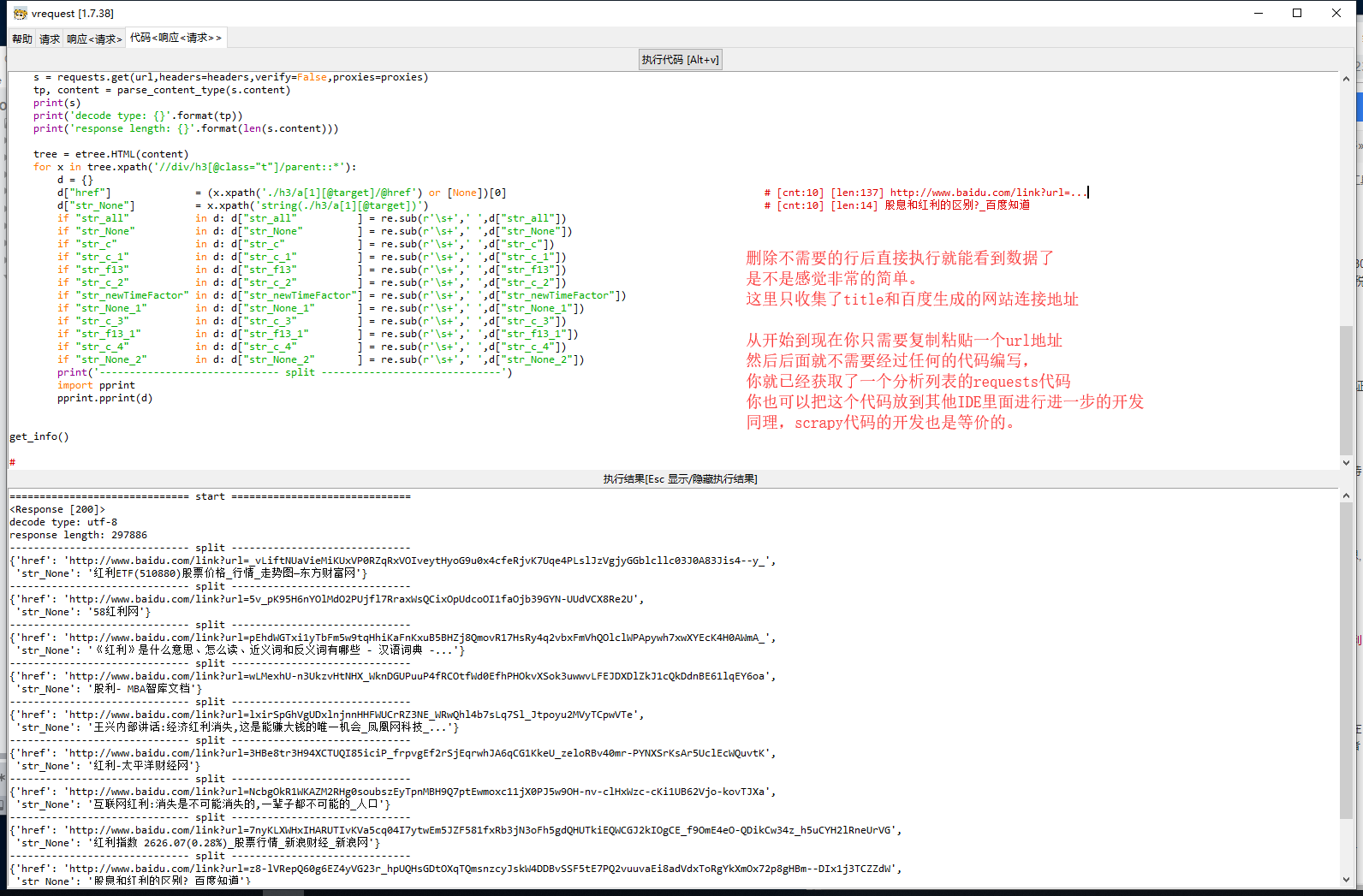
4) 【直接执行代码】 你能够在该工具内直接执行代码
能直接执行代码就代表着,大多时候你只需复制粘贴一个 url,就能生成代码(因为生成请求框会带有默认请求头信息)
然后直接就能执行 scrapy 项目的代码,直接就能执行 requests 的脚本代码。非常方便
(1) scrapy 能直接以新的 shell 执行项目脚本代码(其他的配置均为scrapy默认配置,除了ROBOTSTXT_OBEY设置为False)
(2) requests 能直接执行代码脚本
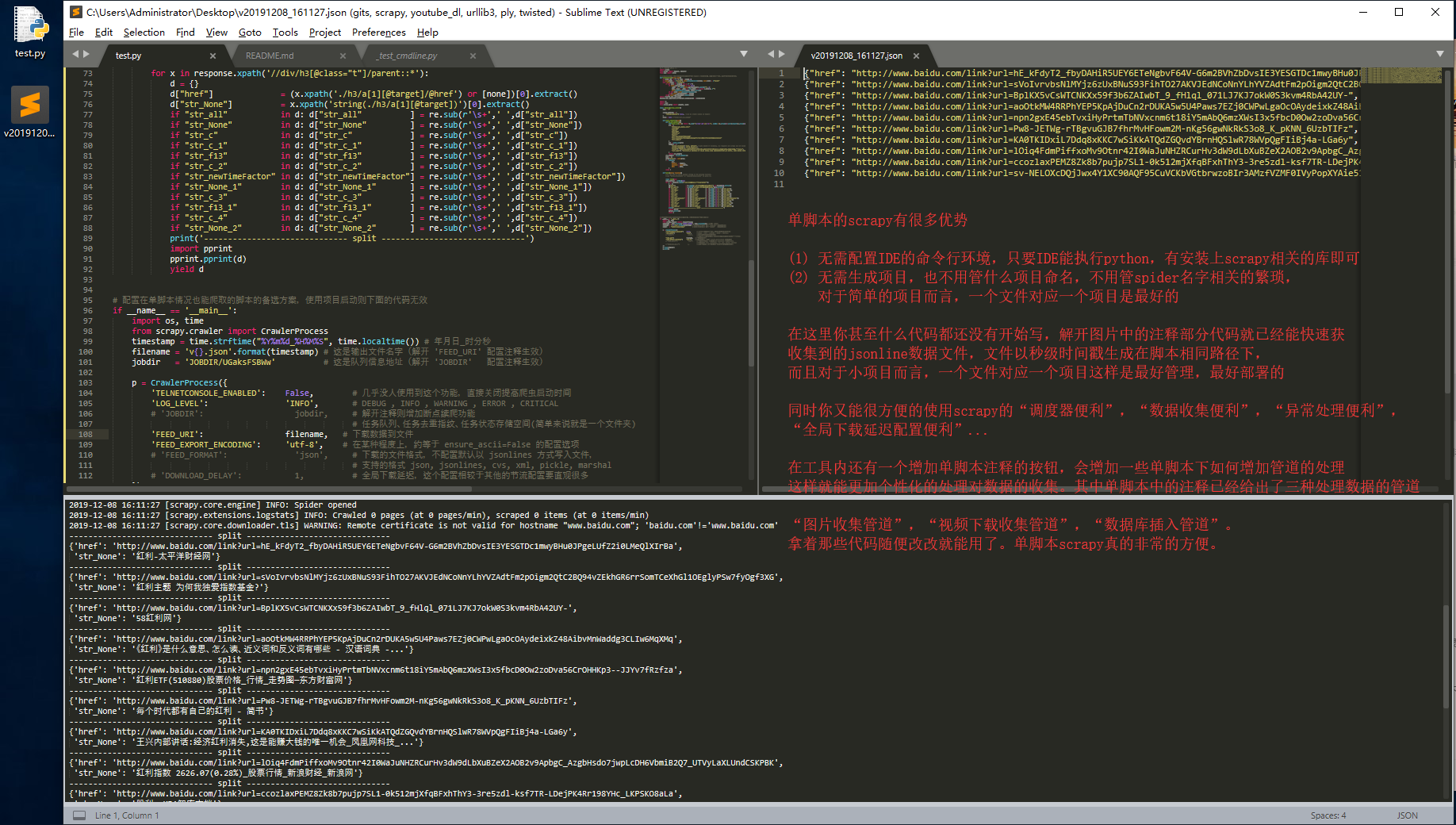
5) 【scrapy红利】 由于作者是靠 scrapy 吃饭了很长一段时间,所以在生成 scrapy 代码的时候有额外的处理
虽然在工具内生成的 scrapy 脚本既能以项目执行,又能直接以单脚本直接执行(增加了单脚本代码块)
但是通常一个比较简短的项目根本就没有必要弄个又臭又长的项目框架,
有时为了既能用到 scrapy 的便利功能(数据收集的结构化,自带调度器,快速调节请求频率...),又想使用单脚本的便利性
所以在工具内以按钮(需主动点击)的方式添加额外注释代码的功能提供一些非常有用的注释的代码。
注释中给与了在单脚本情况之下如何实现增加额外管道的功能代码模板,
甚至在某种程度上能实现单脚本的分布式的代码模板。
(1) 在单脚本内生成的对象,包装进管道。
(2) 以猴子补丁方式实现的单脚本分布式。(这应该是我技术力的一个小极限了)
带有方便的记录配置的功能(持久化请求配置内容,方便以后使用)
带有多种加解密样例,加解密功能丰富。(大部分加解密都有纯py算法展示,更少的第三方依赖)
# 安装方式,通过pip安装即可
C:\Users\zhoulin08>pip install vrequest
# 通过git+pip进行安装
C:\Users\zhoulin08>pip install git+https://github.com/cilame/vrequest.git
# 下载安装该库会自动依赖安装 requests, lxml 这两个库
# 其他的依赖不会主动安装,因为与请求功能没有强耦合要求。所以会在那些功能被使用的时候提示没有该库
# 额外的依赖和功能:
# pyexecjs 或 js2py 任选其一,用于测试执行 js 脚本
# jsbeautifier 用于结构化 js 脚本
# cryptography 用于一些比较小众且我很难找得到的算法加解密
# 另外,如果你只想要使用加解密功能的话,你可以增加 --no-deps 的pip下载配置避免依赖下载,因为加解密部分的功能,
# 只要工具内没有明说存在依赖,就代表那些解密的功能全部都由不需要依赖,都有单个脚本直接实现。
# 甚至二维码的加解密都将依赖库都压缩着包含在了单个脚本内部。
C:\Users\zhoulin08>pip install vrequest --no-deps
# 如果你想体验全部的功能的话建议这么装,安装好之后直接体验所有功能
C:\Users\zhoulin08>pip install vrequest scrapy js2py jsbeautifier cryptography# 在安装该函数库后就有一个命令行工具,直接在命令行输入 vv 或者 vrequest 都可以打开该GUI工具
# eg.
C:\Users\zhoulin08>vv
# 并且功能描述都有写在帮助页,直接按照帮助页中的各种快捷键处理方式就可以
# 0 该工具大部分都可以用快捷键操作
# 1 可以将请求过的数据记录在本地,并且可以更新配置
# 哪怕关掉工具也能很方便的恢复请求的配置状态,方便使用
# 2 快速生成请求代码,让请求更加方便实现。
# ps.
C:\Users\zhoulin08>ee
# 直接在命令行输入 ee 直接打开便捷加密窗口,不用再工具里右键打开,
# 或者输入 vv e 也可以打开,这里重复功能是为了防止与其他工具冲突,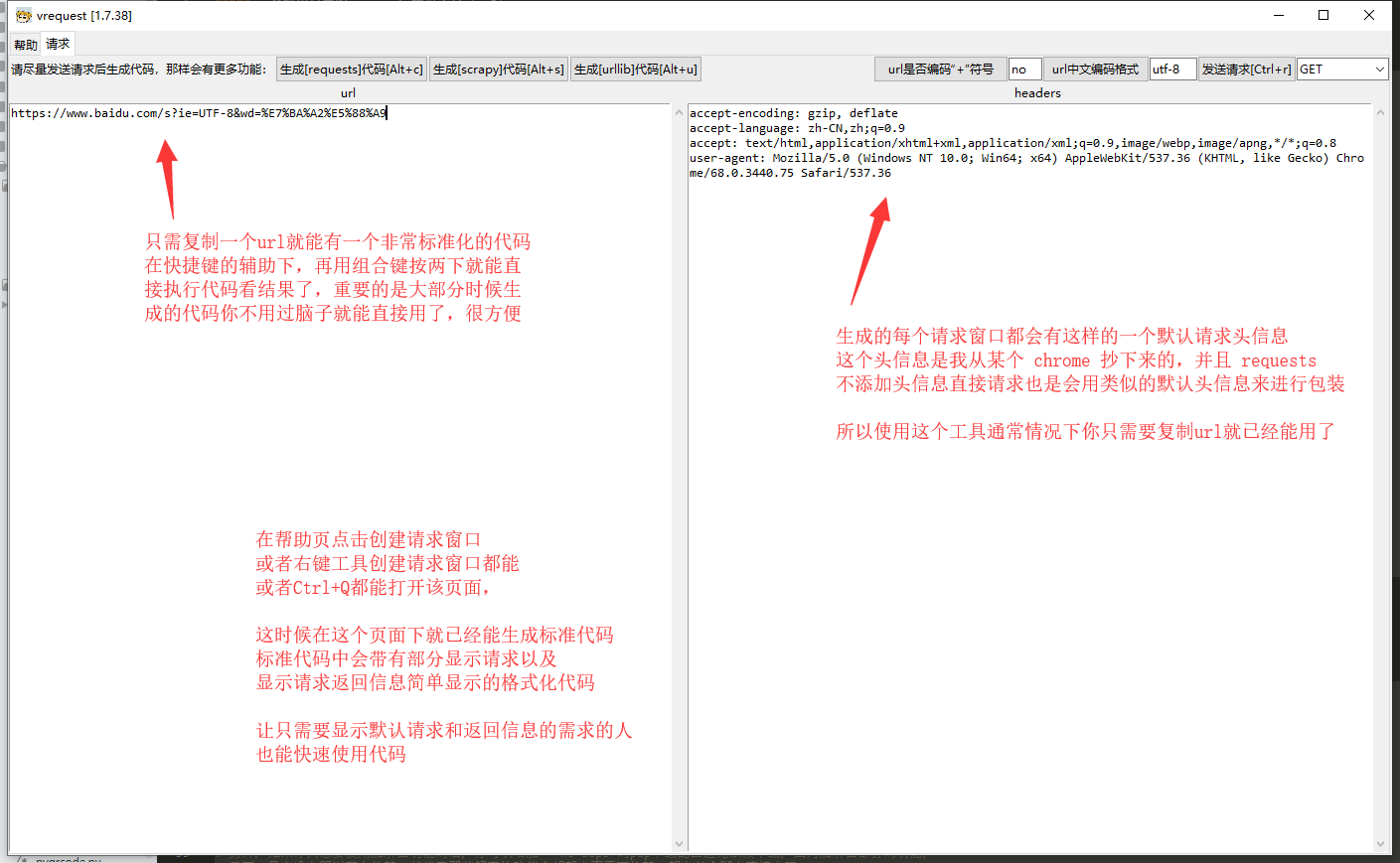
下面这里的代码执行和将生成的代码转到 IDE 里面执行是一样的,就不多赘述了。
下面这里的的代码执行有两种,
一种是项目执行,就是简单开个shell:
在默认环境生成项目,将该脚本拷贝到项目的 spiders 路径下以项目路径执行 scrapy crwal v 的来启动爬虫
一种执行的方式是单脚本执行:
单脚本执行可以直接放在 IDE 里面当作是一般 python 脚本一样执行 scrapy 爬虫,比较方便开发