This project is to support Allcorrect Games with creating a machine learning model to help make predictions on game reviews in regards to localization.
Through testing various models on the dataset, the model that had the best performance overall was Keras bert-for-tf2 model. Below is a print out of the classification table of metrics to show results of classification of labels:
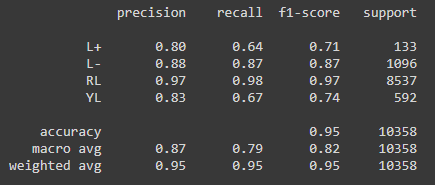
The python script application main.py incorporates the pre-trained Keras bert-for-tf2 model to make label predictions from a excel/csv file input by user. The output is the original excel file by user along with probabilites for the various labels. The required environment for the python script application can be found in requirements.txt and the pre-trained Keras bert-for-tf2 model is found in the releases secion. Please be aware that the python script should be updated on line 332 for the path file of the pre-trained model.
The company Allcorrect Games provides video game localization, localization testing, voiceovers, game art, and playable ads.
Allcorrect Group works with major international game publishers and developers. The company has participated in the localization of over 968 games, as well as the testing of over 100 games. Allcorrect Group works in more than 23 language pairs, partners with 6 voice studios, and employs highly competent native speakers to test games on the iOS, Android, and PC platforms.
The company uses players' reviews from different sources (Google Play, AppStore, etc.) to find games with high localization demand. This information is used to generate business offers from the company to game developers.
During reviews' analysis each of them is manually classified into several different categories. For instance, a review contains localization request or a user complains about translation mistakes, etc. Manual labeling of reviews is tedious and expensive process.
Main assumption of this project is that labeling could be done automatically by machine learning algorithms.
Build an algorithm for classification of user reviews into one of the four categories. The quality of the algorithm should be evaluated using hold-out subset or cross-validation technique.
The dataset has a record of 58000 entries.
Each entry has:
id: Unique ID for record entrymark: Corresponding label/tag category for text review entryreview: Text review
The following are the unique mark category:
RL: localization requestL+: good/positive localizationL-: bad/negative localizationYL: localization exists
The following metrics will be used to evaluate the model based on the prediction for the four unique categories:
- Accuracy score
- Macro F1 score
Using a macro F1 score, a macro-average will calculate the F1 score independently for each category/class and then take the average (treating all classes equally).
To start, we had to pre-process the text data. To normalize the text, we lower-cased, removed digits and other special characters, expand contractions, and lemmatized words to noun base. There was a huge class imbalance within the data in regards to certain labels.
A few feature vectors were created using Count vectors, various levels of TF-IDF vectors, and then combination of Count vectors and TF-IDF vectors.
These feature vectors were tested in the following models: Logistic Regression, Random Forest Classifier, SVM Linear SVC, and CatBoost Classifier.
Using Logistic Regression as our base model all feature vectors were tested. We also tested SMOTE, over sampling minority and under sampling majority with Logistic Regression. Overall, trying to fix the class imbalance did not improve accuracy or F1 macro scores.
All models tested with created feature vectors had fairly similar accuracy and F1 Macro scores to our base Logistic Regression model. Hyper parameterization could have made some of the models better but the computational cost was a bit expensive with no guarantee of better results. The predictive power of these models was heavily influenced by the majority class.
The final model tested was a BERT Embeddings with TensorFlow 2 (bert-for-tf2) model (Keras Deep Learning). This model outperformed all the other models in regards to having highest accuracy and F1 macro score.