
- Overview
- Stated Templates
- High-level design of Stated Workflows
- Stated Workflow Concurrency
- Pub/Sub Clients Configuration
- Durability
- Workflow APIs
- Architecture
Stated Workflows is a collection of functions for a lightweight and scalable event-driven workflow engine using Stated template engine. This README assumes some familiarity with the Stated REPL. If you don't have Stated, get it now. The key benefits of Stated Worklflows are:
- Easy - Stated Workflows are easier to express and comprehend than other workflow languages
- Testable - Stated Workflows are testable. Every Stated Workflow can be tested from a REPL and behaves exactly locally as it does in Stated Workflow cluster.
- Interactive - As you can see from the exmaples in this README, you can interact directly with workflows from the REPL
- Transparent - Stated Workflows takes a "What You See Is What You Get" approach to workflows. Stated-Workflows is the only workflow engine with a JSON-centric approach to data and durability.
- Highly Available - Stated Workflows can be run in an easy-to-scale, k8s-friendly cluster for scaling, durability, and high availability
To install the stated-js package, you can use yarn or npm. Open your terminal and run one of the following commands:
Using Yarn:
yarn global add stated-workflowsUsing Npm:
npm install -g stated-workflowsVerify you have node:
node -v | grep -Eo 'v([0-9]+)\.' | grep -E 'v19|v[2-9][0-9]' && echo "Node is 19 or higher" || echo "Node is below 19"
To use the Stated Workflows REPL (Read-Eval-Print Loop) it is recommended to have at least version 19.2 or higher of node.js. The
Stated REPL is built on Node REPL.
You can start the REPL by running the stateflow command in your terminal:
stateflowThe REPL will launch, allowing you to interact with the stated-js library. In order to launch properly you need to have
node on your path.stateflow is a wrapper script that simply calls stated-workflow.js, which contains this
#!/usr/bin/env node --experimental-vm-modules.
For example you can enter this command in the REPL:
> .init -f "example/homeworld.yaml"Stated Templates Processor run a change graph called a
DAG.
Stated flattens the DAG and executes it as a sequence of expressions called the plan. The example below illustrates how a plan executes a sequence of REST calls and transformations in an ordinary Stated
template.
> .init -f "example/homeworld.yaml"
{
"lukePersonDetails": "${ $fetch('https://swapi.dev/api/people/?name=luke').json().results[0] }",
"lukeHomeworldURL": "${ lukePersonDetails.homeworld }",
"homeworldDetails": "${ $fetch(lukeHomeworldURL).json() }",
"homeworldName": "${ homeworldDetails.name }"
}
> .plan
[
"/lukePersonDetails",
"/lukeHomeworldURL",
"/homeworldDetails",
"/homeworldName"
]
As 'luke' moves through the plan two REST calls are made, and no new inputs can enter. This is because Stated
queues execution plans, allowing one to complete before the next can enter. This is a clean way to prevent
concurrent state mutations, and works well for in-memory computation DAGs. We can see that long
running I/O operations, however, will bottleneck the template. If the template engine is shutdown, there is no way to 'restart'
the work where it left off. We can see that for "workflows", which implies lots of I/O, and hence longer runtimes, we
need a way to address these concerns.
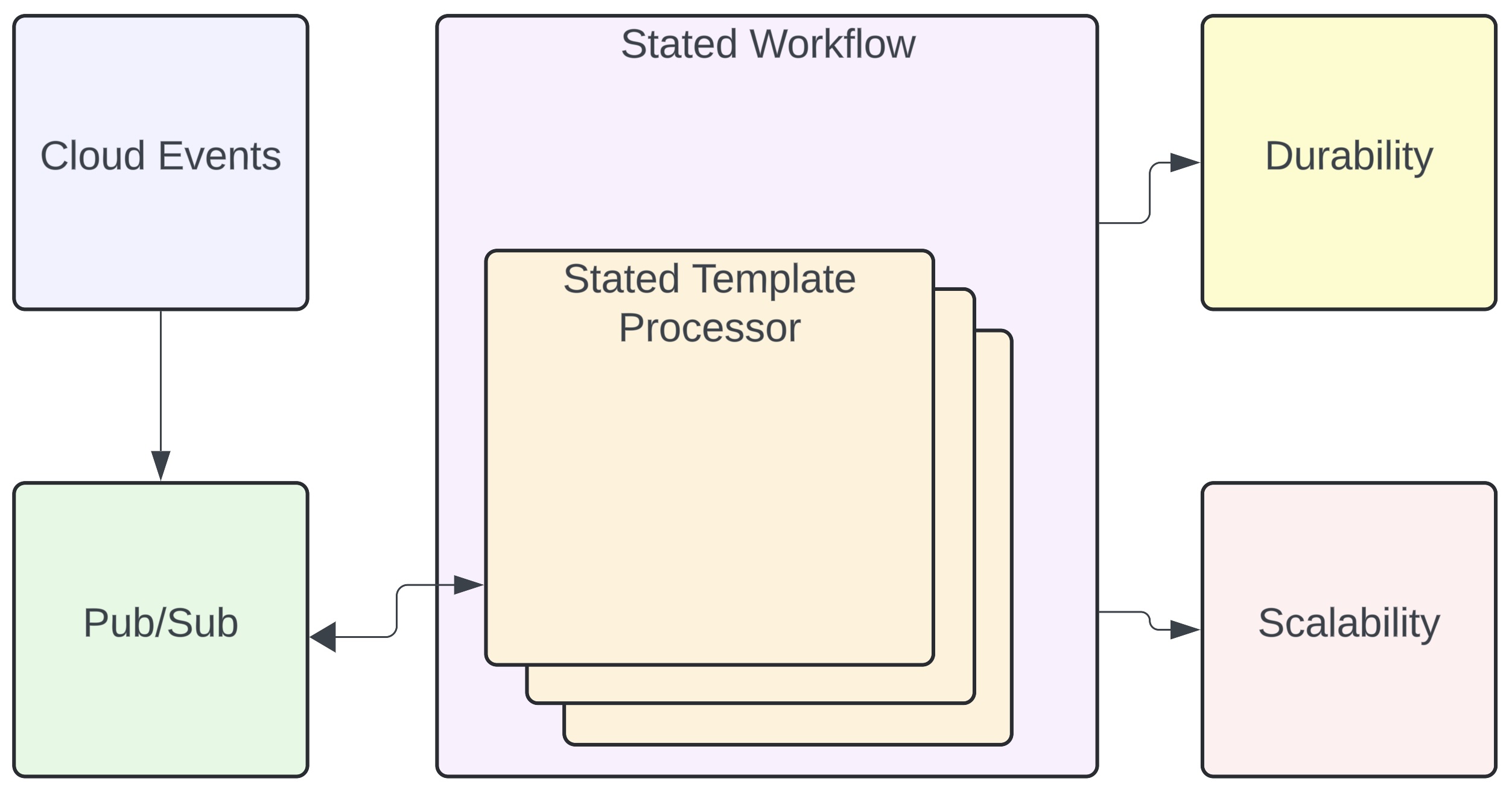 .
Stated Workflows extends stated templates processor to add notion of Cloud Events, Pub/Sub functions, Durability and Scalability.
.
Stated Workflows extends stated templates processor to add notion of Cloud Events, Pub/Sub functions, Durability and Scalability.
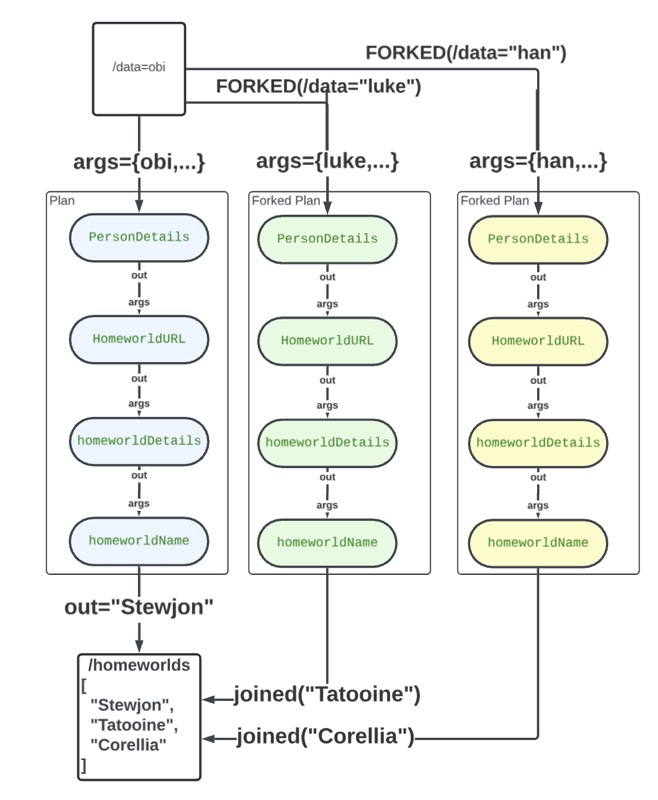
Stated Workflow leverages the Stated Concurrency forked/joined model to fork serial execution pipelines into asynchronous parallel executions.
Forked executions may be considered as parallel contexts, which are joined on "joined" function. The example below shows how to use the forked/joined framework to run a workflow in parallel.
startTime$: $millis()
data: ${(startTime$;['luke', 'han', 'leia', 'chewbacca', 'darth', 'ben', 'c-3po', 'yoda'].($forked('/name',$)))}
name: obi
personDetails: ${ $fetch('https://swapi.tech/api/people/?name='&name).json().result[0]}
homeworldURL: ${ personDetails.properties.homeworld}
homeworldDetails: ${ $fetch(homeworldURL).json().result }
homeworldName: ${ $joined('/homeworlds/-', homeworldDetailч]s.properties.name)}
homeworlds: []
totalTime$: $string($millis()-startTime$) & ' ms'The difference from the serial execution of homeworld.yaml is that the execution of forked plans runs non-blocking and asynchronous in parallel until it "joined" to the ROOT plan.
Stated Workflows solves these problems in order to provide a suitable runtime for long-running, I/O heavy workflows:
- Atomic State Updates - An atomic state update operator "joined" allows concurrent "forked" pipelies to avoid Lost Updates.
- Durability - Stated Workflows uses snapshots to write their state to various persistence stores. Stated Workflows can be started from a snapshot, hence restoring all workflow invocations to their state at the time of the snapshot.
- Pub/Sub Connectors - Stated Workflows provide direct access to
$publishandsubscribefunctions that can dispatch events into workflow with a desired parallelism. A simple change to the subscriber configuration allows your workflow to operate against Kafka, Pulsar, and other real-world messaging systems.
Stated is a NodeJS framework, leveraging NodeJS v8 engine's concurrency model to efficiently run I/O-heavy workloads asynchronously.
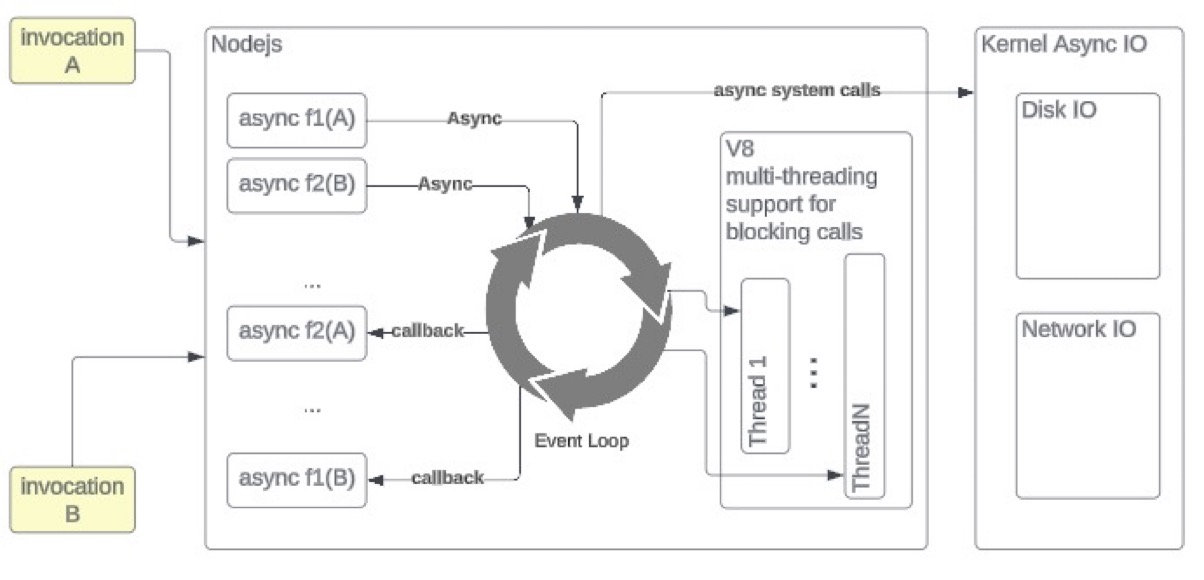
Stated-Workflows provides a set of functions that allow you to integrate with cloud events, consuming and producing from
Kafka or Pulsar message buses, as well as HTTP. Publishers and subscribers can be initialized with test data. This example,
joinResistance.yaml, generates URLS for members of the resistance, as test data. The data URLs are then published as
events and dispatched to a subscriber with a settable parallelism factor. The subscriber $fetches the URL and extracts
the Star Wars character's full name from the REST response.
start: ${ (produceParams.client.data; $millis()) } #record start time, after test dataset has been computed
# producer will be sending some test data
produceParams:
type: "my-topic"
client:
type: test
data: ${['luke', 'han', 'leia', 'R2-D2', 'Owen', 'Biggs', 'Obi-Wan', 'Anakin', 'Chewbacca', 'Wedge'].('https://swapi.tech/api/people/?search='&$)}
# the subscriber's 'to' function will be called on each received event
subscribeParams: #parameters for subscribing to an event
source: cloudEvent
type: /${ produceParams.type } # subscribe to the same topic as we are publishing to test events
to: /${joinResistance}
subscriberId: rebelArmy
initialPosition: latest
parallelism: 1
client:
type: test
joinResistance: |
/${
function($url){(
$rebel := $fetch($url).json().results[0].name;
$set( "/rebelForces/-", $rebel) /* append rebel to rebelForces */
)}
}
# starts producer function
send$: $publish(produceParams)
# starts consumer function
recv$: $subscribe(subscribeParams)
# the subscriber's `to` function will write the received data here
rebelForces: [ ]
runtime: ${ (rebelForces; "Rebel forces assembled in " & $string($millis()-start) & " ms")}Let's see how long it takes to run, using a parallelism of 1 in the subscriber as shown above:
> .init -f "example/joinResistance.yaml" --tail "/rebelForces until $~>$count=10"
Started tailing... Press Ctrl+C to stop.
[
"Luke Skywalker",
"Han Solo",
"Leia Organa",
"R2-D2",
"Owen Lars",
"Biggs Darklighter",
"Obi-Wan Kenobi",
"Anakin Skywalker",
"Chewbacca",
"Wedge Antilles"
]
> .out /runtime
"Rebel forces assembled in 3213 ms"The runtime reflects the fact that parallelism:1 causes the REST calls to happen in serial. Now let's run a modified
version where subscribeParams have "parallelism": 10. We should expect a speedup because there should be as many as
10 concurrent REST calls.
> .init -f "example/joinResistanceFast.yaml" --tail "/rebelForces until $~>$count=10"
Started tailing... Press Ctrl+C to stop.
[
"Owen Lars",
"Han Solo",
"R2-D2",
"Leia Organa",
"Luke Skywalker",
"Chewbacca",
"Obi-Wan Kenobi",
"Wedge Antilles",
"Anakin Skywalker",
"Biggs Darklighter"
]
> .out /runtime
"Rebel forces assembled in 775 ms"
Notice that the order of elements in /rebelForces is not the same as their order in the input data, reflecting the fact
that we have 10 concurrent events being processed. The speedup for joinResistanceFast.yaml shows that many REST calls
are happening in parallel. The $parallelism factor provides backpressure into the messaging system such as kafka which prevents the number of
'in flight' events from exceeding the $parallism factor.
Stated Workflows provides an atomic primitive that prevents lost-updates
with concurrent mutations of arrays. It does this by using a
special JSON pointer defined by RFC 6902 JSON Patch for appending to an array.
The joinResistanceFast.yaml example shows how to use the syntax: $set( "/rebelForces/-", $rebel)
to safely append to an array.
joinResistance: |
/${
function($url){(
$rebel := $fetch($url).json().results[0].name;
$set( "/rebelForces/-", $rebel) /* append rebel to rebelForces */
)}
}As we showed earlier, both joinResistance.yaml and joinResistanceFast.yaml produce the expected 10 results.
Let's consider what happens if we don't use an atomic write primitive. Instead, we will read the value of the $rebelForces
array and append $rebel to it, in order to illustrate the dangers of the well-known lost-update problem.
joinResistance: |
/${
function($url){(
$rebel := $fetch($url).json().results[0].name;
$set( "/rebelForces", $rebelForces~>$append($rebel)) /* BUG!! */
)}
}This type of update, where you read a value, mutate it, write it back is a classic example of the
lost-update problem.
Each of the concurrent pipeline invocations read the array, update it in memory, and write the result.
The problem is they all read, concurrently, the same initial value which is an empty array.
You can see below that using a naive update strategy to update rebelForces results in only one of the 10 names
appearing in the array.
> .init -f "example/joinResistanceBug.yaml" --tail "/rebelForces 10"
Started tailing... Press Ctrl+C to stop.
"Wedge Antilles"This explains why you should use the "dash syntax", like /rebelForces/- to append an element to an array which is
a safe operation to perform concurrently.
Stated Workflow comes with built-in HTTP, Pulsar, Kafka, Dispatcher and Test clients for cloudEvent subscribe command. Each client implements its own durability model.
Test clients for publisher and subscriber can be used to develop and test workflows. Test publisher may include testData array of data
to send it directly to test subscriber dispatcher with acknowledgement in the template.
Example snippets from example/joinResistanceRecovery.yaml template.
produceParams:
type: "rebelDispatch"
client:
type: test # test client produces directly to the test subscriber dispatcher
testData: ['luke', 'han', 'leia'] # test producer only makes sense when it includes test data
subscribeParams: #parameters for subscribing to an event
source: cloudEvent
type: /${ produceParams.type } # subscribe to the same topic as we are publishing to test events
to: /${saveRebelWorkflow}
subscriberId: rebelArmy
initialPosition: latest
parallelism: 1
client:
type: test
data: ['obi-wan'] # test subscriber may include test data to run without a producer
acks: [] # if the acks are present in client: type: test, then the subscriber will be storing acknowledgement in this fieldWhen subscriber client type is set to dispatcher or test, it will be running the workflow and expecting an external process to add data.
``
Stated Template Processor can be extended by adding custom callbacks run on data change or on an interval. Stated Workflow uses this feature to implement durabilty by persisting the state of the workflow to a snapshot file.
Pub/Sub clients implement its own durability model. Pulsar and Kafka use server side acknowledgement to ensure that the message is not lost. Test client uses a simple acknowledgement in the template. HTTP client blocks the synchronous HTTP response until the first step persist.
To develop and test workflows with the test client adding acks field will enable test acknowledgements in the client. Messages processed by
the workflow will be added to the acks array.
client:
type: test
data: ['obi-wan'] # test subscriber may include test data to run without a producer
acks: [] # if the acks are present in client: type: test, then the subscriber will be storing acknowledgement in this field
Pulsar pub/sub relies on server side acknowledgement, similar to the test data. On failure or restart, the subscriber will continue from the next unacknowledged message, and will skip steps already completed in the restored workflow snapshot.
Kafka can rely on the consumer group commited offset. For parallelism greater than 1, the subscriber will be storing all unacknowledged messages and calculating the lowest offset to be commited. A combination of snapshotted stated and kafka server side consumer offset helps to minimize double-processing of already processed steps.
Snapshots save the state of a stated template, repeatedly as it runs. Snapshotting allows a Stated Workflow to be stopped non-gracefully, and restored from the snapshot. The step logs allow invocations to restart where they left off.
example/joinResistanceRecovery.yaml shows a workflow with a simple workflow template, which fetches a rebel detail and join it to rebelForces array.
The --options={"snapshot":{"seconds":1, "path":"./resistanceSnapshot.json"}} option causes a snapshot to be saved to./defaultSnapshot.json file once a second, and only when there is a change in the template state.
Storage and path can be configured in the options --options={"snapshot":{"seconds":1, "path":"./mySnapshot.json", "storage": "fs"}}
> .init -f "example/joinResistance.yaml" --options={"snapshot":{"seconds":1}} --tail "/ until $.rebelForces~>$count=10"
{
"start": 1716238794169,
"produceParams": {
"type": "my-topic",
"client": {
"type": "test",
"data": [
"han",
"leia",
"R2-D2",
"Owen",
"Biggs",
"Obi-Wan",
"Anakin",
"Chewbacca",
"Wedge"
]
}
},
"subscribeParams": {
"source": "cloudEvent",
"type": "my-topic",
"to": "{function:}",
"subscriberId": "rebelArmy",
"initialPosition": "latest",
"parallelism": 2,
"client": {
"type": "test",
"acks": [
"han",
"leia",
"R2-D2",
"Owen",
"Biggs",
"Obi-Wan",
"Anakin",
"Chewbacca",
"Wedge"
]
}
},
"rebel": "luke",
"joinResistance": null,
"send$": "done",
"recv$": "listening clientType=test ... ",
"rebelForces": [
"Luke Skywalker",
"Leia Organa",
"Owen Lars",
"Chewbacca",
"Anakin Skywalker",
"Biggs Darklighter",
"R2-D2",
"Wedge Antilles",
"Han Solo",
"Obi-Wan Kenobi"
],
"runtime": "Rebel forces assembled in 728 ms"
}The snapshot can be viewed with the cat command:
cat ./resistanceSnapshot.jsonOn restore from the snapshot, the workflow will restart exactly where it left off.
.restore -f "example/resistanceSnapshot.json" --tail "/rebelForces until $~>$count=10"
[
"Luke Skywalker",
"R2-D2",
"Obi-Wan Kenobi",
"Owen Lars",
"Han Solo",
"Anakin Skywalker",
"Leia Organa",
"Biggs Darklighter",
"Chewbacca",
"Wedge Antilles",
"Luke Skywalker"
]The ack function can be used to acknowledge the message in the subscriber. Providing in the client configuration explicitAck: true will enable
the explicit acknowledgement in the subscriber. The ack function should be called at the end of the subscriber workflow invocation to acknowledge the message.
start: "${( $subscribe(subscribeParams); $publish(publishParams) )}"
subscribeParams: #parameters for subscribing to a http request
to: ../${func}
type: "rebel"
parallelism: 2
source: "cloudEvent"
client:
explicitAck: true
acks: []
type: dispatcher
publishParams:
type: "rebel"
source: "cloudEvent"
client:
type: test
data: [{type: "rebel", name: "luke"},{type: "rebel", name: "han"},{type: "rebel", name: "leia"}]
func: "/${ function($data){( $console.log('got: ' & $data); $forked('/input',$data); )} }"
input: null
process: |
${(
$console.log('processing: ' & $$.input);
$$.input != null ? (
$joined('/results/-', $$.input);
$ack($$.input)
)
: 0
)}
results: []
report: "${( $console.log('result added: ' & $$.results) )}"> .init -f "example/explicitAck.yaml" --tail "/results until $~>$count=3"
[
{
"type": "rebel",
"name": "luke"
},
{
"type": "rebel",
"name": "han"
},
{
"type": "rebel",
"name": "leia"
}
]README.API.md provides a REST API to manage the workflow. The API can be used to start, stop, and view workflows. The API can also be used to fetch the latest snapshot and restore the workflow from the snapshot.
Overall architecture focuses on providing simple and scalable event-driven workflows. It is a single service architecture, but with pluggable and easy to extend support of different persistence stores, as well as providing custom functions and Pub/Sub clients.
At the same time the operator can restrict functions available to the workflow, and decide on different parallelism and durability models.
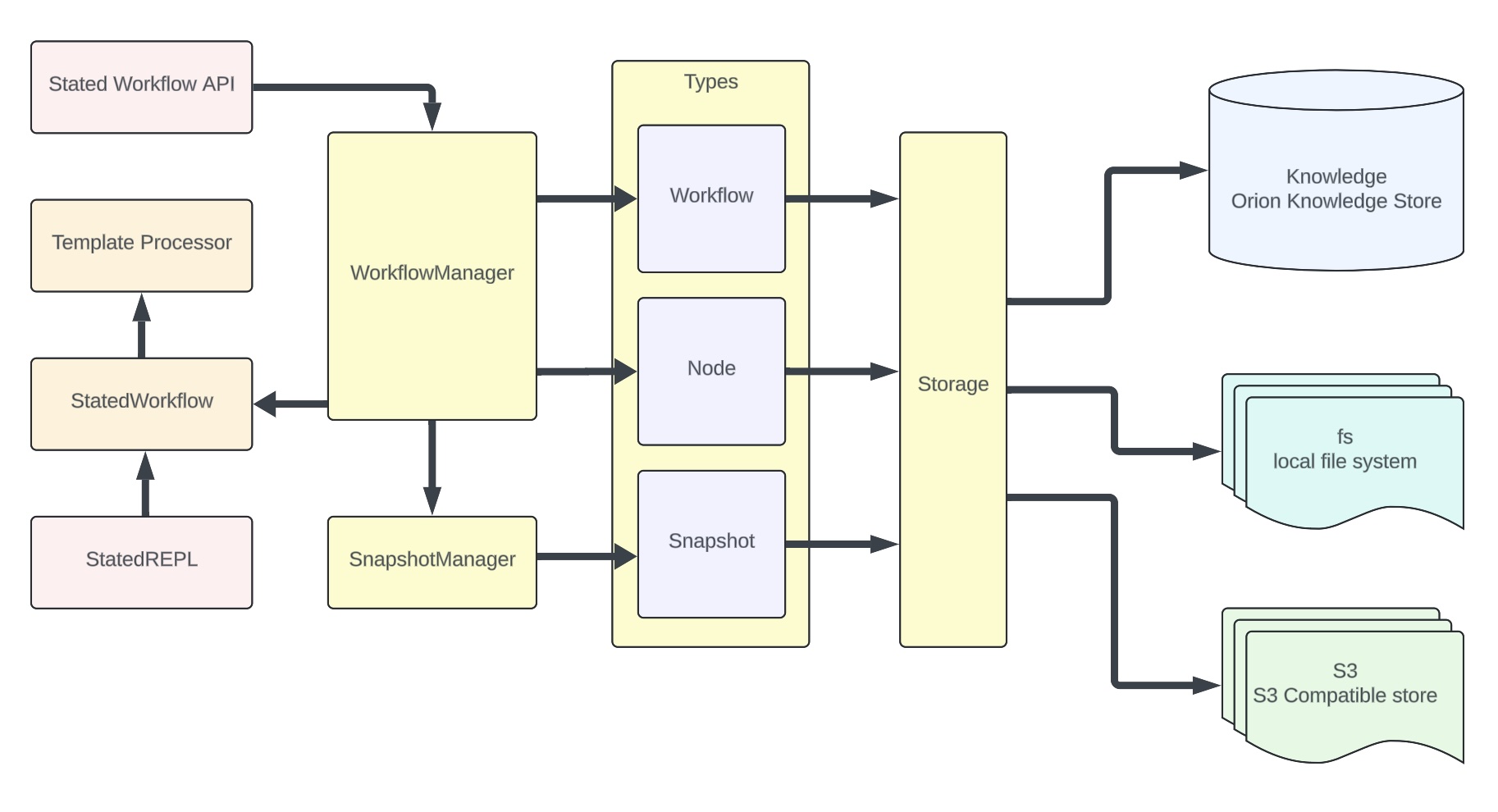
Internally stated workflow consists of the following modules:
- StatedWorkflow extends Stated Template Processor functionality to support event-driven workflows
- WorkflowManager is a central component that manages the workflow lifecycle. It is responsible for starting, stopping, and restoring workflows from the snapshot.
- WorkflowAPI provides a REST API to manage the workflow.
- SnapshotManager is responsible for workflow snapshot lifecycle.
- Storage is a pluggable module that supports different storage types to persist its state.
Stated workflows supports different storage types to persist its state, including workflow definitions, workflow snapshot, and node state.
- workflow - a uniq workflow id, name, and workflow template definition
- snapshot - a snapshot of a workflow. Snapshot includes its workflow definition, and if a snapshot enabled - it supersedes workflow definition.
- node - workflow node state, which is used to workflow to node allocation and load balancing
 .
.
Workflow Manager can scale linearly leveraging persistent storage
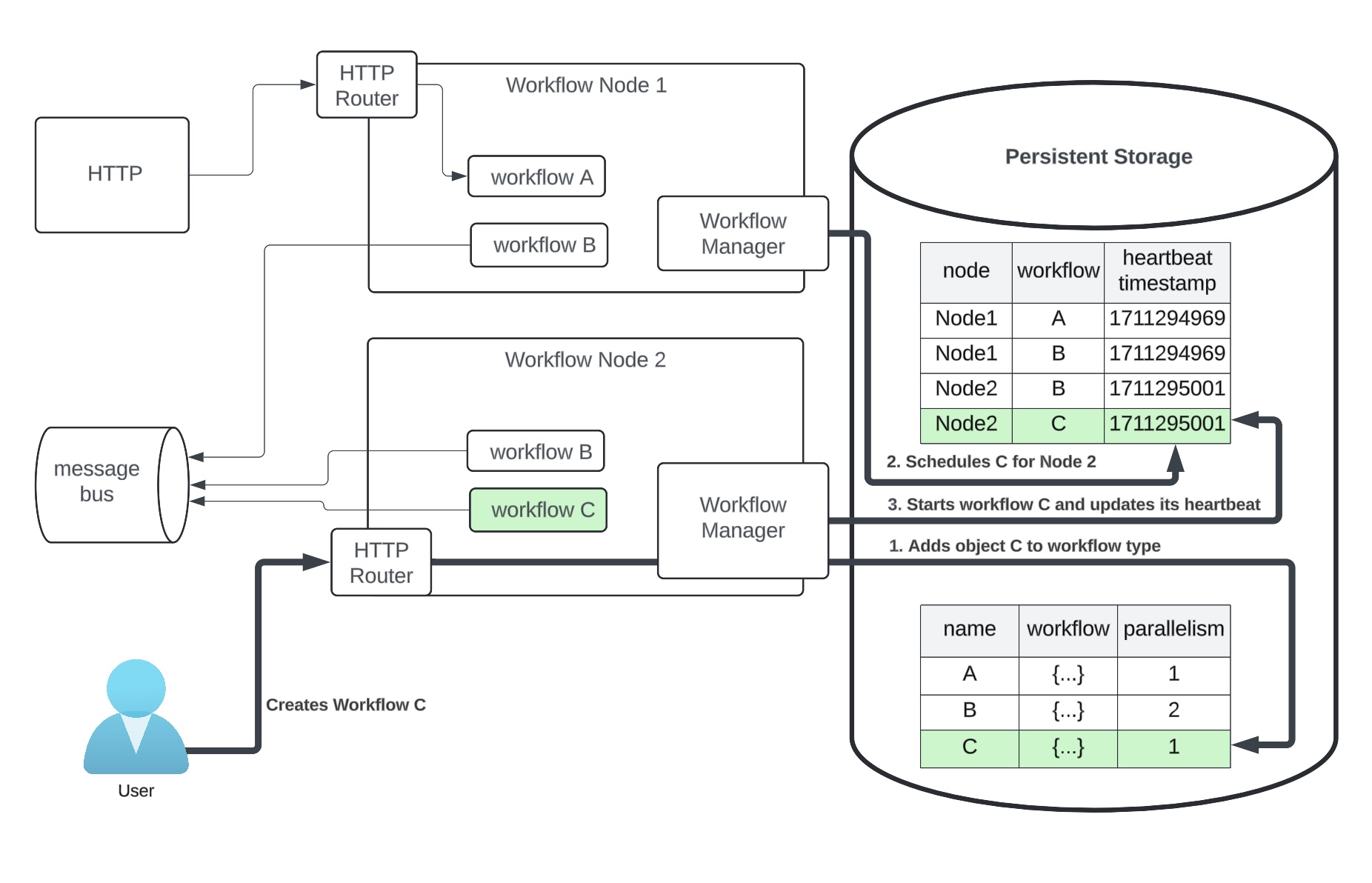 .
.
A node failure will be detected after it fails to update its heartbeat within a timeout
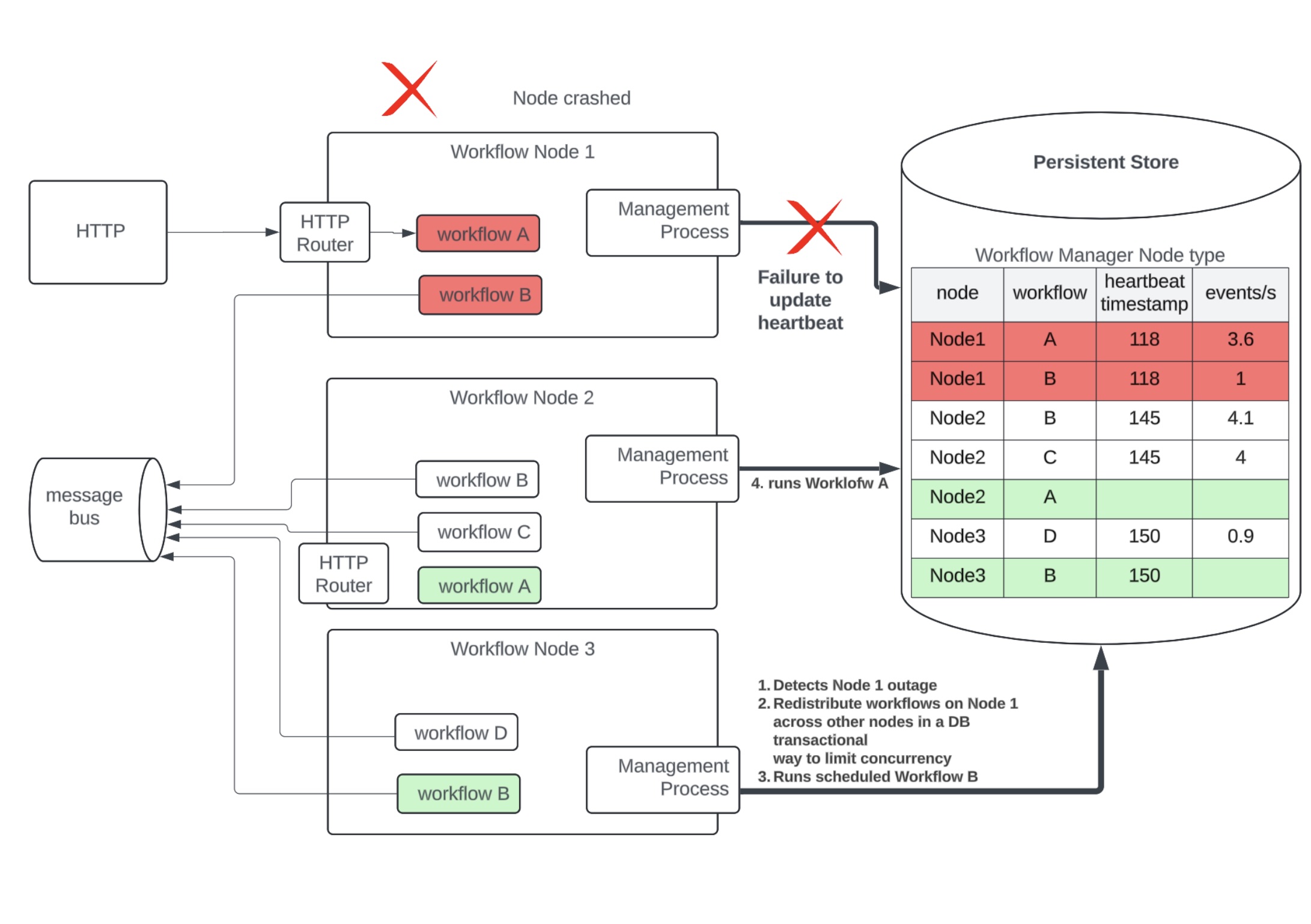 .
.