Doxygen parsing missing #529
Comments
|
I could have a look at this. I had a quick look and found about the |
|
Clang already has a doxygen parser, you can get a parsed result from Maybe we can convert the parsed comment tree into a flat-structure that can be easily consumed by other features in clangd. E.g. something like: struct Comment {
string SymbolDescription; // possible with helpers to render as markdown or plaintext.
Map<string, Comment> Parameters;
// and so on
};This will require some thinking to generalize to different types of c++ symbols and doxygen constructs. so if you want to go down that path it would be great to see some proposals and designs before diving into implementation. |
|
Any updates about this problem? |
|
It's been a year; any updates? Also, @Leon0402, you said
Do you have any info on which features/syntaxes may be correctly processed? |
|
Hello, any update on this? Currently migrating to clangd and this is pretty much my only problem at the moment. |
|
I took a look at this yesterday, here are my thoughts/ideas: I think the right place to start would indeed be
all of which would benefit from improved doxygen parsing. Now, we could directly convert the doxygen to markdown right in So I agree with @kadircet's approach of storing the information gathered from doxygen in a structure like this: I think a good way to start would be the In the future we can then add support for additional commands like @kadircet What do you think? If you agree with this, I'd start with implementing the |
|
One more thing I haven't mentioned above: The index currently stores a symbol's documentation as a plain std::string, but I think we'll want to change this to the newly proposed SymbolDocumentation struct...? How big of a deal would it be to change one of the datatypes in the index? Can clangd easily detect this and just rebuild the index or would we need some kind of conversion logic? @sam-mccall @HighCommander4 @kadircet |
Yep, there's a version number you can bump if you make a format change. |
|
I played around a bit and here's what I came up with so far: https://reviews.llvm.org/D129972 Currently looks like this: So far, I've implemeted parsing for the most common doxygen commands and added it to Hover. CodeCompletion still uses the unparsed comment string for now. Some stuff left to do:
|

|
This looks really good! |
|
I am waiting for your good news. |
I noticed this when adding a new type to the index for clangd/clangd#529. When the assertion failed, this actually caused a crash, because llvm::expected would complain that we did not take the error.
|
Patch is now submitted for Review: https://reviews.llvm.org/D131853 |
|
I played around a bit with using the parsed doxygen docs in other interesting ways, here's two things I've come up with:
Proof of Concept: https://reviews.llvm.org/D136038 |

|
Copy/pasting the comment from review to here for having some high-level discussions. Hi! Sorry for letting these series of patches sit around without any comments. We were having some discussions internally to both understand the value proposition and its implications on the infrastructure. So first of all, what are the exact use cases you're planning to address/improve with support for doxygen parsing of comments? Couple that comes to mind:
any other use cases that you believe are important? as you might've noticed, this list already talks about dealing with certain doxygen commands (but not all).
what do you think about those conclusions? any other commands that you seem worth giving a thought? another important thing to consider is trying to heuristically infer some of these fields for non-doxygen code bases as well. that way we can provide a similar experience for both. some other things to discuss about the design overall:
Happy to move the discussion to some other medium as well, if you would like to have them in discourse/github etc. |
For most parts of the documentation, only formatting or stripping is probably enough, as there would not be a need to hide information. For "specific contexts" (e.g. parameters): Why not both? Storing the info both in "original order" and "parsed" gives the best of both worlds:
|
Sounds about right!
Infering this from the first sentence sounds reasonable, it looks like this is what
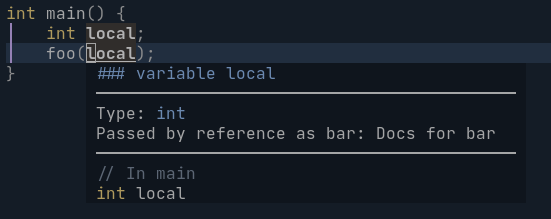
One idea here might be to add this when hovering over a local variable that got assigned to the result of a function call, e.g. /// \return my favorite foo
int makeFoo();
int main() {
int foo = makeFoo();
int bar = foo; // Hovering over "foo" here could maybe show the \return docs from makeFoo()
}
Maybe handling \throws could be useful for some codebases? There's also #1320 which proposes to add support for \copydoc
I agree with you and @founderio here, it's probably best to no reorder anything (I wonder how the VSCode extension handles reordering though...? I don't have VSCode installed, but maybe someone else can check this)
So what are some heuristics we can use here (apart from "first sentence -> @brief)? I haven't really worked with anything other than doxygen yet, so what are some common ways people document e.g. parameters instead?
👍
Hmm so you're probably talking about I'd be interested in doing this refactor, but I think I need a few more pointers before I can get started with this.
Tested this out with the neovim and LLVM codebases. With my proposed patch, index size increased from 7.7 MB to 7.9 MB for neovim and from 142MB to 145MB. Indexing time (on my local machine, 12 threads) increased frrom 3.3s to 3.45s for neovim and from 13m16s to 13m19s for LLVM.
Yeah that sounds like the ideal solution (if the refactor of the parsing logic succeeds) |
Looked into this a bit more, the best solution would probably be to add the allocator to our The CommentParser test actually already has an example of how to implement a However, SourceManager also wants a reference to the diagnostics, so it's a bit of a chicken and egg problem. |
One more thing I thought of: When parsing the doxygen comment, maybe for storing the stripped/reformated text we can directly use |
That makes sense, but I think it's orthogonal to what we do with doxygen comments. it's more about transferring/inferring docs from initializer of a vardecl.
Just to be clear, I was still suggesting stripping "all" doxygen commands from the documentation. I am not sure what else we can do for
This looks quite cool, but I'd actually leave it out of the initial scope at least (or just say something like "Same as Foo") as going from a textual representation of a symbol name to its identity is hard and heuristic searches here are likely to be hindering in big code bases.
Well this is an exercise we need to do for every command we want to treat specially, in theory for parameters (if we chose to store them separately), we can search for sentences mentioning the parameter name and synthesize using those (or only synthesize when there's a single such sentence).
Right, in theory we can pass in any allocator we want, it doesn't need to come from ASTContext. Anything but a dependency to the AST itself (the tree) is something we can "synthesize" in theory, and it seems there's no strong dependency on the tree itself but just the support structures (AFAICT, all pieces that uses the
Yeah, more than happy to help.
This looks promising, especially considering that this will probably get better since we're planning to preserve less structured information than the proposal and also perform more stripping.
We've got a helper class called SourceManagerForFile, which would provide the mock SourceManager we need for parsing this comment.
Right, I guess my initial explanation was a little vague, but I feel like that's what we should do. |
Yeah this just crossed my mind, but it's definitely out of scope for now.
So for example for "\param foo docs for foo" you'd propose to replace it by something like "
Agreed!
Okay, seems like a lot of potential for false positives, I think the heuristics should be pretty conservative here
That sounds useful, I think I'll take another look at this and will reach out again when I encounter problems.
👍 |
Sorry if I'm missing something, but where's this parsing logic? |
yeah, and for
To be clear, it's not so advanced and could use some improvements: https://github.com/llvm/llvm-project/blob/main/clang-tools-extra/clangd/Hover.cpp#L1357 |
Ah, maybe an alternative would be to parse the doxygen commands directly into a We could then move our existing markdown-parsing logic to the same class that does the doxygen parsing and use it to convert non-doxygen comments to |
Its a bug of comment parser in https://reviews.llvm.org/D143112 |
|
I know it's a bug that you think exists, but I don't understand what bug you think exists |
I'm not sure what "ping clangd" means. If the review comments on the patch so far have been addressed and the patch is waiting for additional review, the patch author can ping the reviewer(s) periodically as a reminder. |
|
I mean ping the clangd organization. |
|
@sam-mccall @kirillbobyrev @kadircet @hokein @Ceron257 @HO-COOH |
|
@tom-anders Now that the phab has been set to read-only, I think we should migrate the patches to a GitHub PR. |
|
@anstropleuton that is pretty rude behavior. Why don't you work on this issue instead? These people don't work for free. People like you making requests of contributors and maintainers is the reason open-source software is so toxic. |
This is in preparation for implementing doxygen parsing, see discussion in clangd/clangd#529. Differential Revision: https://reviews.llvm.org/D143112
|
@tristan957 I am not good at programming and I can't reach the coding standards of this project. And making request or giving feedback doesn't make the community toxic. I am just a user of this project. Writing a hate on me doesn't change anything so please stop it. |
|
@anstropleuton Then offer to pay someone to fix this issue or please stop asking people to do things for you without compensation. |
|
This is pretty silly… feature requests exist for a reason, but pinging random people is indeed not pretty good. Let’s just end this conversation here now, no use polluting the comments. |
|
I just saw "I mean ping the clangd organization." by aaronliu0130 so I thought it would be fine... My apologizes if it wasn't. |
|
Any updates? Can't wait to see clangd supporting doxygen comments. |
|
We're all waiting on llvm/llvm-project#78491 |
|
The hovered display is created in function |
|
You can also try Tom Anders's patches in their phabicrator merge requests. |
|
@aaronliu0130 Any link to the merge req that has doxygen parsing? Tom Ander mentioned some different links and I can't figure out which one is the one that has doxygen added. |
How do I properly patch? I tried using The enums My exact steps:
|

Thanks, problem solved. It's working as intended and I've modified a little bit to match my own preferences. Some features missing
How can I add parsing in auto complete, I need some clues about where to modify. |

You can use this patch to render more fields and fix detailed description.
Don't know how to enable HI window in autocomplete to explore this problem |
|
any schedule or plans to merge the patches into main? |
|
Not sure how relevant this is to us, but there are some in-flight patches to improve the doxygen parsing code that's upstream in the clang frontend ( |
Currently clangd doesn't seem to process doxygen commands or at least not all of them (there are different supported syntax formats by doxygen).
A sample method produces this output by clangd

As seen in the screenshot the commands like \brief, \param are ignored.
The Vs Code C/C++ extension on the other hand is able to parse this correctly to

The text was updated successfully, but these errors were encountered: