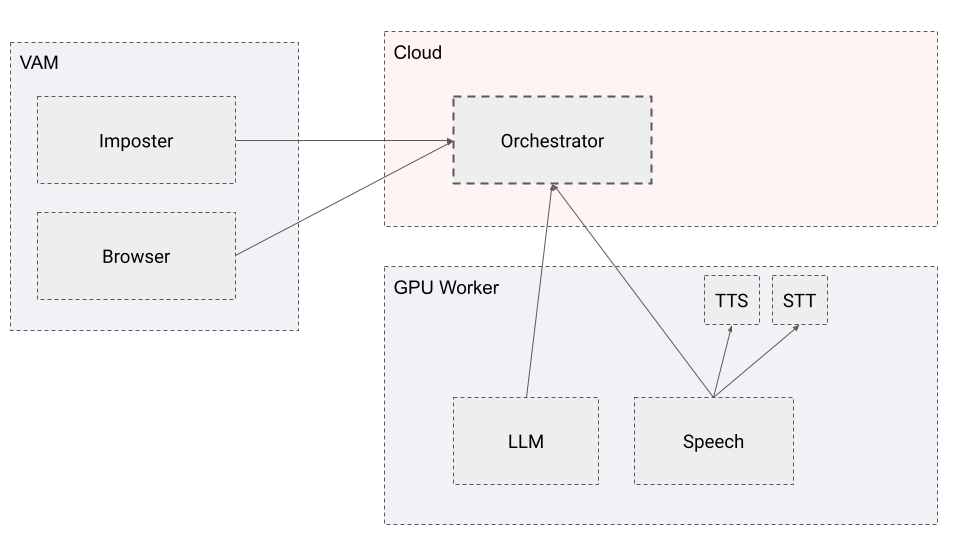
This is a node server that acts as an orchestrator between VAM, Speech and LLM server.
You need docker, conda and node installed first.
You need to run five servers: node server, TTS server, STT server, Speech server and LLM server. So prepare five terminals for those servers.
Inside the root folder of this repository, you can run
npm install
node server.js
First install conda: https://www.anaconda.com/download/
conda create --name imposter
conda activate imposterWindows/Linux:
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidiaIf you have any errors, please create a new conda environment and install Pytorch following this page: https://pytorch.org/get-started/locally/
cd LLM
pip install -r requirements.txtconda activate imposter
python run.pydocker run --rm -it -p 5002:5002 --gpus all -v /c/vosk:/root/.local/share/ --entrypoint /bin/bash ghcr.io/coqui-ai/tts:v0.11.1
python3 TTS/server/server.py --model_name tts_models/en/vctk/vits --use_cuda truedocker run --rm -it -p 5002:5002 --entrypoint /bin/bash ghcr.io/coqui-ai/tts-cpu:v0.11.1
python3 TTS/server/server.py --model_name tts_models/en/vctk/vits
Github repository: https://github.com/coqui-ai/TTS
docker run --rm --name=sepia-stt -p 20741:20741 -it sepia/stt-server:dynamic_v1.0.0_amd64Github repository: https://github.com/SEPIA-Framework/sepia-stt-server
node speech.js- @Acidbubbles for their perfect code template: https://github.com/acidbubbles/vam-plugin-template
- @VAMDeluxe for their amazing code.
- Hold the converstation history.
- Send and receive voice to VAM.
- Receive triggers (events) from VAM.
- Send actions to VAM.
- Story generation inside VAM.
- Use open source LLM for completion.
- Use Coqui tts for speech generation.
- Use Sepia stt for speech recognition.
- Use stories providers.
- Voice muxer with background noise, laughs, ...
- No refactoring.
- Open an issue before a PR.
- Multiple actors.
- Use embeddings for history.
- Support multiple languages.