You can use this master branch as a skeleton beam project
master分支可以用来当作一个骨架项目
beam代码理论上可以驱动spark,flink等等流式框架,详情参考这里
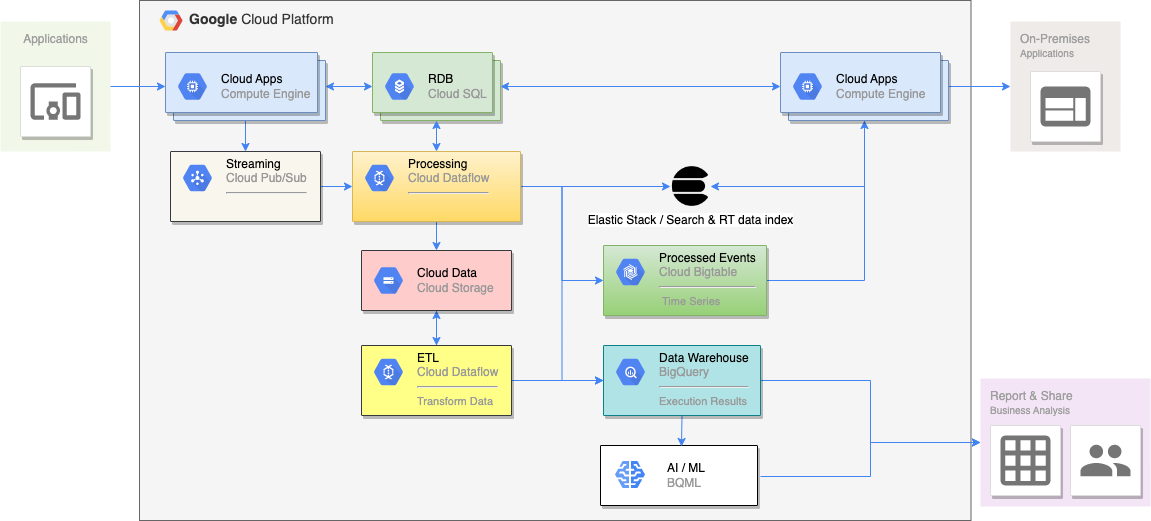
pubsub/kafka -> dataflow/flink -> join dimesion table -> data processing (realtime calculation + data warehouse ingestion + back files) -> GCS(avro, csv for both data & deadleter) + BigQuery + HBase/Bigtable (realtime analysis) + Elasticsearch
- Data consumption from message queue (Pubsub / Kafka)
- Raw data join dimension table, MySQL & fit in memroy
- Windowed data really time aggregation then ingest into Bigtable / Hbase
- Hot data ingest into Elasticsearch for realtime analysis
- Ingest into data warehouse (BigQuery) for big data analysis
- Data backup into files (Avro + CSV)
We have a dedicated branch for this.
Basic mode is a simplified real time data pipeline sample created for Firebase/GA users as a quickstart.
All you need to do is set the isBasic flag to true in one of those runtime parameters.
Once the flag in on, the pipeline is simple as
events data -> Pubsub -> Dataflow -> BigQuery
You can use this data generator or publish the json data yourself, as long as you follow our predefined schema, which is exactly the same as Firebase/GA native table. Then the Beam code will take care of the rest.
I have tested pub/sub data across regions, TW & US, usually the data will be available in BQ within 500ms.
- Firebase / GA native pipeline may have a delay up to 48 hours
- Very occasional data losses, and it's hard to pinpoint the causation or fix it
- Limited number of messages per day
- Streaming inserts cost, this pipeline can run as batch jobs and insert data through BigQuery Storage API
- You do not have to create the BigQuery table in advance. A time partitioned table based on the event timestamp will be auto created if it doesn't exist.
- There is no impact on business team at all since the data schema are the same as Firebase / GA native tables. They only see their data much more timely
- In case you may want to migrate your old GA schema to Firebase/GA4, please use the tool here
- How to get
user_pseudo_idfrom the client SDK - Import segments back into Firebase for targeting users
Java dev environment
- JDK8+
- Maven
项目里提供了初始化脚本 scripts/dim1.sql 维表更新的话直接update整个管道就可以了,如果维表需要LRU策略保留在内存,目前还没有办法。
You could use this script to init the MySQL if you use gcpplayground to generate your messages. Also, you could simply use this init script to run a MySQL instance in Docker.
You could use make to initialize the Bigtable enviroment. Adjust the parameters in makefile accordingly, e.g. cluster name, region etc.
Create Bigtable cluster, run it once. 拉起一个Bigtable集群实例。
make btcluster
Setup Bigtable tables, both tall and wide. 这步会建立一个宽表和一个高表分别用来储存实时分析的数据。
make btinit
The minimum requirement here is to create a targeting index in advance or the job will fail. We'd better not let beam/dataflow to do that.
Following steps are optional but you may need to plan ahead for best practices, especially for streaming jobs.
- Create an ES index template, so created index will share the same attributes (settings, mappings etc.)
- Create a Kibana index pattern for query those indices
- Create an ES index alias for ingestion, then rollover manualy or automatically
You could use the following scripts for above purposes, but remember to modify the init.sh accordingly for connection parameters.
跑初始化脚本前需要注意更新下面4个参数,分别是es的访问地址、kibana的访问地址、用户名和密码。
es_client=https://k8es.client.bindiego.com
kbn_host=https://k8na.bindiego.com
es_user=elastic
es_pass=<password>
Also, you should update ./scripts/elastic/index-raycom-template.json accordingly to define the index schema and settings.
初始化ES模版的目的是在注入数据的时候可能会根据时间去建立新的索引,这样他们都具备相同的属性了。那么Kibana里也可以通过同一个索引pattern进行查询。请根据需要设置./scripts/elastic/index-raycom-template.json来设置索引属性,然后到./scripts/elastic目录下运行./init.sh来完成初始化。
then run,
cd scripts/elastic
./init.shFinally, you may want to ingest data into different indices on a time basis, like hourly, daily or monthly. This could be controlled by using Index alias. So your dataflow job can only specify the name of the alias on start. Curator is the tool can automate this process or schedule your own jobs.
Let's do this manually in the Kibana Dev Tools UI
- Create an index for ingestion
PUT raycom-dataflow
- Create an index alias
POST /_aliases
{
"actions": [
{
"add": {
"index": "raycom-dataflow",
"alias": "raycom-dataflow-ingest"
}
}
]
}
- (Optional) Later you may want to ingest into a new index without updating the dataflow job, you could do this
POST /_aliases
{
"actions": [
{
"remove": {
"index": "raycom-dataflow",
"alias": "raycom-dataflow-ingest"
},
"add": {
"index": "raycom-dataflow-new",
"alias": "raycom-dataflow-ingest"
}
}
]
}
- (Optional) Alternatively, you could setup index lifecycle
PUT _ilm/policy/raycom_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "20GB",
"max_docs": 20000000,
"max_age": "7d"
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
You will need to update the index template
...
"index_patterns": ["raycom*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "raycom_policy",
"index.lifecycle.rollover_alias": "raycom-dataflow-ingest"
}
...
PUT raycom-dataflow-000001
{
"aliases": {
"raycom-dataflow-ingest": { "is_write_index": true }
}
}
Other out of scope topics on Elastic best practices,
- Index Lifecycle Management
- Snapshots & Restore
- Elastic stack deployment: Auto scripts or Highly Recommended Elastic on k8s/GKE
This branch is focusing on streaming, so the sample subscribes messages from Pubsub. It's easy to switch to KafkaIO in beam. But the quickest way to produce some dummy data then send to Pubsub for fun is by using this project.
If you use the GCP Play Ground to produce the pubsub message, there isn't much to do. Simply update the run shell script, make sure you have the corresponding permissions to manipulate the GCP resources.
Double check the paramters passed to the job trigger in makefile, then,
make df
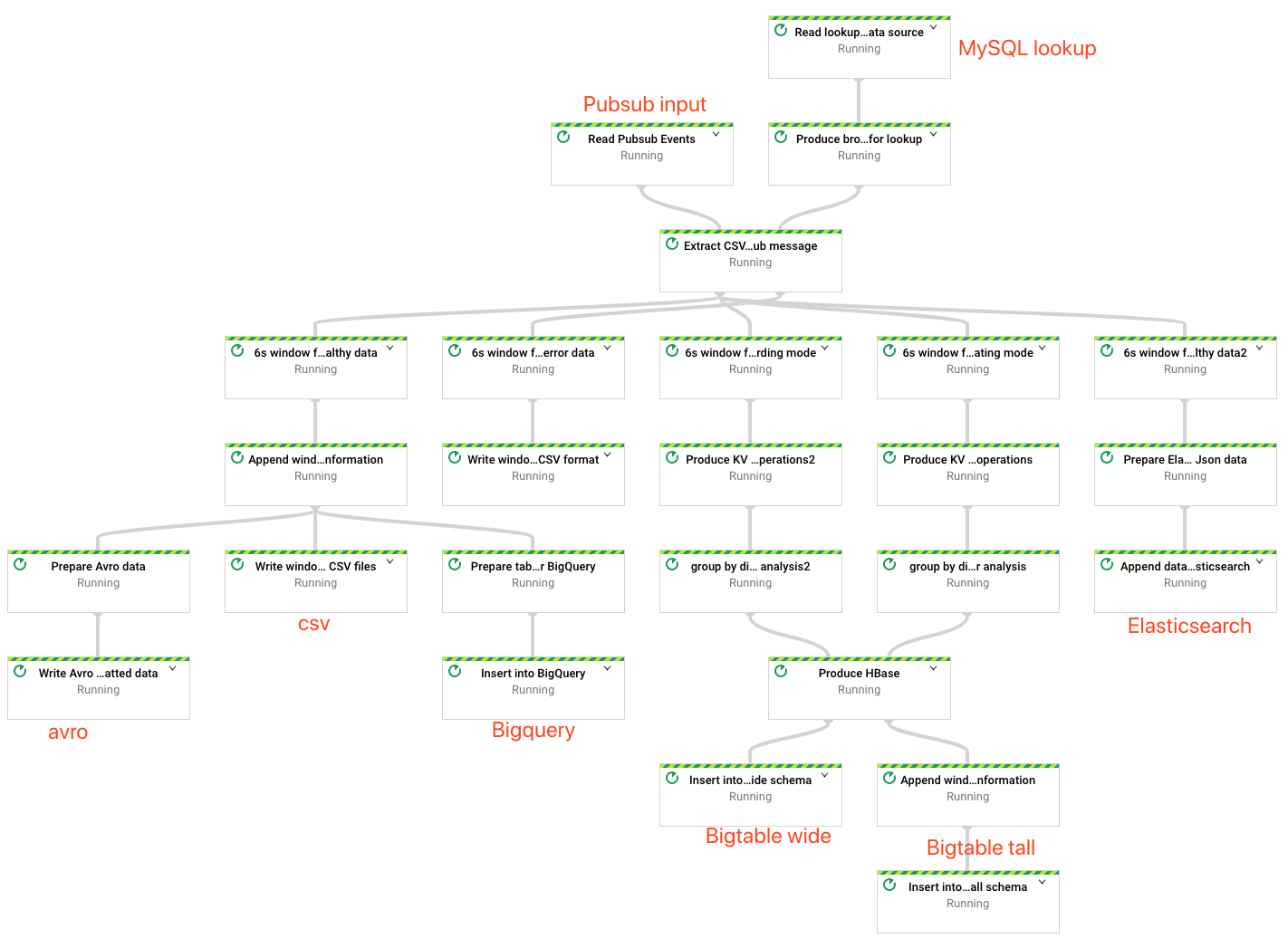
The purpose of this project is only to show you how to quickly run a streaming pipeline in Dataflow and the concepts about windowing, triggers & watermark. Even though the running cluster is elastic, you'd better break this big DAG into smaller pipelines and use Pubsub(or Kafka) as a 'communication bus' for better computing resources utilization and easy/faster recovery. Also, there are ways you could improve the performance, i.e. csv data handling etc. It's not the purpose of this example.
这里的代码示例主要为了说明beam的工作原理(触发器、窗口、水印等等)和一般实时+线下adhoc数据分析的一个大体框架。虽然Dataflow引擎可以动态伸缩,如果其他不能动态伸缩的引擎,就更需要把这个大的DAG拆分成一些小的管道,使用发布/订阅引擎作为数据交换媒介。这样维护起来比较清晰,更能提高计算资源的利用率,还在出错的时候相对快的恢复(暴力重跑啥的)。当然,数据处理的效率还有很多优化空间,大家要根据具体场景去做,因为没有唯一标准答案,也就不在这里下功夫了。
- Do I need to setup the BigQuery table in advance?
A: No. The application will create for you, and append to existing table by default.
- How to control the permissions?
A: This project is currently relying on the service account specified by the GOOGLE_APPLICATION_CREDENTIALS environment variable. Consult here for details.
- More details for triggers?
A: Hope this example explained triggers well.
- The DAG is too complicated?
A: You will need to comment out the code blocks in the job code file to simplify it to get a really quick start. Or master branch could be another go :)
- Elasticsearch index alias cannot guarantee all data in a particular window falls into corresponding index during rotation.
A: This actually doesn't matter since you query multiple indices / index pattern anyway.